[x]cube LABS is a leading digital strategy and solution provider specializing in enterprise mobility space. Over the years, we have delivered numerous digital innovations and mobile solutions, creating over $ 2 billion for startups and enterprises. Broad spectrum of services ranging from mobile app development to enterprise digital strategy makes us the partner of choice for leading brands.
In today’s rapidly evolving digital landscape, cloud computing has emerged as a transformative force, revolutionizing how organizations operate and deliver services. With its ability to provide on-demand virtualized resources, cloud architecture offers unparalleled flexibility, scalability, and cost efficiency.
It is a key element that shapes and orchestrates the components and technologies required for cloud computing. This comprehensive guide will delve into the intricate world of cloud architecture, exploring its definition, components, benefits, and best practices.
Understanding Cloud Architecture
Cloud architecture is the blueprint that defines the layout and connectivity of various cloud technology components, such as hardware, virtual resources, software capabilities, and virtual network systems.
It is a guiding framework that strategically combines resources to build a cloud environment tailored to meet specific business needs.
Consider it the foundation upon which cloud-based applications and workloads are built and deployed.
Cloud architecture is a fusion of two architectural paradigms – Service-Oriented Architecture (SOA) and Event-Driven Architecture (EDA). It encompasses a range of components, including client infrastructure, applications, services, runtime cloud, storage, infrastructure, management, and security.
Each component plays a vital role in enabling seamless operation and delivery of cloud computing services.
The front end of cloud architecture represents the client-facing side of the cloud computing system. It comprises the user interfaces and applications that allow clients to access and interact with cloud computing services and resources.
The frontend acts as a gateway, providing a graphical user interface (GUI) that enables users to interact with the cloud seamlessly.
One crucial frontend component is the client infrastructure, encompassing the applications and user interfaces required to access the cloud platform.
It provides a user-friendly interface that empowers clients to leverage the full potential of cloud computing services. Whether accessing cloud-based applications through a web browser or utilizing specialized client software, the front end ensures a smooth and intuitive user experience.
Backend: Powering the Cloud
The backend of cloud architecture solutions refers to the cloud infrastructure itself, which cloud service providers utilize to deliver services to clients.
It encompasses a wide range of resources, management mechanisms, and security measures that enable cloud computing environments’ seamless operation and scalability.
One key component of the backend is the application, which refers to the software or platform that clients access to fulfill their specific requirements.
The application is the backbone of the cloud architecture, enabling the execution of tasks and the delivery of services. The service component is also crucial in managing and orchestrating various tasks and resources within the cloud environment.
It offers various services, including storage, application development environments, and web applications.
The runtime cloud provides the execution environment for services, acting as an operating system that handles the execution of service tasks and management.
It utilizes virtualization technology, such as hypervisors, to create a virtualized environment that hosts applications, servers, storage, and networking resources.
Storage is another essential backend component, providing flexible and scalable storage services for data and applications. Cloud storage options vary among providers, offering various solutions, including Amazon S3, Oracle Cloud Storage, and Microsoft Azure Storage.
These storage services are designed to handle vast data and ensure reliable and secure data management.
Infrastructure forms the backbone of the cloud architecture, encompassing both hardware and software components. It includes servers, storage devices, network devices, and virtualization software, which collectively power the cloud services.
The management component oversees and coordinates various aspects of the cloud environment, including application, task, security, and data storage management. It ensures seamless coordination and efficient allocation of cloud resources.
Security is critical to cloud architecture, providing robust measures to protect cloud resources, systems, files, and infrastructure. Cloud service providers implement various security mechanisms, such as virtual firewalls, data encryption, and access controls, to safeguard client data and ensure a secure cloud computing environment.
The internet acts as the bridge between the front and back end, facilitating communication and data transfer between these components. It ensures seamless connectivity and enables clients to access cloud services from anywhere in the world.
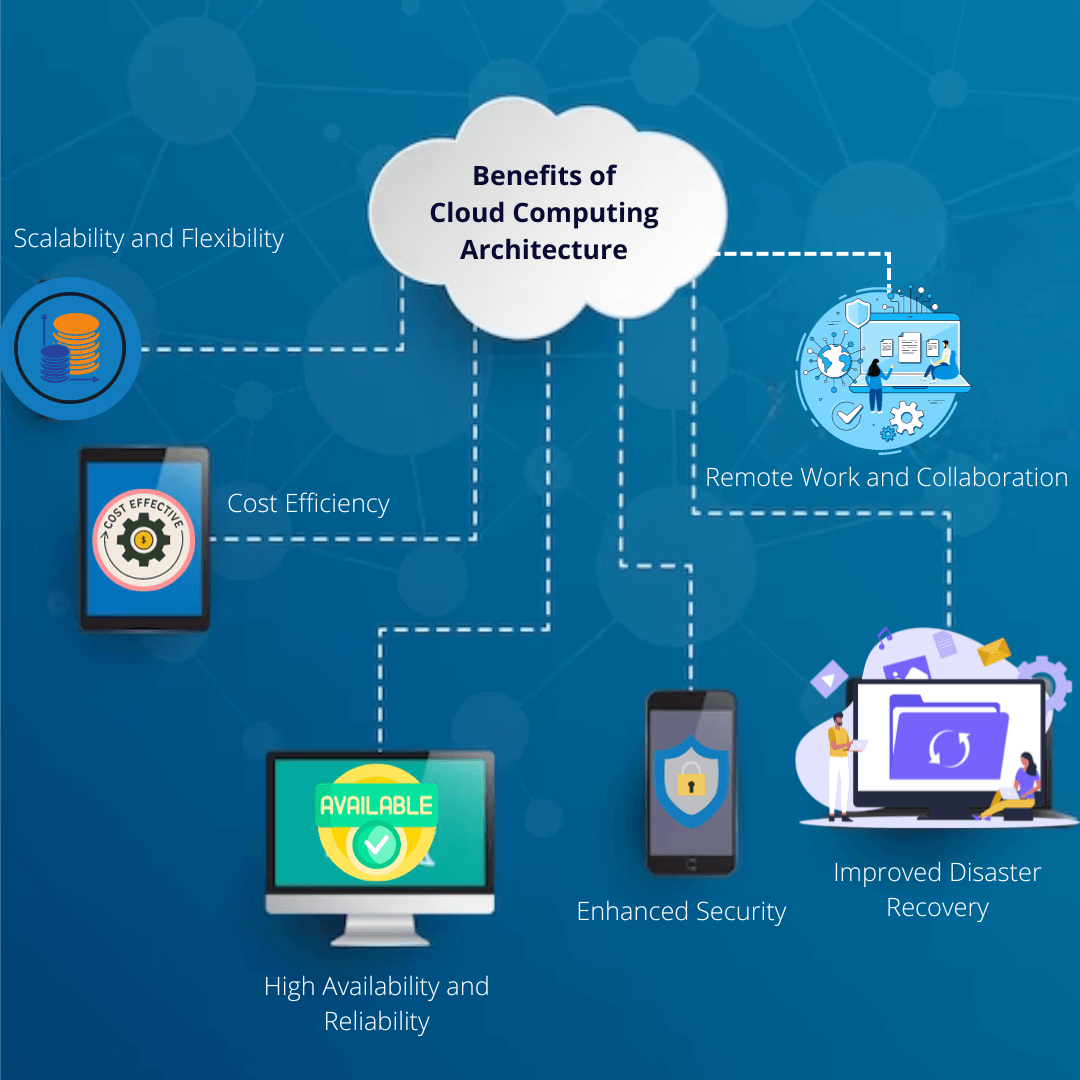
Benefits of Cloud Computing Architecture
Cloud computing architecture offers many benefits that empower organizations to achieve their goals efficiently and effectively. Let’s explore some of the key advantages of adopting cloud architecture:
Scalability and Flexibility
Cloud architecture provides organizations with unparalleled scalability and flexibility. By allowing businesses to scale computing resources up or down based on demand, they can easily accommodate fluctuating workloads and scale their operations accordingly.
This scalability ensures optimal resource utilization, eliminates the need for excessive hardware investments, and enables organizations to respond swiftly to changing market dynamics.
Cost Efficiency
One of the most significant advantages of cloud computing architecture is its cost efficiency. By leveraging the pay-as-you-go model, businesses only pay for the computing resources they consume, eliminating the need for upfront hardware investments and reducing operational costs.
Additionally, cloud architecture allows organizations to optimize resource allocation, ensuring that resources are utilized efficiently, further driving down costs.
High Availability and Reliability
Cloud architecture offers robust mechanisms that ensure the high availability and reliability of cloud services. With redundant infrastructure and failover systems, organizations can minimize downtime and ensure uninterrupted access to critical applications and data.
Cloud providers employ advanced monitoring and management tools to proactively identify and address potential issues, ensuring reliable service delivery.
Enhanced Security
Security is a paramount concern in today’s digital landscape, and cloud architecture provides robust security measures to protect sensitive data and ensure regulatory compliance. Cloud service providers employ advanced encryption techniques, access controls, and security protocols to safeguard client data from potential threats.
Additionally, cloud architecture enables organizations to leverage centralized security management tools, ensuring consistent security across the entire cloud environment.
Improved Disaster Recovery
Cloud architecture offers enhanced disaster recovery capabilities, enabling organizations to quickly recover from unforeseen events like data breaches or natural disasters.
With built-in backup and replication mechanisms, data can be securely stored and replicated across geographically diverse locations, ensuring data resilience and minimizing the risk of data loss.
Organizations can quickly restore operations and minimize downtime in a disaster, ensuring business continuity.
Remote Work and Collaboration
Cloud architecture enables remote work and collaboration, allowing teams to access and collaborate on projects from anywhere in the world. By leveraging cloud-based applications and services, organizations can foster a remote work culture, enabling increased productivity, flexibility, and collaboration among team members.
Cloud architecture empowers organizations to build virtual workspaces, enabling seamless communication and collaboration, irrespective of physical location.
Organizations should adhere to best practices that ensure optimal performance and efficiency to fully leverage the advantages of cloud computing architecture. Here are some key best practices to consider:
1. Comprehensive Assessment
Before embarking on cloud architecture design, conduct a comprehensive assessment of your organization’s current and future computing needs. Understand your requirements, workloads, scalability needs, and security considerations to choose the appropriate cloud deployment and service models.
2. Design for Resilience and Recovery
Build resiliency and recovery capabilities into your cloud architecture to ensure continuity in the face of disruptions. Implement redundancy, backup, and replication mechanisms to safeguard data and enable quick recovery during a disaster. Regularly test and update your disaster recovery plans to maintain their effectiveness.
3. Decoupling Applications
Decouple applications into a collection of services to increase scalability, performance, and cost efficiency. Adopt a microservices architecture that allows you to independently scale and manage individual components of your application, enabling agility and flexibility.
4. Optimize Data Storage
Optimize data storage costs, availability, performance, and scalability by employing vertical, horizontal, and functional data partitioning techniques. Leverage cloud storage services that offer flexible and scalable options, such as Amazon S3, Oracle Cloud Storage, and Microsoft Azure Storage.
5. Embrace Automation
Leverage automation to streamline and optimize your cloud architecture. Automate resource provisioning, deployment, and management processes to ensure efficient resource utilization and minimize manual intervention. Implement robust monitoring and alerting systems to identify and address potential issues proactively.
6. Implement Robust Security Measures
Security should be a top priority in cloud architecture design. Implement a multi-layered security approach that includes encryption, access controls, identity and access management, and regular security audits. Regularly update and patch your systems to protect against emerging threats.
7. Foster Cloud Visibility
Leverage cloud monitoring tools to gain comprehensive visibility into your cloud environment. Implement monitoring and logging mechanisms that provide insights into resource utilization, performance, and security. Use these insights to optimize resource allocation, detect anomalies, and ensure seamless operations.
8. Establish Governance and Compliance
Maintain consistent governance and compliance within your cloud environment. Establish policies, protocols, and accountability mechanisms to ensure regulatory compliance and adherence to industry standards. Regularly audit your cloud environment to identify and address any compliance gaps.
9. Cost Optimization
Regularly review and optimize your cloud costs to ensure efficient resource utilization and cost control. Leverage cost management tools provided by cloud service providers to analyze resource usage, identify cost-saving opportunities, and implement cost optimization strategies.
10. Continuous Learning and Improvement
Cloud architecture is an ever-evolving field, and organizations should foster a culture of continuous learning and improvement. Stay updated with the latest trends and technologies in cloud computing, explore new services and features offered by cloud providers, and continuously evaluate and refine your cloud architecture to meet evolving business needs.
Conclusion
Cloud architecture is the bedrock of modern software systems, enabling organizations to harness the full potential of cloud computing. By strategically designing and implementing cloud architecture, businesses can unlock the benefits of scalability, flexibility, cost efficiency, and security.
Adhering to best practices and continuously optimizing cloud architecture ensures optimal performance, resilience, and agility in a rapidly evolving digital landscape. Embrace cloud architecture as a catalyst for digital transformation and propel your organization towards innovation and success in the cloud era.
In the era of digital transformation, wearable technology in healthcare has emerged as a transformative force, revolutionizing how we monitor and manage our health. These innovative devices, often called wearable medical devices, have gained immense significance in recent years. In this brief overview, we will explore the growing importance of wearable technology in healthcare, showcase some notable examples, and highlight its role in enhancing the quality of medical care.
Introduction:
Wearable technology in healthcare, also known as wearables, represents a category of electronic devices that can be worn on the body as accessories or clothing. These devices are equipped with sensors and connectivity features that enable them to collect and transmit data related to the wearer’s health and activity.
The integration of wearable technology into healthcare has opened up new possibilities for proactive health monitoring, disease management, and improved patient outcomes.
Wearable Technology Examples:
Fitness Trackers: Fitness trackers like Fitbit and Garmin are the most recognizable examples of wearable technology. They monitor physical activity, heart rate, sleep patterns, and more, providing users valuable insights into their overall health and fitness.
Smartwatches: Modern smartwatches, like the Apple and Samsung Galaxy Watch, have evolved into powerful healthcare companions. They can track heart rate and ECG, detect falls, and even measure blood oxygen levels, enabling early detection of potential health issues.
Continuous Glucose Monitors (CGMs): For individuals with diabetes, wearable CGMs like Dexcom and Freestyle Libre have transformed glucose monitoring. They offer real-time data, reducing the need for painful fingerstick tests.
Wearable EKG Monitors: Devices like the KardiaMobile allow users to record EKGs on the go, aiding in the early detection of cardiac irregularities.
Wearable Sleep Monitors: Wearable devices like the Withings Sleep Analyzer can track sleep patterns, detect sleep disorders, and help improve sleep quality.
Wearable Medical Devices:
Many wearable technologies have evolved into medical-grade devices that provide healthcare professionals with valuable patient data. These wearable medical devices are increasingly used in clinical settings to monitor patients remotely, detect medical conditions earlier, and improve treatment outcomes. Examples include:
Wearable patches for continuous vital sign monitoring.
Bright clothing with embedded sensors.
Even wearable insulin pumps for diabetes management.
