1-800-805-5783
1-800-805-5783 GET A QUOTE
GET A QUOTE

Keeping applications up to date is essential in the ever-changing world of software development. However, traditional deployment methods have a big problem: they typically cause downtime. Here’s where rolling updates and rollbacks with Docker emerge as game-changers.
The Downtime Dilemma:
Consider a scenario where a crucial Docker application experiences downtime during a deployment. This can result in frustrated users, lost revenue, and reputational damage. Traditional deployment methods, where the entire application is stopped and replaced with a new version, often lead to this undesirable downtime window.
Rolling Updates to the Rescue:
Docker, the widely used container orchestration platform, introduces a significantly better approach: rolling updates. Rolling updates gradually replace outdated container instances with new ones running the updated application code. This staged rollout offers a host of compelling benefits:
- Experience the Ease: With rolling updates, the dread of downtime is significantly reduced. As updates occur incrementally, a substantial part of your application remains accessible to users, ensuring a near-seamless user experience with minimal disruption.
- Reduced Risk: By rolling out the update in stages, you can identify and address any potential issues with the new version before it fully replaces the old one. This minimizes the risk of widespread application failures compared to traditional all-or-nothing deployments.
- Improved Application Availability: By minimizing downtime and offering a rollback mechanism (more on that later), rolling updates ensure your application remains highly available to users, even during updates.
Performing Rolling Updates with Docker:
Implementing rolling updates with Docker is a straightforward process. Here’s a step-by-step breakdown:
- PrerDockertes: Ensure you have Docker Engine running and a containerized application deployed as a service.
- Initiate the Update: Deploy a new container image containing the desired application updates.
- Gradual Replacement: Utilize the docker service update command to gradually instruct Docker to replace existing containers with the new image—thisDockerns in a controlled manner, one container at a time.
- Monitor and Verify: Use the docker service ps command to track the update’s progress. Once all containers are updated, perform a final health check to ensure everything functions as expected.
Rollback: A Safety Net for Unexpected Issues
Confidence in Control: Even with the most meticulous planning, unforeseen issues can surface during an update. This is where Docker’s rollback feature becomes your safety net. Docker offers rollback capabilities, empowering you to revert to the previous version of your application if necessary, ensuring your control and security.
There are two primary rollback strategies:
- Manual Rollback involves stopping the updated service and restarting the previous version using Docker commands. While effective, it’s a more time-consuming approach.
- Automatic Rollback: Docker allows you to configure automatic rollbacks using the—-rollback option with the docker service update command. This triggers an automatic rollback if the updated service fails a health check or encounters errors.
Be Informed, Be Prepared: Understanding and implementing best practices for effective rolling updates is crucial. It ensures that you are well-informed and prepared to handle any situation that may arise during the update process.
- Health Checks: Implement health checks within your containers to ensure new versions function correctly before scaling down old ones.
- Update Strategy: Define the rate at which new containers are introduced (e.g., update a specific number of containers at a time or a percentage of the total).
- Monitoring: Closely monitor the update process using Docker commands or visualization tools to identify errors or performance issues.

Demystifying Rolling Updates:
Traditional deployment methods, with their tendency to take applications offline for updates, often lead to dreaded downtime. Rolling updates, a revolutionary approach, aim to solve this problem. They ensure seamless application evolution with minimal disruption, making them a game-changer in application management.
The Core Concept:
Consider a scenario where a popular website is undergoing updates. Instead of the entire platform going offline, rolling updates are implemented. New sections of the website’s code are gradually deployed and activated while existing ones continue to serve users.
This user-centric approach ensures that users experience minimal disruption or downtime while updates are implemented, giving them a sense of control and empowerment.
Rolling updates offer a phased approach to application updates, bringing several key advantages. They minimize downtime, reduce the risk of application failures, and provide a controlled rollout for monitoring and rollbacks. These benefits make rolling updates a highly effective and efficient strategy for managing application updates.
- Minimized Downtime: Unlike traditional deployments where the entire application is unavailable, rolling updates ensure a significant portion remains accessible throughout the process. Users experience minimal disruption, and ongoing sessions are rarely impacted.
- Reduced risk of widespread application failures: Consider rolling updates as a test drive for your new version. By introducing the update in stages, you can closely monitor its behavior and identify potential issues.