The growing significance of wearable technology in healthcare is undeniable. By seamlessly integrating data collection and analysis into our daily lives, wearables empower individuals to take charge of their health and well-being.
Moreover, healthcare providers can leverage this data to deliver more personalized and effective care, ultimately leading to better health outcomes and an enhanced quality of life for patients. As technology advances, we can expect wearable technology’s role in healthcare to expand even further, ushering in a new era of preventive and patient-centered medicine.
Benefits of Wearable Technology in Healthcare:
A. Improved Patient Engagement
1. Wearables encourage active involvement in health tracking
2. Enhanced patient-provider communication
B. Real-time Health Monitoring
1. Rapid detection of health issues
2. Timely interventions and prevention
C. Data Collection and Analysis
1. Gathering comprehensive health data
2. Utilizing big data for Healthcare Advancements
Future Trends in Wearable Technology
A. Advancements in Wearable Sensors
Miniaturization and Improved Accuracy: Wearable technology is shifting towards miniaturization, with sensors becoming smaller, more discreet, and increasingly accurate. This trend allows patients to comfortably wear these devices throughout the day, seamlessly collecting vital health data.
For instance, tiny, inconspicuous sensors embedded in clothing or accessories can now monitor heart rate and body temperature and even detect early signs of disease, providing continuous and precise insights into an individual’s health.
Example: Ultra-thin, skin-adhesive sensors that continuously monitor glucose levels for people with diabetes, ensuring real-time data accuracy without discomfort.
Expansion into New Medical Fields: Wearable technology is no longer confined to fitness tracking. It’s now penetrating various medical disciplines, including cardiology, neurology, and pulmonology. These devices can measure intricate physiological parameters, enabling early diagnosis and personalized treatment plans.
Example: Wearable ECG monitors that record and analyze heart rhythms, assisting cardiologists in identifying arrhythmias or heart abnormalities in their patients.
B. Artificial Intelligence and Machine Learning
AI-Driven Data Analysis: Integrating Artificial Intelligence and Machine Learning algorithms has empowered Wearable Medical Devices to process and interpret vast amounts of health data.
This enables the devices to identify real-time trends, anomalies, and potential health risks. AI-driven data analysis significantly enhances the accuracy and relevance of the information provided to patients and healthcare professionals.
Example: Smartwatches equipped with AI algorithms that analyze a user’s activity patterns and vital signs to detect subtle changes that may indicate the onset of a health issue.
Predictive Healthcare Insights: Wearable technology is becoming increasingly proactive by predicting health events before they occur. Based on historical data, AI algorithms can anticipate patient deterioration, helping healthcare providers intervene proactively and prevent emergencies.
Example: Wearable devices that predict asthma attacks by analyzing a patient’s breathing patterns and triggering alerts or medication recommendations when necessary.
C. Telemedicine and Remote Care
Wearables as a Key Component of Telehealth: The integration of Wearable Technology in Healthcare plays a pivotal role in expanding telemedicine. These devices serve as remote monitoring tools, allowing patients and healthcare providers to stay connected regardless of geographical distances. This enhances the accessibility of healthcare services, especially for those in remote areas or with chronic conditions.
Example: Remote patient monitoring systems that use wearable devices to track vital signs and share data with healthcare professionals in real-time for ongoing remote care.
Enhanced Remote Care Experiences: Wearables enrich the remote care experience by providing a comprehensive picture of a patient’s health over time. This data-driven approach allows healthcare providers to make informed decisions, offer personalized recommendations, and adjust treatment plans as needed.
Example: Wearable bright patches that track medication adherence and automatically notify healthcare providers if a patient misses a dose, ensuring seamless remote care management.
Conclusion:
In conclusion, wearable technology in healthcare has emerged as a transformative force, revolutionizing how we monitor and manage our health. This innovative field is teeming with incredible wearable technology examples pushing the boundaries of what’s possible in healthcare.
Wearable medical devices have evolved beyond just tracking steps and heart rate; they now have the potential to provide real-time, life-saving data and personalized insights for patients and healthcare professionals alike.
As we’ve explored throughout this blog, wearable technology in healthcare offers numerous benefits, from early disease detection to remote patient monitoring, and it is poised to play a pivotal role in the future of healthcare.
Integrating wearable devices into our daily lives promises improved patient outcomes, reduced healthcare costs, and a more proactive approach to healthcare management.
Whether it’s smartwatches, fitness trackers, or specialized wearable medical devices, the wearable technology landscape is continuously evolving, promising exciting innovations on the horizon. These advancements underscore the immense potential of wearable technology in healthcare, highlighting the importance of staying informed and embracing these technologies to lead healthier lives.
In a world where data is king, wearable healthcare technology empowers individuals and healthcare professionals with the insights they need to make informed decisions about their well-being.
As we look ahead, it’s clear that wearable technology in healthcare will continue to be a driving force in the quest for healthier, more connected lives. Embracing these wearable innovations can pave the way for a brighter, more health-conscious future.
So, whether you’re intrigued by the latest wearable technology examples or seeking solutions from wearable medical devices, the future of healthcare is undoubtedly intertwined with the promise of wearable technology. Stay informed, explore the possibilities, and make the most of these remarkable advancements for a healthier tomorrow.
The middle market has faced unprecedented challenges over the past several quarters, and the COVID-19 pandemic has significantly impacted businesses of all sizes. The National Center for the Middle Market (NCMM) has been monitoring the performance and sentiments of companies with annual revenues between $10 million and $1 billion since 2012. While average revenue growth for middle-market companies has increased in 2021, there is a clear divide in the recovery. While 45% of companies reported revenue growth of 10% or more, another 34% experienced flat or declining revenue.
The Split Recovery and Ongoing Challenges
The recovery has been uneven, with many companies still facing ongoing challenges. According to the NCMM, 51% of middle-market leaders cite employee communications, engagement, and productivity as the most difficult aspects of running their businesses in the current environment. Additionally, 45% reported issues with customer engagement. These challenges vary by industry, with healthcare companies struggling with employee engagement and construction companies finding it difficult to engage customers in new and beneficial ways.
The Importance of a Digital Vision for Middle Market Companies
Middle-market companies need a clear digital vision to thrive in the face of an uneven recovery and ongoing challenges. According to data from the NCMM, companies with a clear, comprehensive digital vision that guides strategic decisions grow 75% faster on average than their less digitally sophisticated peers. However, only 46% of middle-market companies have a digital roadmap built into their strategy.
The pandemic has accelerated investment in various technologies to address operational areas such as cybersecurity, customer engagement, and communications. However, executives’ perceptions of their own businesses’ digital maturity do not necessarily align with the investments made. While 52% of leaders consider digitization important or extremely important, only 35% consider themselves advanced or ahead of their peers.
A Framework for Digital Transformation for Middle Market Companies
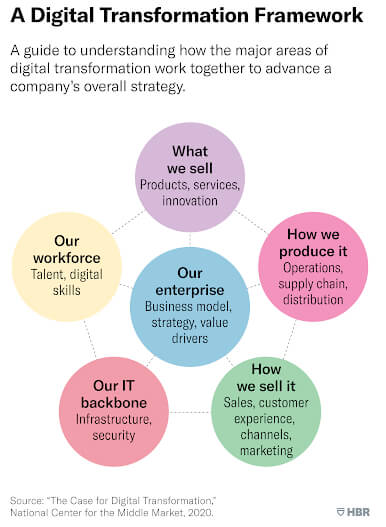
To help middle-market companies navigate the process of digital transformation, the NCMM has developed a framework that focuses on five interconnected activities:
What We Sell: Product and service offerings
How We Produce It: Supply chain, manufacturing, operations
How We Sell It: Customer experience, channels, marketing
Our IT Backbone: Infrastructure, security
Our Workforce: Talent, digital skills
This framework provides a guide for companies to assess and improve their digital maturity across these five fronts.
Let’s look at a couple of the biggest challenges faced by the middle market and how focusing on “how we sell it (customer engagement)” and “our workforce (employee engagement)” helps address them.
Customer Engagement across the Customer Journey
Regarding customer engagement, customer experience, lead generation, and marketing tools are top priorities for middle-market companies. To progress in these areas, companies should prioritize integrated multichannel marketing and sales, develop functional websites that connect customers with employees, increase online interaction through various digital touchpoints, and use technologies that support the sales force, such as CRM systems and social media. The goal is to create an omni-channel, end-to-end digital experience on all platforms and channels.
Employee Engagement
Middle-market companies face a challenge in accessing, attracting, and retaining talent with the right digital skills. To address this, companies should invest in people with specific digital expertise, adopt the latest technology and digital processes, take a strategic approach to realigning the workforce by contracting activities to outside specialists, and provide career training and development with clear career paths. Investing in employees with digital skills and empowering them with the right tools and processes is crucial for successful digital transformation.
Overcoming Obstacles
Resource constraints, budget issues, lack of time, and internal resources are common obstacles middle-market companies face when it comes to digital transformation. IT spending is often focused on daily operations and cybersecurity, leaving limited resources for digital transformation initiatives. Companies need to address these obstacles by prioritizing investments in digital technologies, allocating budgets and resources, and adopting a strategic approach to implementation.
Conclusion
Middle-market companies face unique challenges in the digital transformation journey. The key to thriving in an uneven recovery and overcoming ongoing challenges is to have a clear digital vision that guides strategic decisions. By focusing on customer and employee engagement, investing in the right digital technologies, and adopting a comprehensive framework for digital transformation, middle-market companies can position themselves for growth and success in the digital age.
This post is inspired by a similar topic in Harvard Business Review.
Automation is rapidly transforming healthcare, from AI-powered diagnostics and robotic surgery to automated patient scheduling and electronic health records.
The global healthcare automation market is projected to grow from about USD 42.6 billion in 2024 to over USD 100 billion by 2033–2034, with annual growth of 6–10%.
Hospitals are turning to automation to improve efficiency across clinical and administrative operations.
By streamlining documentation, accelerating diagnostics, and automating revenue cycle tasks, they reduce workloads and enable clinicians to prioritize patient care.
Automation in healthcare refers to the use of technology, including software, robotics, and Artificial Intelligence (AI), to perform tasks that were traditionally carried out by humans.
It is the digital assistant that takes over routine, repetitive, and rule-based work, allowing skilled medical professionals to focus their expertise on critical patient interactions and complex decision-making.
This technology encompasses a broad range, from simple automated email reminders to sophisticated AI algorithms used in diagnostics and Robotic Process Automation (RPA) tools in healthcare that manage back-office operations.
The Benefits of Automation in Healthcare
Automation in healthcare offers a wide range of benefits for both healthcare providers and patients. Let’s explore some of the key advantages:
Improved Efficiency and Productivity
One of the primary benefits of healthcare automation solutions is the improved efficiency and productivity it brings to medical practices.
By automating repetitive and time-consuming tasks, healthcare professionals can focus more on delivering quality care to patients.
For example, robotic process automation in healthcare can handle administrative tasks such as patient billing and scheduling, allowing staff to dedicate their time to more critical decision-making and leadership roles.
Automation in healthcare streamlines processes, enhances billing and revenue, and improves patient management, increasing efficiency and productivity in healthcare settings.
Enhanced Patient Safety
Medical errors can have serious consequences for patients and healthcare providers alike.
Automation in the healthcare sector helps reduce the potential for errors and improves patient safety.
For instance, using barcode medication administration (BCMA) systems in hospitals helps prevent medication errors by requiring nurses to scan a patient’s wristband and the medication’s barcode before administering it.
By leveraging automation technologies in healthcare, providers can minimize human errors and ensure safer and more accurate care delivery.
Better Access to Care
Automation in the healthcare industry plays a crucial role in improving access to healthcare, particularly in underserved areas.
Telemedicine, for example, enables remote clinical services by leveraging telecommunications and information technologies.
This allows people in rural or remote locations to consult with doctors in urban areas, expanding access to care for those who may have difficulty accessing traditional healthcare services.
Automation in healthcare helps bridge the gaps in access to care, ensuring that patients receive the medical attention they need, regardless of their geographical location.
By reducing manual processes and streamlining operations, healthcare facilities can save time and resources.
For example, automation can improve the accuracy and speed of billing processes, resulting in faster payment collections and reduced administrative costs.
Additionally, automation in the healthcare sector helps providers optimize resource allocation, track key performance indicators (KPIs), and make data-driven decisions that can lead to better financial outcomes.
Focus on Patient Care
One of the most critical benefits of automation in healthcare is its ability to combat professional burnout and reorient the focus of care.
Nurses and doctors often spend a significant amount of time on non-clinical duties like manual charting, paperwork, and administrative follow-ups.
By taking this immense administrative burden off the staff, automation in healthcare allows clinical personnel to dedicate more time to direct patient care.
This shift fosters better provider-patient relationships, allows for more compassionate and thorough interactions, and actively works to reduce the high rates of stress and burnout common in the medical field.
Automated Electronic Health Records (EHR) systems ensure that patient data is centrally updated, accurate, and instantly accessible across all departments, as well as to authorized providers outside the facility.
Robotic Process Automation (RPA) tools in healthcare can validate data as it is entered and automatically update records across disparate systems.
This seamless and accurate data exchange is crucial for facilitating better care coordination.
It allows specialists to have a complete patient history at their fingertips, leading to more informed and collaborative treatment decisions.
Clinics that automate front-office workflows often pair reminder protocols with scheduling platforms, such as SetTime, an online appointment scheduling system, to enable 24/7 self-booking and patient-initiated rescheduling from links in reminders; evidence shows text-message reminders increase attendance at healthcare appointments, and studies report lower no-show rates when patients self-schedule online versus by phone, so integrating reminders with self-scheduling directly targets preventable missed visits.
Applications of Automation in Healthcare
The applications of automation in healthcare are vast and varied. Let’s explore some of the key areas where automation in the healthcare sector is making a significant impact:
By automating these administrative tasks, healthcare providers can streamline workflows, improve billing accuracy, and enhance revenue management.
RPA in healthcare enables round-the-clock handling of claims, billing, and scheduling tasks, freeing staff to focus on more critical patient care responsibilities.
Additionally, automation can manage patient intake and scheduling, ensuring patients receive the care they need while optimizing practice operations.
Staff Support and Triage
Automation in the healthcare industry has been crucial in supporting healthcare staff, especially during challenging times like the COVID-19 pandemic.
Automated triage screening tools, such as hotlines and AI-powered chatbots, have been deployed to help assess and prioritize patient needs.
These tools allow patients to self-trace and provide valuable information, reducing the burden on nurses and staff. In some cases, trained AI tools have been used to identify pneumonia in COVID-19 patients, enabling early detection and timely intervention.
Automation in healthcare supports staff and helps prevent burnout, ensuring that healthcare professionals can deliver high-quality care.
Electronic Health Records (EHRs)
Adopting electronic health records (EHRs) mandated by the Affordable Care Act has transformed healthcare data management.
Automation in healthcare plays a crucial role in managing the massive amount of data stored in EHRs, enabling healthcare professionals to leverage actionable insights for improved care delivery.