This controlled rollout significantly reduces the risk of widespread application failures, instilling a sense of security and confidence in your update process compared to deploying the update to all users simultaneously. - Controlled Rollout for Monitoring and Rollbacks: Rolling updates empower you to manage the update process with greater control. You can monitor the health and performance of the new version as it’s rolled out to a subset of users. This allows for quick identification of problems and initiating a rollback if necessary.
Beyond the Basics:
While the core concept of rolling updates is straightforward, there are additional considerations for effective implementation:
- Update Strategy: Define the rate at which new container instances are introduced. This could involve updating a specific number of containers at a time or a percentage of the total.
- Health Checks: Implement health checks within your containers to verify that the new versions function correctly before scaling down old ones.
- Monitoring: Vigilantly monitor the update process using Docker commands or visualization tools to identify errors or performance issues. This active monitoring ensures you are always in control of the update process, giving you reassurance and confidence in the system’s performance.

Implementing Rolling Updates with Docker
Rolling updates with Docker offer a compelling solution. They enable you to update your containerized applications while minimizing disruption seamlessly.
Prerequisites for a Smooth Rollout:
Before embarking on your rolling update journey, ensure you have the following in place:
- Docker Engine: The foundation for container orchestration. Ensure you have a functioning Docker Engine installed on your system.
- Containerized Application: Your application needs to be containerized and deployed as a service using Docker. Familiarity with Docker commands like run, ps, and stop will help navigate the process.
The Rolling Update Rundown:
Now, let’s delve into the steps involved in implementing a rolling update with Docker:
- Deploy the Update Image: Begin by deploying a new container image containing the application updates you wish to introduce. This image can be built using Dockerfile or pulled from a container registry.
- Gradual Replacement with docker service update: Here’s where the magic happens. Utilize the docker service update command, the service name, and the path to your new image. This command instructs Docker to gradually replace the existing container instances with the latest image, one container at a time.
- Monitor the Update Progress: As the update progresses, you can leverage the docker service ps command to track the status of your containers. This command displays information about running and stopped containers, allowing you to monitor the rollout in real-time.
- Final Verification and Health Checks: Once all containers have been replaced with the new version, perform a final health check to ensure everything functions as expected. This might involve running specific tests or verifying application logs.

Rollbacks: A Safety Net for Unexpected Issues
Even the most meticulously planned rolling updates can encounter unexpected issues. This is where rollbacks, the unsung heroes of the deployment world, come into play. They act as a safety net, providing security and allowing you to revert to a previous, stable version of your application if the update introduces problems.
The Importance of Rollback Mechanisms:
Envision releases an updated version of your software only to find a severe defect that interferes with user experience. Without a rollback option, you must quickly address the problem in the updated version while your application is down. With rollbacks, you may immediately return to the working version of the system, reducing user impact and downtime.
Docker’s Rollback Strategies:
Thankfully, Docker provides two primary rollback strategies to address such situations:
- Manual Rollback: This approach involves manually stopping the updated service using the docker service stop command.
Next, you’d leverage the docker service update command with the previous image version to restart the service with the known-good version. While effective, manual rollbacks can be time-consuming, especially for large deployments. - Automatic Rollback: A more automated and efficient approach uses the docker service update command with the—-rollback option.
- This option instructs Docker to automatically revert to the previous version if the updated service fails a health check or encounters errors during deployment. Thus, you can ensure a swift recovery in case of issues without manual intervention.
Best Practices for Seamless Rollbacks:
To ensure smooth and successful rollbacks, consider these best practices:
- Maintain Previous Image Versions: After a successful update, it’s crucial to remember to delete old image versions. These versions serve as a critical backup for rollback purposes, facilitating seamless rollbacks if the new update introduces problems.
- Implement Automated Rollback Triggers: Configure Docker to automatically trigger rollbacks based on health check failures or predefined error conditions. This minimizes downtime and ensures a swift recovery without requiring manual intervention.
Real-World Victories and Industry Insights
Rolling updates with Docker offer a compelling approach to application deployments, but what happens when things go awry? This section dives into real-world examples, lessons learned, and industry best practices to guide you through potential roadblocks and ensure successful rollbacks.
A. Real-World Victories: Success Stories of Rolling Updates with Docker Rollbacks
- E-commerce Giant Streamlines Updates
Netflix, the world’s leading streaming entertainment service with over 220 million subscribers globally, leverages rolling updates with Docker to deploy application updates frequently with minimal downtime. Here’s how they achieve success:
- Meticulous Planning: Updates, including comprehensive testing in staging environments, are thoroughly planned.
- Health Checks: They implement health checks within their containers to monitor functionality during the update.
- Automated Rollbacks: Docker’s automatic rollback capabilities are configured to trigger based on failing health checks, minimizing downtime in case of issues.
This approach ensures a smooth user experience for millions by minimizing downtime and rapidly reverting to a stable version if necessary.
- Fintech Startup Ensures High Availability
Robinhood, a pioneering financial services company with over 22 million users, relies on high availability for its stock and cryptocurrency trading application. They utilize Docker and embrace rollbacks for the following reasons:
- Manual Rollbacks as a Safety Net: They leverage manual rollbacks as a safety net. If unforeseen issues arise during an update, they can quickly revert to a stable version, minimizing disruption to critical financial transactions.
- Reduced Downtime: Rolling updates with the ability to rollback ensures the application remains available to users for most of the update process.
B. Lessons Learned:
- Testing is Paramount: It is crucial to extensively test the new application version in a staging environment before deploying it to production. This helps identify and address potential issues before they impact real users, reducing the need for rollbacks.
- Communication is Key: Clear communication with stakeholders throughout the update process is essential. Inform users about upcoming updates and potential downtime windows to manage expectations. Additionally, having a rollback plan and communicating it to the team ensures everyone is on the same page in case of issues.
By incorporating these lessons and best practices, you can emulate the success stories presented and ensure seamless application deployments with Docker and rollbacks.
Real-world Data
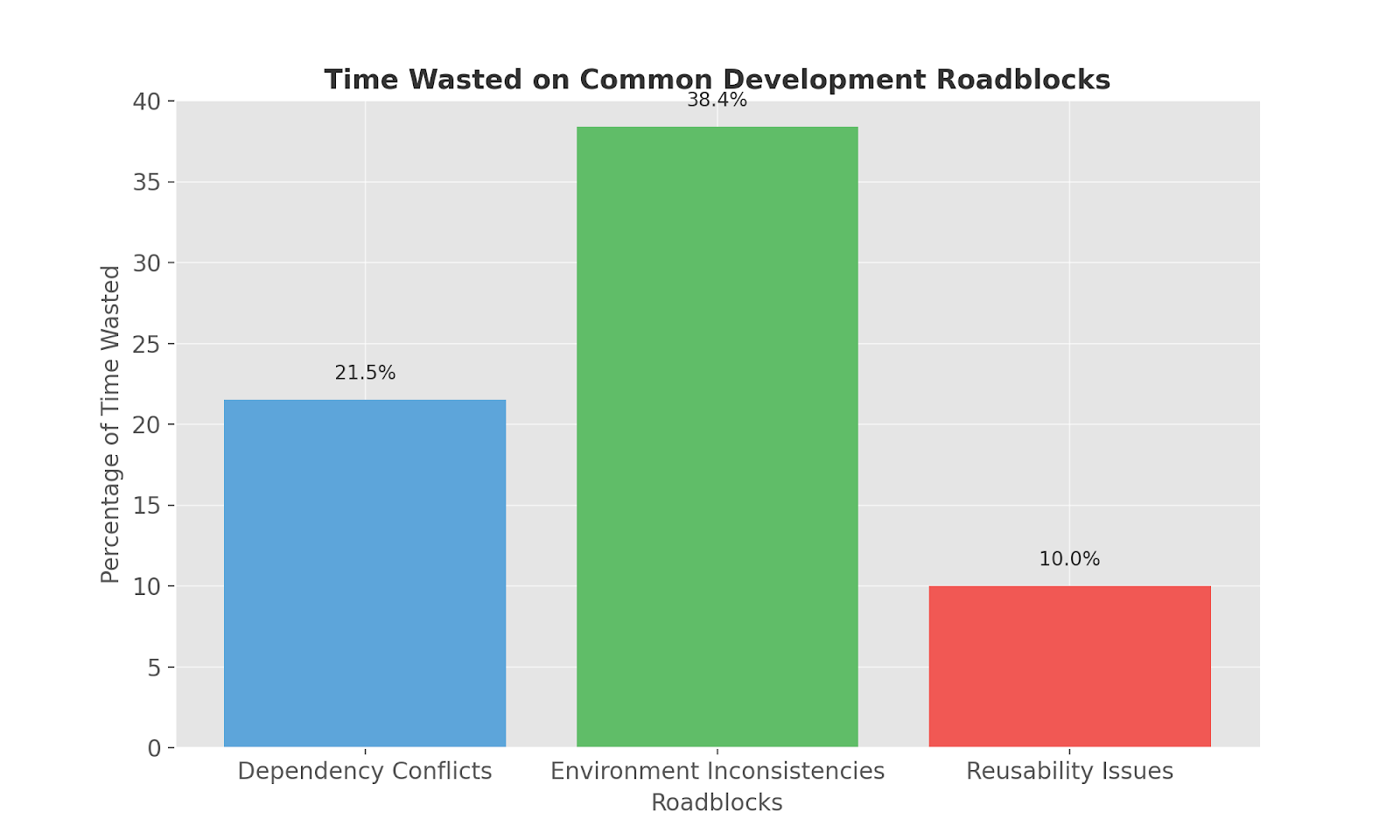
Reduced Downtime:
- A study by Gremlin indicates that unplanned downtime costs businesses an average of $5,600 per minute (as of 2023).