Automated processes help collect, clean, and analyze patient data, allowing for a better understanding of patient populations, training AI applications, conducting research, and enhancing overall care quality.
Automation in healthcare facilitates efficient data management and empowers healthcare professionals with valuable information to make informed decisions.
Patient Communications and Engagement
Automation has revolutionized patient communications and engagement in healthcare.
Chatbots and AI-powered assistants enable providers to answer patient questions, schedule appointments, and conduct surveys.
Natural language processing (NLP) capabilities enable AI to interact with patients, analyze responses, and provide personalized care recommendations.
Automation in healthcare meets patients where they are, making it easier for them to access care and engage with their healthcare providers.
Automated appointment reminders, for example, help reduce no-shows and improve patient compliance, ultimately leading to better health outcomes.
Data Security and Blockchain
Data security is critical in healthcare, and automation in the healthcare industry is crucial in safeguarding sensitive medical and patient information.
Blockchain technology, combined with automation in healthcare, offers enhanced security and usability for healthcare leaders.
Blockchain uses encryption and other security measures to store and link data, ensuring data integrity and privacy.
With automation, healthcare organizations can leverage blockchain to securely store and share medical and patient data, gaining valuable insights for improving care and delivery.
Automation and blockchain together provide a robust framework for data security and enable healthcare leaders to harness the power of data for transformative outcomes.
Dashboard Analytics for Operational Efficiency
Healthcare administrators rely on measuring and improving operational efficiencies to optimize their organizations.
Healthcare dashboards are powerful tools that visually represent key performance indicators (KPIs) to help track and analyze data.
Automation in healthcare enables the creation of comprehensive dashboards that allow insurers to understand claims data, providers to visualize clinical data, and hospitals to track resource allocation.
Through automation, healthcare organizations can leverage advanced analytics and visualization techniques to gain valuable insights, make data-driven decisions, and continuously improve operational efficiencies.
Automation for Improving Patient Outcomes
Automation in healthcare holds immense potential for improving patient outcomes. Let’s explore some specific areas where automation is making a difference:
Reducing Medical Errors
Medical errors are a significant concern in healthcare, leading to preventable harm and costly consequences.
Automation in healthcare helps reduce the potential for medical errors by leveraging advanced technologies.
For example, AI applications can analyze electronic health record (EHR) data to flag unusual prescriptions, helping prevent medication errors.
By automating processes and utilizing AI insights, healthcare providers can improve patient safety, reduce errors, and enhance the overall quality of care.
Augmented Reality for Diagnoses and Procedures
Augmented reality (AR) is transforming how doctors diagnose and perform procedures.
By using 3D modeling and visualization, AR applications support doctors in making accurate diagnoses and performing complex procedures with greater precision.
AR tools, running on tablets and smartphones, make advanced medical technologies accessible to healthcare professionals, enhancing their capabilities and improving patient outcomes.
Automation in healthcare, combined with AR, enables medical practitioners to leverage cutting-edge technologies and revolutionize healthcare delivery.
Enhanced Clinical Decision Support and Diagnosis
Automation in healthcare has the potential to enhance clinical decision support and diagnosis.
Healthcare providers can leverage vast datasets to speed up research and improve diagnostic accuracy by leveraging AI and machine learning algorithms.
AI applications trained on massive amounts of data can assist doctors in making treatment decisions, augmenting their expertise rather than replacing it.
Automation empowers healthcare professionals with powerful tools for evidence-based practice, promoting better patient outcomes and more efficient healthcare delivery.
Internet of Things (IoT) for Remote Healthcare Delivery
The Internet of Things (IoT) has revolutionized remote healthcare delivery, enabling healthcare providers to monitor and deliver care outside traditional clinics or hospital settings.
Wearable medical devices, smartwatches, and remote monitoring tools collect real-time data on patients’ vital signs and symptoms, enabling early detection of illnesses and diseases.
Automation in healthcare enables the seamless gathering and analysis of IoT data, empowering healthcare leaders to make data-driven decisions and provide timely interventions.
By leveraging automation and IoT, healthcare organizations can extend care beyond physical boundaries and improve patient outcomes.
Intelligent Automation: The Future of Healthcare
The next evolutionary stage is Intelligent Automation (IA), which combines Robotic Process Automation (RPA) with advanced technologies like Artificial Intelligence (AI), Machine Learning (ML), and Natural Language Processing (NLP).
AI doesn’t just automate repetitive tasks, it learns, adapts, and makes complex decisions.
The strategic implementation of intelligent automation in healthcare is the path forward.
The future of healthcare will be characterized by:
Predictive Healthcare: ML algorithms will analyze vast datasets to predict disease outbreaks, anticipate patient admissions, and identify individuals at high risk for certain conditions, enabling proactive, preventive care.
Virtual Nursing Assistants: Sophisticated AI will serve as virtual health assistants for both patients and staff, handling preliminary triage, answering complex clinical questions, and optimizing workflow management in real-time.
Autonomous Operations: From fully automated clinical labs that prepare and analyze samples to self-managing supply chains that automatically order resources, IA will make healthcare operations highly resilient and efficient.
Examples of Healthcare Automation Solutions
Automation solutions in healthcare offer numerous opportunities to improve practice productivity and enhance patient experiences. Let’s explore some real-world examples of healthcare automation solutions:
By automatically sending reminders to patients about their upcoming appointments, providers can ensure that patients are well-informed and prepared for their visits.
Customizable messages and delivery preferences allow personalized communication, enhancing patient engagement and satisfaction.
Missed Appointment Notifications
Automation can help healthcare providers effectively address missed appointments.
Automated systems can send notifications to patients who have missed their appointments, allowing them to reschedule and receive the necessary care.
Patients can conveniently book appointments anytime by leveraging online scheduling capabilities, ensuring a seamless and efficient scheduling process.
Recalls and Follow-ups
Automated recall systems enable healthcare providers to track patients’ upcoming appointments and efficiently contact them for scheduling.
This automation eliminates the need for manual follow-ups, reducing administrative burden and improving patient satisfaction.
By automating the recall process, healthcare organizations can optimize their appointment management, ensuring patients receive timely care and follow-ups.
Patient Surveys for Feedback
Gathering patient feedback is essential for maintaining a patient-centric practice.
Automation streamlines the process by automatically sending surveys after each visit.
This eliminates the need for manual survey distribution and ensures consistent data collection.
Patient surveys provide valuable insights for improving care quality, enhancing patient satisfaction, and identifying areas for practice improvement.
Birthday Greetings and Patient Loyalty
Automation enables healthcare providers to send personalized birthday greetings to patients, fostering patient loyalty and strengthening relationships.
Instead of costly and time-consuming mailings, automated birthday greetings can be delivered electronically, ensuring that patients feel valued and appreciated.
This simple yet effective marketing strategy helps improve patient satisfaction and loyalty, ultimately leading to better patient retention.
Targeted Care Campaigns for Patient Education
Automation is instrumental in delivering targeted care campaigns to patients, providing them personalized health information and education.
Healthcare organizations can tailor educational materials to specific patient needs and health goals by leveraging automation tools.
Automated delivery of targeted care campaigns improves patient engagement, empowers patients to make informed decisions about their health, and enhances overall health outcomes.
Automated Revenue Cycle Management
Automation in revenue cycle management helps healthcare organizations optimize their financial processes and improve collections.
Automated systems reduce manual efforts in generating and sending multiple statements, leading to more consistent and efficient revenue management.
By streamlining the revenue cycle, healthcare providers can focus on patient care and reduce administrative burdens, ensuring a more efficient and profitable practice.
Conclusion
Automation in healthcare is transforming the future of medical services, revolutionizing how healthcare organizations operate and deliver care. From improving efficiency and productivity to enhancing patient safety and access to care, automation offers numerous benefits for healthcare providers and patients. By leveraging advanced technologies such as RPA, AI, and BPM, healthcare organizations can streamline operations, improve decision-making, and deliver personalized care experiences.
Real-world examples of healthcare automation solutions, such as appointment reminders, patient surveys, and targeted care campaigns, demonstrate the tangible impact of automation on practice productivity and patient satisfaction. As the healthcare industry continues to embrace automation, the possibilities for innovation and improved patient outcomes are boundless. Embrace the power of automation in healthcare and embark on a journey towards a more efficient, patient-centric future.
FAQs
1. Will automation replace doctors and nurses in the future?
No, automation is designed to support and assist, rather than replace, doctors and nurses. Managing repetitive tasks allows healthcare professionals to spend more time on complex decision-making and direct patient care, ensuring that personal interactions remain central.
2. How does automation specifically improve patient safety?
Automation can help minimize human error through systems such as Barcode Medication Administration (BCMA) and automated dosage alerts. These systems work alongside healthcare teams to promote accuracy in diagnostics and drug dispensing, contributing to safer care for patients.
3. What is Intelligent Automation (IA)?
Intelligent Automation is the combination of traditional Robotic Process Automation (RPA) with Artificial Intelligence (AI). This fusion allows systems not just to follow rules, but also to learn, adapt, and make complex, informed decisions.
4. What is the difference between RPA and AI in healthcare?
Robotic Process Automation (RPA) automates simple, rule-based tasks like data entry and scheduling. Artificial Intelligence (AI) uses complex algorithms for tasks requiring intelligence, such as diagnostics and predictive analytics.
How Can [x]cube LABS Help?
At [x]cube LABS, we craft intelligent AI agents that seamlessly integrate with your systems, enhancing efficiency and innovation:
Intelligent Virtual Assistants: Deploy AI-driven chatbots and voice assistants for 24/7 personalized customer support, streamlining service and reducing call center volume.
RPA Agents for Process Automation: Automate repetitive tasks like invoicing and compliance checks, minimizing errors and boosting operational efficiency.
Predictive Analytics & Decision-Making Agents: Utilize machine learning to forecast demand, optimize inventory, and provide real-time strategic insights.
Supply Chain & Logistics Multi-Agent Systems: Enhance supply chain efficiency by leveraging autonomous AI agents that manage inventory and dynamically adapt logistics operations.
Autonomous Cybersecurity Agents: Enhance security by autonomously detecting anomalies, responding to threats, and enforcing policies in real-time.
Generative AI & Content Creation Agents: Accelerate content production with AI-generated descriptions, visuals, and code, ensuring brand consistency and scalability.
Integrate our Agentic AI solutions to automate tasks, derive actionable insights, and deliver superior customer experiences effortlessly within your existing workflows.
For more information and to schedule a FREE demo, check out all our ready-to-deploy agents here.
In today’s fast-paced digital landscape, organizations constantly seek ways to optimize their software development processes for scalability, agility, and efficiency. One approach that has gained significant traction is the adoption of microservices architecture. This revolutionary architecture style allows businesses to break down their monolithic applications into smaller, independent services that can be developed, deployed, and scaled individually. This comprehensive guide will explore the intricacies of migrating from monolith to microservices architecture, its advantages, and the strategies to ensure a successful transition.
Understanding Monolith Architecture and Microservices
Before diving into the migration process, it is crucial to understand the fundamental differences between monolith architecture and microservices. A monolith architecture is characterized by a single code repository that houses all software modules, business logic, and data access. In contrast, microservices architecture distributes systems into independent components with specific functions, computing resources, and databases. These components, known as microservices, are loosely coupled and communicate with each other through application programming interfaces (APIs). By embracing microservices, organizations can achieve loose coupling, high cohesion, and scalability, enabling faster software system development, deployment, and maintenance.
Advantages of Microservices Architecture
Migrating from a monolithic architecture to microservices offers several significant advantages for businesses. These advantages include:
Business Flexibility
Microservices architecture provides bounded contexts between its independent components, making the system easily modifiable. It enables organizations to add, remove, or upgrade features with minimal effort, ensuring systems remain relevant and competitive in a rapidly evolving market.
Faster Deployment
Microservices code is more comprehensible as it is restricted to a single data repository. This clarity allows teams to understand dependencies better and anticipate outcomes when modifying the codebase. Consequently, testing becomes more consistent and coherent, saving time and resources in the upgrade process.
Increased Productivity
Well-defined boundaries and minimal dependencies in microservices architecture empower teams to implement, scale, and deploy multiple microservices simultaneously. Developers gain autonomy in choosing programming languages, frameworks, and APIs that align with their specific goals, ultimately enhancing productivity.
Fault Tolerance
Microservices architecture isolates code errors within individual microservices, preventing them from breaking the entire system. This fault tolerance ensures that failures in one microservice have minimal impact on the overall system’s stability and performance.
Scalability
Microservices offer granular scalability, allowing organizations to scale specific software modules based on their needs without affecting the rest of the application. This flexibility in scaling computing resources leads to improved performance and cost efficiency.
While the advantages of microservices architecture make it an appealing choice for many organizations, it is important to evaluate when migration is necessary and appropriate carefully.
When to Migrate from Monolith to Microservices
While microservices architecture offers numerous benefits, it is not always the optimal solution for every organization. Before embarking on the migration journey, it is crucial to assess the following factors:
Performance Deterioration and Development Difficulties
If developing new features or managing your monolithic application is becoming increasingly challenging, migrating to a microservices architecture can provide a solution. Microservices offer better system management and a clearer development process, enabling faster software delivery.
Low Fault Tolerance
Microservices architecture can be advantageous in scenarios where fault tolerance is critical. Even if one microservice experiences an issue, the rest of the system can continue functioning, ensuring uninterrupted service for end-users. However, it is essential to consider the potential risks and consequences of displaying incorrect data when system parts are down.
Towering Infrastructure Costs
Microservices architecture provides enhanced infrastructure scalability compared to monolithic applications. Organizations only pay for their capacity with microservices, optimizing infrastructure costs and resource allocation.
Partial Scalability Requirements
When specific system components require additional resources while others operate below capacity, microservices architecture allows for partial scalability. Unlike monolithic applications, microservices enable organizations to allocate resources precisely where needed, resulting in improved performance and resource utilization.
Team Structure and Autonomy
In complex solutions, it is common for engineering teams to form subteams responsible for specific parts of the application. If these teams rarely interact with each other and operate independently, migrating to microservices architecture can provide a more streamlined and autonomous workflow for each team.
It is essential to thoroughly evaluate these factors to determine if migrating to a microservices architecture is the right choice for your organization. Once the decision to migrate is made, following the right strategies and best practices is crucial for a successful transition.
Strategies for Migrating from Monolith to Microservices
Migrating from a monolithic architecture to microservices requires a carefully planned and executed strategy. There are two primary strategies to consider:
Implement New Functionality as Services
One effective approach is to begin migration by implementing significant new functionalities as separate services. This strategy allows organizations to experience the benefits of microservices architecture while gradually transforming the monolithic application.
By implementing new functionalities as services, organizations can demonstrate the value and efficiency of microservices to stakeholders. Additionally, this approach enables teams to gain familiarity with microservices development, deployment, and management processes.
Extract Services from the Monolith
The ultimate goal of migrating to a microservices architecture is to eliminate the monolithic application entirely. To achieve this, organizations must incrementally extract modules from the monolith and convert them into standalone services.
This process involves carefully identifying modules within the monolith that can be extracted and converted into microservices. By understanding each module’s dependencies and responsibilities, organizations can determine the most effective approach to extracting and refactoring them into independent services.
The extraction process should be gradual and systematic, ensuring that the extracted services retain their functionality and seamlessly communicate with other services. The Strangler Application pattern, as described by Martin Fowler, is a recommended approach for incrementally replacing parts of the monolith with microservices.
Steps for a Successful Microservice Architecture Migration
It is essential to follow a well-defined roadmap to ensure a smooth and successful migration from monolith to microservices architecture. Here are the key steps to consider:
1. Clearly Define Goals and Alignment
Before initiating the migration process, define the goals and objectives of adopting a microservices architecture. Ensure that all stakeholders are aligned and understand the benefits and expected outcomes. It is crucial to have a unified vision and commitment to the migration process.
2. Conduct a Comprehensive Architectural Analysis
Engage a software architect to conduct a detailed analysis of the existing monolithic architecture. Identify dependencies between different components and assess the feasibility of separating these elements into microservices. This analysis will provide insights into the complexity of the migration process and help estimate the required resources.
3. Plan and Prioritize the Work
Create a detailed plan for the migration process, considering the dependencies and priorities of different modules. Identify and prioritize the modules that can be extracted and converted into microservices based on business criticality, scalability requirements, and dependencies.
4. Allocate Adequate Time and Resources
Ensure that sufficient time and resources are allocated to the migration process. Avoid treating the migration as a secondary task and involve the entire team. Developers responsible for specific code sections should take ownership of the respective microservices, enabling better coordination and accountability.
5. Optimize Team Workflow and Workload Allocation
Reorganize the development team to optimize workflow and workload distribution. Establish a system of principal engineers, each responsible for a limited number of microservices. This approach fosters a sense of ownership, reduces confusion, and streamlines the development process. Avoid overloading principal engineers with too many microservices to maintain effectiveness.
6. Implement Continuous Integration and Deployment
Adopt continuous integration (CI) and continuous deployment (CD) practices to ensure efficient microservice development and deployment. Implement automation tools and processes to streamline the software delivery pipeline, reduce manual efforts, and enhance efficiency.
Carefully plan the transition of data and databases from the monolithic application to microservices. Analyze database mappings and identify tables or objects that can be mapped to individual microservices. Consider data synchronization, transactional integrity, and latency issues when splitting the monolithic database.
8. Monitor, Test, and Refine
Continuously monitor the performance and stability of the microservices architecture. Implement robust testing practices to identify and address any issues or bottlenecks. Regularly refine the architecture based on real-world usage and feedback to ensure optimal performance and scalability.
9. Foster a Culture of Collaboration and Learning
Promote collaboration and knowledge sharing among teams working on different microservices. Encourage a culture of continuous learning and improvement, enabling developers to explore new technologies and best practices. Regularly conduct code reviews, knowledge-sharing sessions, and retrospectives to foster growth and innovation.
10. Measure and Evaluate Success
Define key performance indicators (KPIs) and metrics to measure the success of the migration process. Evaluate the impact of microservices architecture on software delivery speed, scalability, fault tolerance, and customer satisfaction. Use these insights to refine the architecture further and drive continuous improvement.
Migrating from monolith to microservices architecture is a complex but highly rewarding process. By embracing microservices, organizations can unlock the power of scalability, agility, and efficiency in software development. However, it is essential to carefully evaluate the need for migration and adopt the right strategies for a successful transition. With a well-defined roadmap, meticulous planning, and a commitment to continuous improvement, organizations can harness the true potential of microservices architecture and drive digital innovation in their industry.
In today’s rapidly evolving digital landscape, effective product design is crucial for businesses looking to stay competitive and meet the ever-changing needs of their customers. Whether it’s developing a mobile app, designing a website, or creating a user-friendly software interface, product design principles and approaches play a vital role in crafting successful digital products.
The Importance of Product Design
Product design goes beyond aesthetics and encompasses the entire user experience, from the initial idea to the final implementation. It involves understanding user needs, identifying market opportunities, and creating solutions that provide value and solve problems. Effective product design becomes even more critical in the digital realm, where technology and user expectations constantly evolve.
The Role of Design Thinking
Design thinking, a human-centric approach to innovation, is the foundation for the product design process. It integrates people’s needs, technology’s possibilities, and business success requirements. Design thinking allows designers to better understand users, empathize with their needs, define the problem, generate creative solutions, prototype and test ideas, and iterate based on user feedback.
The Design Thinking Process
The design thinking process consists of several key phases:
Empathize: Gain a deep understanding of the people you are designing for by conducting user research and interviews. This step helps uncover user needs, pain points, and goals.
Define: Based on the insights gathered during the empathize phase, define a clear problem statement and user personas. This step ensures a focused and user-centered approach to the design process.
Ideate: Brainstorm and generate various creative solutions to address the defined problem. Encourage collaboration and open-mindedness to explore different possibilities.
Prototype: Build low-fidelity prototypes of the proposed solutions to visualize and test ideas. Prototyping helps identify potential flaws and gather valuable feedback before investing significant resources.
Test: Test the prototypes with users to validate assumptions, gather feedback, and refine the design. User testing provides insights into how well the proposed solutions meet user needs and expectations.
By following the design thinking process, designers can approach product design with a user-centric mindset, resulting in products that are more intuitive, functional, and aligned with user expectations.
The Design Process
The product design and development process is a series of steps that product teams follow while developing a digital product. While the specific steps may vary depending on the project, the overall flow typically includes the following:
Define the Product Vision: Defining the product vision and strategy is essential before starting the design process. This involves setting clear goals, understanding the target audience, and establishing the product’s purpose and value.
Product Research: Conduct user and market research to understand user needs, behaviors, and preferences. This research helps inform the design decisions and ensures a user-centered approach.
User Analysis: Analyze the research findings to create user personas and identify key user behaviors and pain points. This step helps designers understand the target audience and tailor the product to their needs.
Ideation: Generate various ideas and concepts based on the research and user analysis. Encourage creativity and collaboration to explore different possibilities.
Design: Translate the selected ideas into visual designs and interactive prototypes. This step involves creating wireframes, user interfaces, and interactive elements to bring the product to life.
Testing and Validation: Test the design with real users to gather feedback and validate the effectiveness of the design. This step helps identify any usability issues or areas for improvement.
Post-launch Activities: After launching the product, continuously monitor and gather user feedback. Use this feedback to make iterative improvements and enhance the user experience.
Collaboration and communication between designers, developers, and stakeholders are crucial throughout the product design process to ensure a cohesive and successful product.
The Future of Digital Product Design
As technology advances, the future of digital product design holds exciting possibilities. Emerging trends such as artificial intelligence, voice user interfaces, and virtual and augmented reality are reshaping how users interact with digital products.
Designers must stay abreast of these trends and incorporate them into their design processes. However, it’s important to remember that modern product design trends do not exist in isolation. Instead, they build upon the foundations of past innovations and technological developments.
Trends and shifts in design philosophies:
1. Accessibility Takes Center Stage: Accessibility and inclusive design became a top priority, ensuring digital products cater to diverse user needs and abilities.
2. Minimalism Reimagined: Minimalism remained popular but evolved to focus on creating clear, usable interfaces while incorporating subtle details for user engagement.
3. Microinteractions Gain Attention: Small, purposeful interactions within interfaces gained focus, enhancing user experience and emotional connection.
4. Human-Centered Design Reigns Supreme: The emphasis on understanding user needs and emotions through research and iteration remained fundamental.
Technological Advancements and Emerging Trends:
1. AI-powered Design Tools: AI tools gained traction, assisting with tasks like layout generation, user flow optimization, and personalization.
2. Conversational UI Boom: Chatbots and voice assistants continued to evolve, offering more natural and intuitive interactions with digital products.
3. 3D Design Integration: 3D design tools became more accessible, creating more prosperous and immersive user experiences.
4. Augmented Reality (AR) & Virtual Reality (VR) Experiences: Continued growth in AR/VR applications across various fields, like product visualization and training.
5. Data-driven Design Decisions: Leveraging data analytics to inform design choices and personalization has become increasingly important.
6. Focus on Ethical Design: Considerations for responsible data practices, user privacy, and unbiased algorithms gained prominence.
Significant developments and trends in digital design and user experience:
1. Dark Mode Preference: Users increasingly prefer dark mode options in digital interfaces for their aesthetic appeal and potential benefits like reduced eye strain, especially in low-light environments. Dark mode also caters to accessibility needs for users with sensitivity to bright light or vision impairments.
2. Sustainable Design Practices: There’s a growing emphasis on designing digital products with eco-friendly principles. This involves using sustainable materials, minimizing energy consumption, and optimizing resource efficiency throughout the product lifecycle.
3. Motion Design & Microanimations: Digital interfaces continue to incorporate subtle animations and micro-interactions to improve user engagement and enhance the overall experience. These animations serve functional purposes, such as providing feedback, guiding users through interactions, and adding visual interest and delight.
4. Personalization & Customization: Offering personalized experiences based on user preferences and behavior has become a key trend in digital design. By tailoring content, recommendations, and interactions to individual users, companies can enhance engagement, foster customer loyalty, and improve overall satisfaction.
Conclusion
Effective digital product design is a multifaceted discipline that requires a deep understanding of user needs, market opportunities, and the latest design trends. By following the principles of design thinking and adhering to a well-defined product design process, designers can create products that are not only visually appealing but also functional, intuitive, and aligned with user expectations.
As the digital landscape continues to evolve, businesses must prioritize effective product design to provide exceptional user experiences and maintain a competitive edge in the market. By embracing an innovative and customer-centric approach to digital product design, businesses can drive growth, enhance customer satisfaction, and achieve their strategic goals.
The healthcare industry is transforming remarkably, driven by technological advancements and a growing demand for personalized patient experiences. Augmented Reality (AR) has emerged as a powerful tool in healthcare, potentially revolutionizing various aspects of medical practice, from surgical procedures to patient education and diagnosis. By integrating digital content into the real world, AR in healthcare is reshaping how services are delivered, improving efficiency, accuracy, and overall patient care.
AR Surgery: Enhancing Precision and Visualization
One of the most significant applications of AR in healthcare is in surgical procedures. Surgeons can now wear AR headsets, allowing them to visualize critical information without detaching from the task at hand. By superimposing computer-generated imagery onto the real-world view, AR enables surgeons to see patient imagery, such as CT scans, in real time during the operation. This technology gives surgeons precise guidance and enhances their ability to make accurate decisions, improving surgical outcomes. Additionally, AR combined with AI software can process vast amounts of data and provide on-the-fly diagnoses or procedural suggestions directly in the surgeon’s field of view.
Medical Visualization: Enhancing Patient Care Beyond the Operating Room
Augmented reality in the medical field has given rise to AR tools developed to superimpose visuals on patients, enhancing the delivery of safer and more efficient care beyond the operating room. For example, nursing staff can use AR overlays to easily identify the right vein when administering medicine, reducing the need for trial and error. This not only improves patient comfort but also minimizes the risk of complications. Furthermore, AR can help patients visualize their bodies, understand their conditions, and gain insights into specific procedures. By personalizing the patient experience with AI, healthcare providers can tailor visualizations to individual health data, empowering patients to take an active role in their own care.
Improved Patient Diagnosis: AR as a Diagnostic Aid
AR in healthcare plays a crucial role in improving patient diagnosis, particularly when verbal descriptions are inadequate. Patients often struggle to accurately describe their symptoms, leading to delays in diagnosis and treatment. AR can help bridge this communication gap by allowing patients to visually compare their symptoms to different skin conditions or experience various eye conditions. This visual aid enhances the patient’s ability to accurately describe their concerns to healthcare providers, leading to more timely and accurate diagnoses.
Pain Management: AR for Therapeutic Purposes
AR, along with its counterpart, Virtual Reality (VR), has proven to be effective in pain management. Patients can be immersed in therapeutic environments controlled by healthcare professionals, distracting from pain and promoting relaxation. The FDA has already approved VR-based systems that use cognitive behavioral therapy to help patients cope with chronic pain. Similarly, AR can be used during physical therapy sessions to minimize discomfort and improve patient engagement. By integrating data on the patient’s specific pain, AI can personalize the pain management experience, optimizing treatment outcomes.
Immersive Training: AR for Healthcare Education
AR in healthcare has become invaluable for healthcare education and training. Medical students and professionals can explore the human body, practice procedures, and learn new techniques in virtualized environments resembling real-world scenarios. AI technology enhances these training experiences by providing real-time feedback and adapting the virtual environment based on user actions. This interactive and immersive learning approach facilitates a deeper understanding of complex medical concepts and prepares healthcare professionals for real-world practice. Furthermore, AR in healthcare allows for remote collaboration, enabling students in a classroom to observe and learn from their peers wearing AR glasses.
The Vast Potential of AR in Healthcare
While we have only scratched the surface of what AR and AI can accomplish in healthcare, the possibilities for future innovations are immense. AR and AI have the potential to transform healthcare delivery, from improving surgical precision and patient education to enhancing diagnostics and pain management. The integration of AR technology with online collaboration tools enables healthcare professionals to consult with each other remotely, providing guidance and support even when physically distant. Pharmaceutical and genomics companies can leverage AR and AI to visualize, analyze, and develop new drugs, viruses, and therapies, opening new medical research and development frontiers.
To fully harness the benefits of AR in healthcare, organizations must invest in education and training to familiarize medical staff with AR-supported tools. Implementing small-scale pilot projects can help mitigate the fear of change and ensure that healthcare providers stay up-to-date with the evolving AR industry. By embracing AR and AI, healthcare organizations can enhance patient care, improve efficiency, and pave the way for a healthier future.
Conclusion
Augmented Reality (AR) is revolutionizing the healthcare industry, providing unprecedented opportunities to improve patient care, enhance surgical procedures, and transform medical training. Integrating AR technology with AI enables healthcare professionals to visualize critical information, personalize patient experiences, and make more accurate diagnoses. From surgical visualization and patient education to pain management and immersive training, the applications of AR in healthcare are diverse and promising. While challenges such as the cost of AR products and data security concerns remain, the potential benefits outweigh the obstacles. The global market for AR in healthcare is projected to experience significant growth in the coming years, driven by increased adoption, investments, and technological advancements. As the healthcare industry continues to embrace digital transformation, AR will play a vital role in shaping the future of medicine, delivering better, safer, and more personalized care to patients worldwide.
In today’s rapidly advancing digital age, the healthcare industry is transforming toward smart hospitals. With the increasing complexity of healthcare needs and the strain on resources, hospitals are embracing innovative technologies to improve patient care, enhance operational efficiency, and meet the demands of a changing world. This article explores the concept of smart hospitals, their key features, and the benefits they offer to patients, healthcare providers, and the overall healthcare ecosystem.
Understanding Smart Hospitals
Smart hospitals are at the forefront of the e-health revolution, leveraging cutting-edge technologies to optimize and automate healthcare processes. At the heart of this transformation is the Internet of Things (IoT), which connects medical devices, data analysis, and artificial intelligence (AI) to improve patient care. By integrating smart technologies into their operations, hospitals can streamline workflows, reduce human error, and enhance the overall quality of care.