Improved Application Availability:
- A survey by Dynatrace reveals that 71% of businesses consider application availability a critical factor for business success.
Faster Deployment Cycles:
- According to the State of DevOps 2022 Report by GitLab, high-performing DevOps teams deploy code 208 times more frequently on average than lower performers.
Enhanced User Experience:
- A Salesforce report highlights that 73% of customers say a company’s customer service experience impacts their buying decisions.
Conclusion
In conclusion, implementing rolling updates and rollbacks with Docker is necessary. It is a powerful tool that empowers IT professionals and software developers.
It ensures the agility, reliability, and resilience of containerized environments, giving them the control to respond swiftly to changing business requirements and streamline their software deployment processes.
Rolling updates are not just about seamlessly deploying new features and updates; they catalyze innovation and competitiveness. They accelerate time-to-market, enhance customer satisfaction, and deliver a consistent and up-to-date user experience. They empower organizations to iterate rapidly, gather feedback, and iterate further, driving innovation and competitiveness in today’s fast-paced digital landscape.
However, the ability to roll back updates is equally crucial in mitigating risks and ensuring system stability. Rollbacks provide a robust safety net, allowing organizations to revert to a previous state in case of issues or unforeseen challenges during deployment.
This capability minimizes downtime, reduces the impact of disruptions, and safeguards business continuity, ultimately bolstering the reliability and resilience of containerized applications.
As Docker continues to evolve and innovate, organizations must remain vigilant in implementing best practices for rolling updates and rollbacks. This includes investing in automation tools like Jenkins or Kubernetes, monitoring tools like Prometheus or Grafana, and testing capabilities like Selenium or JUnit to streamline deployment processes, detect issues early, and facilitate swift remediation when needed.
By embracing a culture of continuous improvement and leveraging Docker‘s capabilities to their fullest extent, organizations can unlock the full potential of rolling updates and rollbacks, driving efficiency, agility, and innovation in their software delivery pipelines.
How can [x]cube LABS Help?
[x]cube LABS’s teams of product owners and experts have worked with global brands such as Panini, Mann+Hummel, tradeMONSTER, and others to deliver over 950 successful digital products, resulting in the creation of new digital revenue lines and entirely new businesses. With over 30 global product design and development awards, [x]cube LABS has established itself among global enterprises’ top digital transformation partners.
Why work with [x]cube LABS?
- Founder-led engineering teams:
Our co-founders and tech architects are deeply involved in projects and are unafraid to get their hands dirty.
- Deep technical leadership:
Our tech leaders have spent decades solving complex technical problems. Having them on your project is like instantly plugging into thousands of person-hours of real-life experience.
- Stringent induction and training:
We are obsessed with crafting top-quality products. We hire only the best hands-on talent. We train them like Navy Seals to meet our standards of software craftsmanship.
- Next-gen processes and tools:
Eye on the puck. We constantly research and stay up-to-speed with the best technology has to offer.
- DevOps excellence:
Our CI/CD tools ensure strict quality checks to ensure the code in your project is top-notch.
Contact us to discuss your digital innovation plans, and our experts would be happy to schedule a free consultation.