Harnessing the Power of Smart Technology
One notable example of a smart hospital is Humber River Valley Hospital in Canada. As North America’s first fully digital hospital, Humber River Valley Hospital utilizes smart technologies to automate back-office services such as pharmacy, laundry, and food delivery. By automating these labor-intensive tasks, clinical staff have more time to focus on providing personalized patient care, ultimately improving patient outcomes. Similarly, Cleveland Clinic Abu Dhabi (CCAD) in the UAE leverages digital apps to enhance patient treatments. Patients can communicate with staff through apps, access their medical information and daily plans via smart pads, and even order food directly through the app. This seamless integration of technology throughout the patient journey improves convenience, efficiency, and overall patient satisfaction.
Addressing Labor Shortages with Smart Solutions
One of the significant challenges faced by the healthcare industry is a shortage of healthcare professionals. The World Health Organization (WHO) estimates that over 18 million healthcare professionals will be short-staffed globally within the next decade. Smart hospital technology offers a potential solution to this problem by automating processes and utilizing robotics to assist healthcare providers.
During the COVID-19 pandemic, Wuhan Hospital in China relied on robots provided by CloudMinds Technology to carry out essential tasks, providing much-needed respite for over-stretched healthcare workers. By automating traditionally labor-intensive processes, smart hospitals enable healthcare professionals to focus on delivering high-quality care, even in the face of workforce shortages.
Revolutionizing Healthcare with 3D Printing
One of the emerging technologies in smart hospitals is 3D printing. While still in its early stages, 3D printing holds immense potential for revolutionizing healthcare. Imagine a future where surgical teams can print prosthetic limbs or dental implants on-demand, offering personalized solutions for needy patients. Researchers from the University of Minnesota have already made promising advancements by creating silicon-made scaffolding for spinal cord injuries. This innovative approach allows for the printing of cells onto the structure, which can then be implanted into the patient’s spinal cord, restoring muscle control.
The Shift Towards Patient-Centric Care
Patient expectations are evolving, and healthcare providers must adapt accordingly. The rise of the informed patient, fueled by increased access to information and digital devices, has led to a demand for more personalized and patient-centric care. Smart hospitals cater to this shift by leveraging technology to enhance the patient experience. Through the use of wearable devices and remote-sensing technologies, patients can actively participate in their own healthcare. Real-time monitoring of vital signs and continuous communication with healthcare providers enable early intervention and better management of chronic conditions. By empowering patients with information and fostering a collaborative approach to care, smart hospitals are revolutionizing the patient experience.
The Importance of Data Connectivity
Smart hospitals are part of an interconnected healthcare ecosystem where data sharing and connectivity are vital. Smart hospital solutions ensure seamless information exchange between healthcare providers, payers, and government agencies by integrating personal health records, electronic health record systems, and other data sources. This comprehensive data connectivity enables healthcare professionals to make informed decisions, enhances care coordination, and improves patient outcomes.
Ensuring Cybersecurity in Smart Hospitals
While the benefits of smart hospitals are clear, addressing the associated cybersecurity risks is crucial. Integrating technology and connectivity in healthcare systems opens up vulnerabilities that malicious actors can exploit. Protecting sensitive patient information, medical records, and critical infrastructure is paramount.
Hospital data and equipment are attractive targets for hackers and criminal groups. Traditional medical devices may not have been designed with security, leaving them vulnerable to cyberattacks. Malicious attacks, such as malware blitzes and ransomware, pose significant threats to the integrity and privacy of patient data. Human errors, such as misconfigurations of medical devices, can also have dire consequences.
Ongoing collaboration between technologists and healthcare practitioners is crucial to mitigate these risks. Cybersecurity measures should be integrated into the design and implementation of smart hospital systems. Regular assessments, employee training, and robust security protocols are essential to protect patient information and ensure the reliability of smart hospital operations.
The Future of Healthcare: Embracing Smart Hospitals
As healthcare needs evolve, the transformation towards smart hospitals becomes increasingly crucial. These innovative healthcare facilities leverage technology to deliver more efficient, patient-centric care. By harnessing the power of smart technology, hospitals can streamline workflows, address labor shortages, enhance the patient experience, and improve overall healthcare outcomes.
The journey towards smart hospitals requires significant investment and collaboration between stakeholders. It necessitates a radical redesign of processes, integration of technology, and a shift towards data-driven decision-making. By embracing this digital transformation, healthcare providers can meet the challenges of a changing world and deliver the precise care that patients need and deserve.
In conclusion, smart hospitals represent the future of healthcare. By leveraging technology, connectivity, and automation, these innovative healthcare facilities provide a roadmap for delivering high-quality care in an increasingly complex and demanding world. Smart hospitals’ benefits extend beyond the facility’s walls, influencing the entire healthcare ecosystem. As the world evolves, embracing smart hospitals is not just an option but a necessity.
Technology makes incredible strides in transforming how medical professionals provide care and how patients receive it in the ever-changing healthcare scene. The application of robotics in healthcare is at the vanguard of this digital revolution, a game-changing development drastically transforming the medical industry.
Robotics has become a valuable tool for medical professionals with the promise to improve accuracy, expedite procedures, and even push the limits of what is possible in medicine.
Robotics in healthcare refers to integrating advanced medical robot technologies and systems into medical and healthcare settings to assist in various tasks, procedures, and functions related to patient care, diagnosis, treatment, and rehabilitation.
These medical robotic systems can range from simple automated tools to highly complex and sophisticated machines designed to work collaboratively with healthcare professionals or independently.
To optimize robotics’ significance in healthcare, continuous research and development must be prioritized, focusing on refining robotic technologies for excellent safety, interoperability, and user-friendliness.
Regulatory frameworks should be established to ensure ethical use and patient safety, while collaborations between engineers, healthcare professionals, and patients can drive innovations that address specific healthcare challenges effectively.
This article examines medical robots’ crucial place in contemporary medical designs and discusses their uses, advantages, and bright future for patients and medical professionals.
Applications of Robotics in Healthcare
Optimizing robotics applications in healthcare involves leveraging robotic technology to enhance various aspects of medical care, improving efficiency, accuracy, and patient outcomes.
Surgery and Minimally Invasive Procedures: Medical robotic-assisted surgery enables precise and minimally invasive procedures. Optimizations could include advancements in surgical robotics for complex surgeries, such as cardiac or neurological procedures, to enhance surgeon dexterity and visualization.
Rehabilitation and Physical Therapy: Medical robotic devices aid rehabilitation and physical therapy by providing targeted exercises and assisting patients with mobility challenges. Optimization efforts might focus on creating personalized therapy plans and refining the design of robotic devices for better patient engagement.
Telemedicine and Remote Care: Robotic telepresence allows doctors to interact with patients and perform routine check-ups remotely. Optimizations could involve improving the interface, audiovisual quality, and mobility of telemedicine robots to enhance the remote healthcare experience.
Diagnostic Imaging and Radiology: Medical Robots can automate taking and analyzing diagnostic images. Optimizations in this area include refining the accuracy of robotic imaging systems and integrating AI for more precise diagnosis.
Laboratory Automation: Robotic systems can handle repetitive laboratory tasks like sample processing and testing. Optimizations may involve increasing the throughput and accuracy of these systems, allowing researchers to focus on data analysis.
Pharmacy and Medication Management: Robotic systems can assist in dispensing medications and managing pharmacy inventory. Optimizations could focus on reducing medication errors, streamlining prescription fulfillment, and improving medication tracking.
Patient Assistance and Elderly Care: Medical Robots can provide companionship and assistance to elderly patients. Optimizations include enhancing the robots’ communication abilities, monitoring capabilities, and adaptability to different patient needs.
Emergency Response and Disaster Management: Medical robotic platforms can be used in disaster scenarios to locate survivors and provide medical aid. Optimizations could involve improving the robots’ mobility, communication, and durability in harsh environments.
Drug Delivery: Medical robotic systems can assist in precise drug delivery, especially when accurate dosing is critical. Optimizations may include refining the technology for controlled drug release and targeted treatments.
Patient Monitoring: Medical robotic devices can continuously monitor patients’ vital signs and alert healthcare providers to any concerning changes. Optimizations might focus on integrating AI algorithms for more accurate early detection of abnormalities.
Benefits of Integrating Medical Robots in Healthcare
A. Enhanced Precision and Accuracy
B. Reduced Human Error and Risk
C. Improved Patient Outcomes
D. Increased Efficiency in Procedures
Challenges and Considerations
A. Initial Implementation Costs:
Initial Implementation Costs are the expenses associated with setting up and integrating an organization’s new system, technology, or process. These costs encompass investments in hardware, software, infrastructure, and any necessary adjustments to existing workflows. Optimizing for the keyword “Initial Implementation Costs.”
B. Training and Skill Development:
Training and Skill Development enhance individuals’ knowledge, competencies, and abilities to effectively carry out tasks and responsibilities. This often involves structured learning programs, workshops, and hands-on experiences to improve expertise. Optimizing for the keyword “Training and Skill Development.”
C. Ethical and Legal Concerns:
Ethical and Legal Concerns encompass the moral and legal considerations surrounding specific actions, technologies, or practices. It involves addressing potential dilemmas, conflicts, and compliance issues in various contexts, such as business, technology, or healthcare. Optimizing for the keyword “Ethical and Legal Concerns.”
D. Patient Acceptance and Trust:
Patient Acceptance and Trust refer to individuals’ willingness to embrace and rely on new medical treatments, technologies, or procedures. They encompass building confidence and support between healthcare providers, patients, and the innovations introduced to ensure successful adoption.
Current Trends and Future Prospects
A. Artificial Intelligence in Robotic Healthcare:
Explore the seamless fusion of artificial intelligence and robotics in healthcare, revolutionizing patient care and medical procedures. Witness how AI-driven robots enhance diagnostics, surgical precision, and treatment effectiveness through advanced algorithms and machine learning.
B. Telemedicine and Remote Robotic Surgeries:
Delve into telemedicine and its cutting-edge application in remote robotic surgeries. Discover how surgeons operate across geographical boundaries using automated systems, leveraging real-time communication and high-tech interfaces to provide expert medical care to patients worldwide.
C. Personalized Treatment through Medical Robotics:
Embark on a journey into the world of personalized medicine powered by robotics. Uncover how Medical robot technologies are tailored to individual patient needs, optimizing treatment plans and procedures. Witness the convergence of medical data, AI, and robotics to deliver targeted and efficient healthcare solutions.
D. Integration with the Internet of Things (IoT) for Monitoring:
Discover the synergy between robotics and the IoT in healthcare monitoring. Learn how interconnected Medical robotic devices gather real-time patient data, enabling remote tracking and analysis. Witness how this integration enhances healthcare outcomes by facilitating timely interventions and data-driven decision-making.
Case Studies
Japan: Japan is one of the leading countries in developing and using robotics in healthcare. In 2020, the Japanese government announced a plan to invest $10 billion in robotics research and development, focusing on healthcare. Examples of robotics in healthcare in Japan include:
The PARO therapeutic robot provides companionship and therapy to elderly patients and people with dementia.
The Wakamaru robot performs tasks such as delivering food and medication to hospital patients.
The Aibo robot is a companion robot for children and adults.
Singapore: Singapore is another country at the forefront of robotics in healthcare. In 2018, the Singapore government announced a plan to invest $2 billion in robotics research and development, focusing on healthcare.
One of the most well-known examples of robotics in healthcare in Singapore is the Handle robot, which transports patients and equipment around hospitals.
The Handle robot can navigate autonomously and avoid obstacles, which can help to reduce the risk of accidents. Other examples of robotics in healthcare in Singapore include:
The Mbot robot performs tasks such as cleaning and disinfecting hospital rooms.
The CARES robot is used to provide companionship to elderly patients in hospitals.
The 3D-printed prosthetic limbs are made to order and can be customized to the individual patient’s needs.
United States: The United States is also a significant player in healthcare robotics. In 2021, the US market for healthcare robotics was valued at $10.8 billion, and it is expected to reach $24.5 billion by 2028.
One of the most well-known examples of robotics in healthcare in the US is the Intuitive Surgical da Vinci Surgical System, which is used for minimally invasive surgery.
The da Vinci system has been used to perform over 7 million procedures worldwide, and it is estimated that it has saved the lives of over 1 million patients. Other examples of robotics in healthcare in the US include:
The Ekso Bionics exoskeleton is used to help people with mobility disabilities walk.
The Myo armband controls prosthetic limbs and other devices with the power of thought.
The Watson for Oncology system is used to help oncologists make more informed treatment decisions.
Here are some additional data and statistics about robotics in healthcare:
The global healthcare robotics market is expected to reach $36.8 billion by 2026.
The medical robotics market in the US is expected to grow at a CAGR of 20.2% from 2021 to 2028.
The Asia-Pacific region is expected to be the fastest-growing market for medical robotics in the next few years.
Surgery, rehabilitation, and diagnostics are the most common robotics applications in healthcare.
Robotics is used to improve healthcare procedures’ accuracy, efficiency, and safety.
Robotics is also being used to provide companionship and therapy to patients.
Robotics has the potential to revolutionize healthcare and make it more accessible to people around the world.
Conclusion
In conclusion, integrating Medical robots in healthcare marks a remarkable leap forward in medical technology. Through this blog, we’ve explored how robotics is transforming healthcare processes and patient outcomes. Robots are revolutionizing every facet of the healthcare industry, from surgical procedures and rehabilitation to diagnostics, medical devices, and patient care.
The prospects for robotics in healthcare are undeniably promising. We expect to see even more sophisticated and versatile Medical robotic systems as technology advances.
Miniaturization and enhanced precision will enable Medical robots to access previously inaccessible areas within the human body, leading to minimally invasive procedures with quicker recovery times.
Furthermore, the fusion of robotics with artificial intelligence (AI) will empower these machines to make real-time decisions based on vast amounts of patient data, contributing to more accurate diagnoses and personalized treatment plans.
Telemedicine, already on the rise, will see a boost through Medical robotics. Remote-controlled Medical robots could facilitate consultations, allowing doctors to interact with patients across great distances, ensuring timely care in emergencies, and bridging gaps in healthcare access.
The journey of Medical robotics in healthcare is an ongoing evolution. By embracing the opportunities presented by robotics while addressing the associated challenges, the healthcare industry can continue to advance, providing better care for all.
As we stand at the cusp of this transformative era, it’s clear that the synergy between human expertise and Medical robotic assistance will shape the future of healthcare in ways we can only begin to imagine.
Orthopedic surgery has come a long way in improving the lives of millions of people around the world suffering from conditions such as osteoarthritis. Traditional orthopedic implants, such as those used in total hip arthroplasty (THA) and total knee arthroplasty (TKA), have been the go-to solution for pain relief and improved function. However, a new era of medical devices is on the horizon – smart implants. These innovative devices, such as smart dental implants and others, incorporate technology to treat various conditions and detect and diagnose them, ushering in a new era of digital transformation in healthcare.
The Rise of Smart Implants
Innovative implants are reshaping orthopedic surgery by integrating with the human body and providing real-time data to patients and healthcare providers. These devices utilize sensors, microprocessors, and other electronic components to measure pressure, force, strain, stress, displacement, proximity, and temperature inside the body. This wealth of data from smart implant solutions enables healthcare providers to monitor the health and function of the implant, leading to more informed decisions about patient care and treatment.
The development of smart implants is a relatively recent phenomenon, with some of the first devices being introduced in the early 2000s. Since then, the technology has evolved rapidly, resulting in more sophisticated and capable devices. Companies like VeraSense and OrthoSensor have been at the forefront of this innovation, creating smart orthopedic devices and implants that are currently being used in clinical practice.
Benefits for Patients and Providers
Innovative implants offer a range of benefits for both patients and healthcare providers. These devices can improve patient outcomes by providing real-time monitoring, personalized care, increased patient engagement, and high-quality data.
Real-Time Monitoring
One key advantage of smart implants is their ability to continuously monitor a patient’s condition after surgery. By tracking various parameters, these devices can optimize the healing process and potentially reduce the need for frequent hospital visits. Real-time monitoring also enables early detection of implant loosening or failure, allowing for timely interventions and improved patient outcomes.
Personalized Care
Smart implants provide valuable feedback on a patient’s condition, allowing healthcare providers to tailor their treatment plans accordingly. By monitoring parameters such as range of motion and muscle strength, providers can make informed decisions about adjustments to the treatment plan and guide patients through rehabilitation. This personalized approach to care enhances the recovery process and ensures that patients achieve the best possible outcomes.
Smart implants empower patients to take an active role in their own recovery. With access to their implant data, patients can monitor their progress, set goals, and track their achievements. This increased engagement improves patient satisfaction and improves treatment adherence and overall outcomes.
High-Quality Data
The adoption of smart implants in clinical practice generates a wealth of data that can be used for research and clinical studies. Unlike traditional data collection methods, which often rely on patient compliance, smart implants provide real-time data, reducing patient burden and ensuring higher quality and quantity of data. This data-driven approach can advance orthopedic research and contribute to developing more effective treatment strategies.
Overcoming Challenges
While the potential of smart implants is promising, several challenges must be addressed for widespread adoption.
Safety and Reliability
Smart implants are designed to be used inside the human body, making safety and reliability paramount. Factors such as the choice of materials, device design, and manufacturing process all play a crucial role in ensuring the safety and reliability of these devices. Extensive testing and regulatory compliance are essential to address these challenges and instill confidence in patients and healthcare providers.
Regulatory Hurdles
Smart implants are subject to rigorous regulatory requirements, including approval from regulatory bodies such as the US Food and Drug Administration (FDA). Navigating the regulatory landscape can be complex and time-consuming, requiring significant clinical trial and documentation investment. Streamlining the regulatory pathway for smart implants would facilitate their adoption and accelerate innovation in this field.
Cost Considerations
The development and manufacturing of smart implants can be costly, posing a barrier to access for some patients and healthcare providers. Finding ways to reduce costs without compromising safety and effectiveness is essential to make smart implants more affordable and accessible to a broader population. Collaboration between manufacturers, healthcare providers, and insurers can help address these cost considerations and ensure equitable access to this transformative technology.
Privacy and Cybersecurity
As smart implants generate and transmit sensitive patient data, ensuring privacy and cybersecurity becomes a critical concern. Robust data protection measures, encryption protocols, and secure data storage are vital to safeguard patient information. Manufacturers and healthcare providers must work together to implement stringent cybersecurity measures and maintain patients’ trust in this digital age.
The Future of Smart Implants
Despite the challenges, smart implants hold tremendous potential for revolutionizing orthopedic surgery. As technology advances, these devices will become increasingly sophisticated and effective in improving patient outcomes. Ongoing research and collaboration between industry stakeholders will pave the way for developing next-generation innovative implants that redefine the standard of care in orthopedic surgery.
With continuous innovation and refinement, smart implants can transform orthopedic surgery into a more personalized, data-driven, and patient-centric field. By harnessing the benefits of innovative technology, healthcare providers can deliver better outcomes, improve patient satisfaction, and drive advancements in orthopedic research. As we embrace the future of smart implants, a new era of orthopedic surgery dawns, promising a brighter future for patients and providers alike.
In the rapidly evolving digital landscape, healthcare organizations face significant cybersecurity challenges. The increasing reliance on technology and the storage of vast amounts of sensitive patient data have made the healthcare sector a prime target for cyberattacks. The consequences of these attacks can be devastating, compromising patient privacy, disrupting healthcare services, and, in some cases, even endangering lives. In this article, we will explore the importance of healthcare cybersecurity, the types of threats faced by the industry, and the strategies and regulations in place to mitigate these risks.
The Growing Threat Landscape in Healthcare
Healthcare organizations have become attractive targets for cybercriminals due to the value of their data and the potential impact of disrupting healthcare services. The healthcare sector has seen a significant increase in cyberattacks, with hospitals accounting for 30% of significant data breaches. These breaches have resulted in the exposure of sensitive patient information and have had severe financial and reputational consequences for healthcare organizations.
One of the most prevalent types of cyberattacks in healthcare is ransomware. Ransomware attacks involve encrypting critical data or systems, rendering them inaccessible until a ransom is paid. These attacks can have dire consequences, causing disruptions in patient care and hospital operations. The healthcare industry has experienced a surge in ransomware attacks, with a 45% increase in just two months.
Understanding the Cost of Cyberattacks in Healthcare
The cost of cyberattacks in the healthcare industry is substantial and continues to rise. According to IBM’s Cost of a Data Breach 2022 report, the average cost of a healthcare data breach is $10.1 million. This represents a 10% increase from the previous year and a 42% increase from 2020. The financial impact of these breaches includes expenses related to incident response, remediation, legal fees, and potential regulatory fines.
However, the cost of a breach goes beyond financial implications. Healthcare organizations also face reputational damage and loss of patient trust. Exposure to sensitive patient information erodes confidence in the healthcare system and can lead to patients seeking care elsewhere. The long-term consequences of a breach can be detrimental to a healthcare organization’s success and sustainability.
Securing Connected Medical Devices: A Critical Challenge
The proliferation of connected medical devices has revolutionized healthcare delivery, enabling seamless communication and real-time patient health monitoring. However, these devices also present significant healthcare cybersecurity risks. Cybercriminals can exploit vulnerabilities in connected medical devices to gain unauthorized access to patient data or disrupt critical healthcare operations.
Securing connected medical devices is a complex challenge that requires a multi-layered approach. Organizations must ensure that these devices are included in their overall security infrastructure and that appropriate healthcare cybersecurity measures are implemented. This includes regular software updates, robust authentication protocols, and data encryption at rest and in transit.
The Role of Stakeholders in Healthcare Cybersecurity
Addressing cybersecurity in healthcare requires a collaborative effort from various stakeholders. Healthcare providers are responsible for implementing robust security safeguards and complying with regulations to protect patient data. IT professionals are crucial in securing networks and maintaining up-to-date software to prevent cyberattacks. Additionally, healthcare organizations must invest in comprehensive training and awareness programs to educate employees about cybersecurity best practices.
However, due to the increasing demand for expertise, healthcare cybersecurity faces challenges in finding and retaining qualified professionals. The shortage of skilled cybersecurity personnel and budget constraints can hinder the implementation of effective cybersecurity measures. As a result, many healthcare organizations are turning to external partners specializing in cybersecurity to manage and secure their infrastructure, including connected medical devices.
Regulations and Compliance in Healthcare Cybersecurity
Healthcare organizations must comply with regulations and industry standards to protect patient data. One of the most prominent regulations in the United States is the Health Insurance Portability and Accountability Act (HIPAA). HIPAA establishes standards for the privacy and security of protected health information (PHI) and imposes penalties for non-compliance. Healthcare organizations must implement access controls, encryption, and regular risk assessments to meet HIPAA requirements.
In addition to HIPAA, healthcare organizations may need to comply with other regulations, such as the General Data Protection Regulation (GDPR) in the European Union or the Australian Privacy Act. These regulations aim to protect the privacy and security of personal data and impose strict requirements on data handling and breach notification.
Best Practices for Healthcare Cybersecurity
Implementing robust cybersecurity measures is crucial for healthcare organizations to protect patient data and mitigate the risk of cyberattacks. Here are some best practices that healthcare organizations should consider:
Conduct regular risk assessments: Identify vulnerabilities in the organization’s infrastructure and prioritize risk mitigation efforts.
Implement a multi-layered defense strategy: To protect against cyber threats, use a combination of firewalls, intrusion detection systems, and secure gateways.
Secure access controls: Implement robust authentication protocols, such as multi-factor authentication, and restrict access to sensitive data on a need-to-know basis.
Encrypt data: Encrypt data at rest and in transit to ensure its confidentiality and integrity.
Provide comprehensive training: Educate employees about cybersecurity best practices, including identifying and responding to phishing attempts and other social engineering techniques.
Develop an incident response plan: Establish a clear plan for responding to cybersecurity incidents, including steps for containment, investigation, and recovery.
Stay informed about emerging threats: Keep abreast of the latest cybersecurity trends and threats to proactively address vulnerabilities in the organization’s infrastructure.
Engage external healthcare cybersecurity experts: Consider partnering with external cybersecurity experts to supplement internal resources and ensure comprehensive security monitoring and management.
By adopting these best practices, healthcare organizations can strengthen their cybersecurity posture and better protect patient data.
Conclusion
Healthcare cybersecurity is of paramount importance in the digital age. The healthcare sector faces increasing cyber threats, with the potential to disrupt patient care, compromise sensitive data, and incur significant financial and reputational damage. Securing connected medical devices, complying with regulations, and implementing best practices are essential to protecting patient data and maintaining the trust of patients and stakeholders.
To navigate the complex healthcare cybersecurity landscape, healthcare organizations may need external expertise to complement their internal resources. By partnering with cybersecurity specialists, healthcare organizations can benefit from comprehensive security monitoring and management, ensuring the ongoing protection of patient data and the continuity of healthcare services. With a proactive and collaborative approach to cybersecurity, the healthcare industry can safeguard patient privacy and deliver quality care in the digital era.
Digital transformation powered by cloud computing has become a game-changer in the healthcare industry, revolutionizing how healthcare organizations store, manage, and process data. This technology offers numerous benefits for patients and healthcare providers, including improved patient care, increased efficiency, and reduced costs. This article will explore the various facets of cloud computing in healthcare and its impact on the industry.
Understanding Cloud Computing in Healthcare
Cloud computing in healthcare refers to storing and accessing healthcare data and applications through remote servers over the Internet instead of using on-site infrastructure or personal computers. This approach allows healthcare organizations to securely store and manage large amounts of data while ensuring remote accessibility to authorized users. Cloud storage options in healthcare vary, and the Electronic Medical Records (EMR) Mandate has further propelled the adoption of cloud-based solutions, which emphasizes data security and HIPAA compliance.
The Growing Trend of Healthcare Cloud Computing
The global healthcare cloud computing market has been experiencing significant growth, with projections estimating its value to reach $35 billion by 2022, accompanied by a compound annual growth rate of 11.6%. These figures highlight the increasing adoption of cloud computing in healthcare. However, despite the promising statistics, many healthcare organizations have slowly embraced this technology. A 2018 survey revealed that 69% of participants worked at hospitals without solid plans to migrate their existing data centers to the cloud. Nevertheless, the COVID-19 pandemic has accelerated the adoption of cloud technology in healthcare, prompting more organizations to make the necessary changes to enhance convenience, quality, and cost-effectiveness.
Cloud computing offers a wide range of benefits for patients, physicians, and healthcare organizations. Let’s explore some of the key advantages:
1. Improved Analysis and Monitoring of Medical Data
Cloud-based solutions enable more efficient analysis and medical data monitoring, facilitating the diagnosis and treatment of various illnesses. With the ability to store and process large volumes of data, healthcare providers can leverage advanced analytics tools to gain valuable insights that can enhance patient care and outcomes.
2. Large Storage Capacity for Electronic Health Records (EHRs) and Images
Healthcare organizations generate vast amounts of digital data, including electronic health records and radiology images. Cloud storage offers unlimited capacity, eliminating the need for additional on-site storage infrastructure. This scalability ensures that healthcare providers can efficiently manage and access patient records without physical storage limitations.
3. Instantaneous Access to Computing Services
Cloud computing provides healthcare organizations with on-demand access to computing services, eliminating the need for extensive in-house IT infrastructure. This instant availability of resources allows healthcare providers to scale their operations quickly and efficiently, reducing the time and costs associated with traditional on-premises computing.
4. Enhanced Data Security and Confidentiality
Data security is a critical concern in healthcare, given the sensitive nature of patient information. Cloud computing offers robust security measures, including encryption and access controls, to protect patient data from unauthorized access or breaches. Cloud service providers comply with industry regulations and standards, such as the Health Insurance Portability and Accountability Act (HIPAA), ensuring that healthcare organizations can maintain compliance while leveraging the benefits of cloud technology.
5. Streamlined Collaboration and Compatibility
Cloud computing facilitates seamless collaboration and compatibility among healthcare professionals. By storing electronic medical records in the cloud, doctors can access patient information in real-time, enabling more accurate and coordinated treatment. Physicians can easily share information with colleagues, reducing the risk of duplicate efforts and improving overall patient care.
6. Cost Savings and Efficiency
Cloud computing in healthcare offers significant cost savings. By eliminating the need for on-premises infrastructure and reducing the reliance on in-house IT teams, healthcare providers can reduce capital expenses and operational costs. Cloud services operate on a subscription-based model, allowing organizations to pay only for the resources they use. This cost-efficiency enables healthcare organizations to allocate their budget more effectively and invest in other areas of patient care and innovation.
7. Agility and Resilience
Cloud computing in healthcare provides organizations with agility and resilience, particularly during times of crisis. The COVID-19 pandemic showcased the importance of cloud technology in ensuring uninterrupted healthcare services. Organizations that had already embraced the cloud or swiftly transitioned to cloud-based operations could pivot and continue delivering services with minimal disruption. Cloud technology allows healthcare providers to quickly adapt to changing circumstances and rapidly deploy new solutions when needed.
Applications of Cloud Computing in Healthcare
Cloud computing in healthcare finds extensive applications in various areas. Let’s explore some of the key use cases:
1. E-Health and Telemedicine
Cloud computing plays a vital role in enabling e-health and telemedicine services. Through cloud-based platforms, doctors can collaborate and provide remote healthcare services, regardless of geographical location. Telemedicine solutions leverage cloud computing to facilitate real-time sharing of patients’ medical data, minimizing the need for unnecessary hospital visits and improving access to healthcare services.
2. Healthcare Information Systems
Cloud-based healthcare information systems enhance patient care by improving querying services, billing, finance, and human resources management. These systems enable healthcare organizations to develop, test, and deploy applications more efficiently, promoting speed, collaboration, and integration with other healthcare systems.
3. Personal Health Records (PHRs)
Cloud-based solutions for personal health records empower individuals to access, manage, and share their health data easily. These programs offer advanced sharing capabilities and give users control over their distributed data. By leveraging cloud technology, personal health records become more accessible and customizable, fostering patient engagement and enabling better-informed healthcare decisions.
4. Customization and Flexibility
Cloud computing in healthcare allows for greater customization and flexibility in electronic health record (EHR) systems. Previously, implementing customized solutions required extensive programming and IT expertise. With cloud-based solutions, healthcare providers can choose from various customizable options and pre-built care plans, tailoring the system to their needs. This flexibility enhances the overall efficiency and effectiveness of healthcare workflows.
5. High Data Storage Capacity
One of the significant advantages of cloud computing in healthcare is its ability to provide high-capacity data storage. Hospitals and healthcare practices generate vast digital data daily, including medical files, prescriptions, and lab results. Storing these records on-site requires additional storage capacity, which can become a significant ongoing cost. Cloud storage offers unlimited space to store and manage large volumes of data, providing scalability and eliminating the need for expensive on-premises storage infrastructure.
6. Cost-Effective Solutions
Cloud computing in healthcare offers cost-effective solutions for healthcare providers. By leveraging cloud-based services, healthcare organizations can reduce capital expenses associated with traditional on-premises infrastructure. Cloud solutions operate on a pay-as-you-go model, allowing organizations to pay only for the resources they use. This flexibility enables healthcare providers to allocate their budget more efficiently and invest in other critical areas, such as patient care and innovation.
7. Drug Discovery and Research
Cloud computing plays a significant role in drug discovery and research. Drug discovery requires substantial computing power to analyze vast amounts of data and uncover potential molecules for further investigation. Infrastructure as a Service (IaaS) offered by cloud providers facilitates this computational power, enabling researchers to accelerate the drug discovery process and drive innovation in healthcare.
Overcoming Challenges and Ensuring Success
Implementing cloud computing in healthcare comes with its challenges. Here are a few key considerations to ensure a successful transition:
1. Skilled Specialists
Finding skilled specialists who possess expertise in healthcare and cloud computing can be a challenge. It is crucial for healthcare organizations to partner with experienced software development providers who understand the industry’s unique requirements.
2. Ecosystem Integration
To maximize the benefits of cloud computing in healthcare, organizations must integrate cloud technology with other emerging technologies, such as the Internet of Things (IoT), artificial intelligence (AI), and data management systems. Seamless integration of these technologies ensures interoperability and enables healthcare organizations to leverage the full potential of cloud computing.
3. Adoption and Change Management
Transitioning from legacy systems to cloud-based solutions requires careful planning and change management. Educating and training staff members on the new technology and how it will impact their daily workflows is essential. Effective change management strategies ensure a smooth transition and enable healthcare organizations to reap the benefits of cloud computing.
4. Security and Privacy
Data security and privacy are critical concerns in healthcare. Storing medical data in the cloud introduces potential risks, such as data breaches or unauthorized access. Healthcare organizations must work closely with cloud service providers to ensure robust security measures, including encryption, access controls, and compliance with industry regulations such as HIPAA.
Conclusion
Cloud computing has transformed the healthcare industry, offering numerous benefits for patients, physicians, and healthcare organizations. From improved analysis and medical data monitoring to cost savings and enhanced patient care, cloud computing has become an essential tool in modern healthcare. Despite the challenges, adopting cloud technology is crucial for healthcare organizations to stay competitive and deliver high-quality care in today’s digital era. By embracing cloud computing and leveraging its capabilities, healthcare organizations can unlock new opportunities, drive innovation, and improve patient outcomes.
In today’s fast-paced digital age, technology redefines how we approach various aspects of our lives, and healthcare is no exception. The rise of medical and healthcare apps has opened up a world of possibilities, empowering individuals to take charge of their well-being like never before. So, what are health apps, and why do you need them?
Whether you’re a health-conscious individual seeking to maintain a balanced lifestyle or a patient looking for personalized medical assistance, digital transformation leading to cutting-edge applications is revolutionizing how we access and manage healthcare services.
Unleashing the Potential of Medical Apps: What Are They?
Medical apps, also known as health apps or healthcare apps, are software applications designed to cater to various health-related needs. They run on smartphones, tablets, and other mobile devices, providing users with seamless access to a wealth of information, tools, and resources at their fingertips.
From tracking fitness goals and monitoring vital signs to managing chronic conditions, these apps offer an all-encompassing approach to enhancing personal health and well-being.
Why Do You Need Health Apps in Your Life?
Empowerment through Personalized Healthcare: Medical apps are paving the way for personalized healthcare experiences. By analyzing user data and employing advanced algorithms, these apps can offer tailored health insights, customized nutrition plans, and suitable exercise routines.
Gone are the days of one-size-fits-all healthcare; with medical apps, your health journey becomes uniquely yours.
Seamless Health Monitoring on the Go: Whether you’re a busy professional or constantly on the move, health apps provide the convenience of real-time health monitoring without the need for frequent doctor visits. Monitoring vitals, medication reminders, and symptoms becomes effortless with just a few taps on your mobile device.
Improved Chronic Disease Management: Healthcare apps offer a lifeline of support for individuals managing chronic health conditions. These apps assist in tracking medications, offering dietary guidelines, and monitoring symptoms, enabling users to lead fuller and healthier lives.
Health Education Made Accessible: Staying informed about health-related matters is crucial for making sound decisions. Medical apps serve as a valuable repository of health information, providing access to articles, blogs, and expert advice on a wide range of medical topics from your smartphone.
Building Healthy Habits: One of the most significant advantages of health apps is their ability to foster healthy habits. From promoting regular exercise routines to encouraging mindful eating, these apps can be your companions in building a sustainable and health-conscious lifestyle. As the world embraces a digital transformation, medical and healthcare apps are emerging as indispensable tools in managing our well-being. Embrace the power of these apps and embark on a journey of empowered health and vitality.
Understanding Medical Apps
Medical or healthcare apps are innovative software applications designed to address various aspects of healthcare, medical information, and wellness management. These applications are specifically crafted to assist healthcare professionals, patients, and individuals in optimizing medical processes, promoting overall well-being, and enhancing the efficiency of healthcare delivery.
Medical apps offer various functionalities, from patient monitoring and health data tracking to medical reference guides and telemedicine services. They can be accessed on smartphones, tablets, and other intelligent devices, offering convenience and accessibility to users.
Examples of Medical Apps and Their Features
Tracking and Monitoring Vital Signs with Medical Apps
Stay on top of your health with cutting-edge medical apps that track and monitor vital signs. These healthcare apps utilize advanced technology to closely monitor crucial indicators such as heart rate, blood pressure, temperature, etc.
Integrating these apps into your daily routine allows you to proactively manage your well-being and detect potential health issues early on. Whether you’re a fitness enthusiast or someone with specific medical conditions, these medical device apps are necessary for optimizing your health.
Medication Management and Reminders: Simplify with Healthcare Apps
Never miss a dose again with the help of healthcare apps specialized in medication management and reminders. These medical apps are the ultimate solution for organizing your medications, setting personalized reminders, and ensuring you take your prescribed drugs on time.
These medical apps are perfect for individuals managing complex medication regimens or caregivers looking after their loved ones. Embrace the convenience and reliability of healthcare apps to streamline your medication routine.
Telemedicine and Virtual Consultations: Connecting Patients and Doctors with Medical Apps
Experience the future of healthcare with medical apps offering telemedicine and virtual consultations. These innovative healthcare apps bridge the gap between patients and doctors, providing remote access to medical experts for consultations, diagnoses, and treatment plans.
Seamlessly connect with healthcare professionals from the comfort of your home or while on the go, saving time and resources. With medical apps facilitating virtual healthcare interactions, you can receive expert medical advice and care regardless of location.
Symptom Checkers and Health Assessments: Empowering Users with Medical Apps
Empower yourself with medical apps featuring symptom checkers and health assessments. These healthcare apps put reliable medical information at your fingertips, allowing you to assess symptoms, identify potential health issues, and make informed decisions about your well-being.
Whether you have a specific health concern or want to monitor your overall health status, these medical apps offer personalized insights and guidance. Take charge of your health journey with the convenience and accuracy of symptom checkers and health assessments within medical apps.
Exploring Healthcare Apps
Healthcare apps, also known as medical or healthcare applications, are mobile applications that offer users a wide range of health-related services and information.
These apps cover medical diagnosis, symptom tracking, medication management, fitness monitoring, telemedicine consultations, and mental health support. By utilizing smartphones and mobile devices, healthcare apps provide improved accessibility and convenience for managing personal health and wellness efficiently.
Distinction Between Medical and Healthcare Apps
Medical Apps:
Medical apps specifically offer tools, information, and services related to medicine.
These apps are often designed for healthcare professionals, medical students, and researchers to aid diagnosis, treatment, and research.
Medical apps may include resources such as drug databases, medical calculators, anatomy reference guides, and clinical decision-support systems.
The target audience for medical apps is primarily medical professionals or individuals with a specific interest in medical knowledge.
Healthcare Apps:
Healthcare apps encompass a broader range of applications that cater to the general population’s health and well-being.
These apps target a wider audience, including patients, caregivers, fitness enthusiasts, and anyone interested in maintaining a healthy lifestyle.
Healthcare apps may include features like symptom trackers, fitness trackers, nutrition guides, meditation tools, and telemedicine services.
Healthcare apps promote overall wellness, manage chronic conditions, and facilitate easy access to healthcare services.
Wide Range of Healthcare Apps Available
Mental Health and Meditation Apps:
Discover a range of cutting-edge mental health and meditation apps designed to promote emotional well-being and mindfulness. These medical apps provide various tools and resources to help users manage stress, anxiety, and depression.
With a focus on mental health, these healthcare apps offer guided meditation sessions, relaxation techniques, and personalized therapy options for users seeking mental wellness and balance in their daily lives.
Fitness and Nutrition Apps:
Stay on top of your fitness and nutrition goals. These innovative applications cater to users’ needs by providing personalized workout routines, diet plans, and progress-tracking features. Fitness and nutrition apps offer exercises and nutritional advice to suit various lifestyles and health objectives.
Women’s Health and Pregnancy Apps:
Explore our health and pregnancy medical apps, which offer comprehensive support and guidance for every stage of a woman’s reproductive journey. From menstrual cycle tracking to pregnancy planning and postnatal care, these apps address women’s unique healthcare needs.
These apps allow expectant mothers to access helpful resources, prenatal exercises, and expert advice, ensuring a healthier and smoother pregnancy experience.
Chronic Disease Management Apps:
Take charge of chronic disease management with our medical and healthcare app collection. These applications provide tools for tracking symptoms, medication schedules, and lifestyle factors affecting overall health.
With personalized insights and regular progress updates, these chronic disease management apps empower users to actively participate in their health management and improve their quality of life.
The Growing Popularity of Health Apps
Statistics and Trends in Health App Usage
The number of health apps available has grown exponentially. In 2013, only 66,713 health apps were available in top app stores worldwide. By 2020, that number had grown to over 350,000.
The most popular health app categories are fitness and exercise, weight loss, and chronic disease management. In 2022, the top 5 health apps by downloads were:
MyFitnessPal (fitness and exercise)
Flo (women’s health)
Headspace (mental health)
Strava (fitness and exercise)
Sleep Cycle (sleep)
Health app usage has increased during the COVID-19 pandemic. A survey by Morning Consult found that 32% of health app users increased their usage during the pandemic, while just 13% used them less often.
Health apps are increasingly being used to track and manage chronic conditions. A study by IQVIA Institute found that 47% of all health apps in 2020 were focused on health condition management, up from 28% in 2015.
Health apps are becoming more sophisticated and integrated with other healthcare technologies. For example, some health apps now allow users to connect with their doctors, share their data, and receive personalized recommendations.
Here are some additional trends in health app usage:
The use of health apps is becoming more mainstream. In the past, health apps were primarily used by people already interested in their health. However, as the number of health apps has grown and the quality of these apps has improved, more and more people are using them.
Health apps are becoming more personalized. Many health apps now offer features that allow users to track their growth over time, set goals, and receive customized recommendations. This personalization helps users to stay motivated and achieve their health goals.
Health apps are becoming more integrated with other healthcare technologies. As the healthcare industry becomes more digitized, health apps are becoming more integrated with other healthcare technologies, such as electronic health history (EHRs) and wearable devices. This integration makes it easier for users to access and share their health data, which can help them manage their health better.
Overall, health app use is increasing and vital to healthcare. As health apps become more sophisticated and integrated with other healthcare technologies, they have the potential to revolutionize the way we maintain our health.
Reasons for the Surge in Adoption:
1. Convenience and Accessibility
2. Empowerment and Informed Decision Making
3. Integration with Wearable Devices
4. Positive Impact on Health Outcomes
How do you choose the right health app for your needs?
Assessing Your Health Goals and Requirements:
When selecting a medical or healthcare app, determine your health goals and requirements. Identify what aspects of your health you want to address and what features you need in an app to achieve those goals effectively.
Researching and Reading User Reviews:
Research available medical and healthcare apps thoroughly. Read user reviews and testimonials to gain insights into the app’s performance, usability, and overall user satisfaction. This will help you make an informed decision about the app’s effectiveness.
Checking for Medical Endorsements and Certifications:
Look for medical apps that have received endorsements or certifications from reputable healthcare organizations or regulatory authorities. These endorsements can assure the app’s reliability and adherence to medical standards.
Understanding App Permissions and Data Policies:
Before choosing a medical app or healthcare app, review its permissions and data policies. Ensure the app requests only necessary approvals and is transparent about handling your health data. Prioritize apps that prioritize user privacy and security.
Benefits and Advantages of Health Apps:
A. Improved Patient Engagement
B. Enhanced Self-Management of Health
C. Facilitation of Remote Monitoring
D. Potential for Early Detection and Prevention
E. Promoting a Healthy Lifestyle
Conclusion
To sum up, health apps, sometimes referred to as medical or healthcare apps, are crucial tools in the current digital era that address various areas of health and wellness. These programs offer a variety of features and functionalities to help users monitor, manage, and improve their general health.
Health apps are crucial in contemporary healthcare since they give consumers many advantages. They offer simple access to medical information, individualized health advice, and the capacity to monitor and assess crucial health parameters.
Health applications benefit individuals and serve a critical role for healthcare providers in managing chronic illnesses, tracking dietary habits, and arranging medical appointments. They allow telemedicine consultations, remote patient monitoring, and improved patient-doctor contact.
Health apps also support public health programs by encouraging healthy lifestyle choices, promoting preventative care, and increasing knowledge of health issues. These applications encourage positive behavior change by instilling a feeling of accountability and motivation, which improves both individual and community health outcomes.
The full potential of health apps can only be realized through rigorous curation and Optimization. Developers and providers must ensure that these applications adhere to stringent medical and confidentiality requirements to maintain the security and privacy of user data.
Additionally, ongoing upgrades and enhancements are required to stay up with the rapidly changing healthcare industry and to give users the most accurate and relevant information.
The healthcare industry is undergoing a transformative shift fueled by advancements in technology. Among these technologies, machine learning (ML) has emerged as a powerful tool with the potential to revolutionize healthcare. By leveraging ML algorithms and AI-powered systems, healthcare providers can analyze vast amounts of data, identify patterns, and make data-driven decisions with unprecedented accuracy. From personalized treatment plans to early disease detection, machine learning is reshaping the industry and offering new possibilities for improved patient outcomes.
In this comprehensive guide, we will explore the top applications of machine learning in healthcare, delve into the challenges of implementing this technology, and discuss the future of ML in the healthcare sector. So, let’s dive in and discover how machine learning unlocks medicine’s future.
Personalizing Treatment for Better Patient Care
One of the critical applications of machine learning in healthcare is the ability to personalize treatment plans for individual patients. By analyzing a patient’s medical history, symptoms, and test results, ML algorithms can assist healthcare providers in developing customized treatments and prescribing medicines that target specific diseases. This personalized approach improves patient care and maximizes the chances of successful treatment outcomes.
Machine learning also enables healthcare organizations to leverage electronic health records (EHR) to gain valuable insights into patient data. By utilizing ML algorithms, doctors can make faster and more accurate decisions regarding treatment options based on a patient’s specific medical history.
Additionally, machine learning can assist doctors in determining if a patient is ready for necessary changes in medication, ensuring that the proper treatment is administered from the beginning. This personalized medicine approach empowers healthcare providers to deliver tailored care and improve patient outcomes.
Detecting Fraud and Ensuring Data Security
Fraud detection is another crucial application of machine learning in healthcare. The healthcare industry is plagued by fraudulent claims, which result in financial losses and compromise patient safety. Machine learning models can analyze vast amounts of data to detect invalid claims before they are paid, speeding up the approval, processing, and payment of valid claims.
Leading healthcare organizations like Harvard Pilgrim Health are embracing AI and ML technologies to root out healthcare fraud. ML-based fraud detection systems can identify suspicious claims and detect patterns of fraudulent behavior, safeguarding the integrity of the healthcare system.
In addition to fraud detection, machine learning also plays a vital role in ensuring data security in healthcare. Additional security measures are necessary with the growing amount of sensitive and confidential information collected. ML can help identify and prevent the theft of patient data, ensuring the privacy and confidentiality of healthcare records.
Early Disease Detection for Timely Intervention
Early detection of diseases is crucial for effective treatment and improved patient outcomes. Machine learning algorithms, combined with supervised and unsupervised learning techniques, aid doctors in detecting diseases that may otherwise go unnoticed. ML algorithms can identify early warning signs and enable timely intervention by comparing new data with existing data on specific diseases.
For example, ML algorithms can analyze medical imaging data, such as MRI or radiology scans, to detect abnormalities and assist doctors in diagnosing conditions such as liver and kidney infections, tumors, and cancer. This early detection allows healthcare providers to initiate treatment plans at the earliest stages of the disease, increasing the chances of successful outcomes.
Machine learning also holds promise in predicting disease outbreaks and epidemics. By analyzing vast amounts of data collected from satellites, social media updates, and other sources, ML algorithms can identify patterns and provide real-time alerts for diseases ranging from malaria to chronic infectious diseases. This early warning system is precious in resource-constrained areas with limited medical infrastructure.
Revolutionizing Surgical Procedures with Robotics
Machine learning is revolutionizing surgical procedures through the use of robotics. ML-powered surgical robots offer enhanced precision and speed, reducing the risks associated with complex surgeries. These systems can perform intricate surgical procedures with minimal blood loss, fewer side effects, and reduced patient pain. Also, post-surgery recovery is faster and easier, improving patient outcomes.
For example, Maastricht University Medical Center utilizes an ML-powered surgical robot to suture small blood vessels, some as thin as 0.03 millimeters. This level of precision and control is only achievable through machine learning and robotics integration in healthcare.
ML-powered technologies also provide real-time information and insights into a patient’s health condition, enabling healthcare providers to make intelligent decisions before, during, and after procedures. This technology holds promise for minimizing risks and improving surgical outcomes.
Enhancing Prescription Accuracy and Preventing Errors
Prescription errors can have severe consequences for patients, leading to adverse drug reactions and even death. Machine learning solves this problem by analyzing historic electronic health record (EHR) data and comparing new prescriptions against it. ML algorithms can flag prescriptions that deviate from typical patterns, prompting doctors to review and adjust them, thus preventing medication errors.
Brigham and Women’s Hospital implemented an ML-powered system to pinpoint prescription errors. Over a year, the system identified thousands of potential errors, enabling the hospital to save millions of dollars in healthcare-related costs and improve the quality of care by preventing drug overdosing and health risks.
By leveraging machine learning, healthcare providers can significantly reduce prescription errors, enhance patient safety, and improve the overall quality of care.
Streamlining Clinical Research and Trials
Clinical research and trials are essential for developing new drugs and medical procedures. However, these processes are often time-consuming and costly. Machine learning algorithms have the potential to streamline clinical research and trials, making them more efficient and cost-effective.
ML algorithms can assist researchers in determining the best sample size for a trial, gathering and analyzing data points, and reducing data-based errors. By leveraging the power of ML, researchers can accelerate the discovery and development of new treatments, ultimately benefiting patients and advancing medical science.
In urgent healthcare needs, such as developing vaccines for COVID-19, machine learning can expedite the process by quickly analyzing vast amounts of data and identifying potential solutions. This accelerated approach to research and development has the potential to save lives and improve public health outcomes.
Unleashing the Power of Drug Discovery
One of the most significant benefits of machine learning in healthcare is its ability to accelerate drug discovery and development. ML algorithms can analyze vast databases of molecular structures and identify potential drug candidates with significant economic value for pharmaceutical companies. This process saves time and resources and opens up new avenues for innovative treatments.
Atomwise, a pharmaceutical company, utilizes supercomputers and deep learning technology to search for therapeutic solutions within molecular databases. In one instance, Atomwise successfully repurposed existing drugs on the market to treat the Ebola virus, a process that would have taken years using traditional methods.
Machine learning in drug discovery offers the potential for faster and more cost-effective development of new treatments, addressing unmet medical needs and improving patient care.
Revolutionizing Medical Imaging Diagnosis
Medical imaging plays a crucial role in diagnosing and monitoring diseases. Machine learning is revolutionizing medical imaging diagnosis by enabling the analysis of large volumes of imaging data with incredible accuracy and speed. ML algorithms can recognize abnormalities in various medical images, such as MRI or radiology scans, and assist doctors in making accurate diagnoses.
For instance, the UVA University Hospital utilizes ML algorithms to analyze biopsy images and differentiate between celiac disease and environmental enteropathy as reliably as doctors do. This technology enhances the speed and accuracy of diagnosis, leading to better patient outcomes.
As machine learning continues to evolve, healthcare providers can expect further advancements in medical imaging diagnosis, allowing for more precise and efficient diagnoses of a wide range of conditions.
Overcoming Challenges and Shaping the Future of ML in Healthcare
While machine learning holds immense promise for the healthcare industry, implementing this technology comes with challenges. Patient safety is a primary concern, as decisions made by ML algorithms rely heavily on the quality and reliability of the input data. Flawed decisions can have severe consequences for patients, emphasizing the need for rigorous data validation and quality assurance processes.
Another challenge lies in the availability and standardization of healthcare data. ML algorithms require high-quality, standardized data to deliver accurate results. However, healthcare data is often incomplete, inconsistent, or unstructured, requiring significant effort to clean, validate, and structure for ML purposes.
Privacy concerns also pose a challenge, particularly with collecting and storing sensitive patient data. Healthcare organizations must implement robust security measures to protect patient privacy and ensure compliance with data protection regulations.
Despite these challenges, the future of machine learning in the healthcare industry looks promising. The global AI and ML in the healthcare market is projected to experience significant growth in the coming years, driven by factors such as the increasing demand for personalized medicine, the growing datasets of patient health-related information, and the need to reduce healthcare costs.
Machine learning technologies may enable programmed robots to assist doctors in surgical procedures, provide faster and more accurate alerts for conditions like seizures or sepsis, and improve risk scoring and clinical decision support systems. As technology evolves, healthcare professionals and clinicians must embrace machine learning to unlock its full potential.
Conclusion
Machine learning is revolutionizing the healthcare industry, offering new possibilities for personalized treatment, fraud detection, early disease detection, robotic surgery, prescription accuracy, clinical research, drug discovery, and medical imaging diagnosis. Despite the challenges of implementation, ML has the potential to reshape healthcare delivery, improve patient outcomes, and reduce costs.
As healthcare providers and organizations embrace machine learning, they must prioritize patient safety, ensure data quality and security, and leverage ML algorithms to make informed, data-driven decisions. The future of machine learning in healthcare holds immense promise, transforming the industry and unlocking new frontiers in medicine. By harnessing the power of ML, we can unlock the full potential of personalized, data-driven healthcare.
Technology has emerged as a driving force in the ever-evolving healthcare industry landscape, revolutionizing how we approach medical care and well-being. Health technology, a vast and dynamic field, encompasses an array of cutting-edge innovations, from digital health solutions to advanced medical devices, all aimed at enhancing patient outcomes, streamlining processes, and ultimately shaping a healthier world.
As the demands of modern healthcare continue to grow, so does the importance of integrating technology into medical practices. These innovative solutions leverage data, connectivity, and artificial intelligence to optimize diagnostics, treatment, and patient care, leading to a profound shift in how we perceive and manage health.
Healthcare Technology, also known as Health Technology or MedTech, refers to the application of advanced scientific and technological innovations within the healthcare industry to improve medical services, patient care, and overall health outcomes.
This field encompasses a wide range of hardware, software, devices, and processes designed to enhance the efficiency, accuracy, and accessibility of healthcare services while promoting better patient experiences and health management. In this blog, we embark on a captivating journey to explore the realm of healthcare technology, delving into the remarkable strides made in the healthcare industry and the transformative impact of health technology on the well-being of individuals and communities.
The Role of Healthcare Technology in the Healthcare Industry
The healthcare industry has undergone significant transformation due to health technology integration. Rapid technological advancements have revolutionized healthcare practices, improving patient outcomes, enhancing efficiency, and better overall healthcare experiences—enhanced Patient Care:
Health technology plays a pivotal role in delivering high-quality patient care. Electronic Health Records (EHRs) enable healthcare providers to access patients’ medical histories, diagnostic reports, and treatment plans promptly.
This seamless information exchange ensures better coordination among healthcare professionals, reducing medical errors and enhancing patient safety.
Empowering Medical Professionals:
Health technology has equipped medical professionals with advanced tools and insights. Additionally, AI-powered diagnostic algorithms help physicians analyze large datasets, enabling early disease detection and personalized treatment options based on individual patient characteristics.
Health Informatics and Big Data Analytics:
Health informatics and big data analytics have revolutionized healthcare research and decision-making. By aggregating and analyzing vast amounts of healthcare data, health technology has paved the way for evidence-based medicine and population health management.
These insights assist healthcare providers in predicting disease outbreaks, identifying high-risk patients, and implementing preventive measures, ultimately leading to improved public health outcomes.
Patient Engagement and Education:
Health technology has fostered patient engagement and education, leading to more informed and proactive healthcare consumers. Telehealth services and health-related educational platforms empower patients to participate in their treatment plans and make informed lifestyle choices, resulting in better health outcomes.
Fostering Healthcare Innovation:
Health technology has catalyzed continuous healthcare innovation. Technological advancements have opened new avenues for medical research and treatment options, from robotic-assisted surgeries to gene editing techniques. Startups and established healthcare organizations are investing in health tech innovations, shaping the future of the healthcare industry.
Key Components of Healthcare Technology
A. Electronic Health Records (EHR) and Health Information Systems
B. Medical Devices and Equipment
C. Telemedicine and Remote Patient Monitoring
D. Health Apps and Wearable Devices
E. Health Informatics and Data Analytics
Advancements in Health Technology
Healthcare technology has rapidly evolved, revolutionizing how medical professionals diagnose, treat, and manage patient care. These advancements have significantly impacted the healthcare industry, improving patient outcomes, enhancing efficiency, and reducing costs. Here are some critical areas of health technology optimized to transform the healthcare sector:
Telemedicine and Virtual Healthcare: Telemedicine has emerged as a game-changer, enabling remote consultations and virtual healthcare services. Patients can now receive medical advice, diagnostics, and even therapy sessions through video conferencing and digital platforms. This has expanded access to medical expertise, particularly in rural or underserved areas, and made healthcare more convenient for patients.
Electronic Health Records (EHRs): The adoption of EHRs has streamlined patient data management, allowing healthcare providers to access a patient’s medical history, test results, and treatment plans more efficiently. EHRs enhance care coordination, reduce errors, and enable better-informed decision-making, ultimately improving patient care and safety.
Artificial Intelligence (AI) and Machine Learning (ML): AI and ML have made significant inroads in the healthcare industry. They analyze vast amounts of patient data, identify patterns, and predict outcomes. These technologies aid in early diagnosis, personalized treatment plans, and drug development, leading to better patient outcomes and more effective healthcare interventions.
Internet of Things (IoT) in Healthcare: IoT devices are being integrated into healthcare to monitor patients’ health remotely and in real time. Wearable health trackers, intelligent medical devices, and remote patient monitoring systems allow healthcare providers to track vital signs, manage chronic conditions, and intervene promptly in emergencies, improving patient management and reducing hospital readmissions.
Robotics and Automation: Robotic-assisted surgeries and automation have revolutionized surgical procedures, making them more precise and less invasive. Robots can perform complex surgeries more accurately, reducing patient trauma, faster recovery times, and better surgical outcomes.
3D Printing in Healthcare: 3D printing technology has opened up new possibilities in healthcare, allowing the creation of patient-specific medical implants, prosthetics, and surgical models. This customization improves treatment efficacy and patient comfort while reducing costs and wait times.
Digital Health Apps: The proliferation of health and wellness apps has empowered individuals to take control of their health. These apps help users track their diet, exercise, and sleep patterns and manage chronic conditions. They also promote preventive care and healthy lifestyles, improving overall population health.
Genomic Medicine: Advances in genomic technology have enabled precision medicine, where treatment plans are tailored to an individual’s genetic makeup. Genomic testing helps identify genetic predispositions to diseases, predict drug responses, and develop targeted therapies for specific conditions, offering more effective and personalized healthcare.
Nanotechnology in Medicine: Nanotechnology is applied to drug delivery systems, diagnostics, and imaging technologies. Nanoparticles can deliver drugs to specific targets in the body, reducing side effects and improving therapeutic efficacy. Nanoscale imaging enables earlier and more accurate disease detection.
Blockchain in Healthcare: Blockchain technology finds applications in healthcare data management, ensuring secure and interoperable electronic health records. It helps maintain patient privacy and enables seamless sharing of health information among different providers, leading to more coordinated care.
Impact of Health Technology on the Healthcare Industry
Enhanced Patient Care and Diagnostics:
Health technology has revolutionized the way healthcare providers diagnose and treat patients. Advanced diagnostic tools, such as medical imaging devices (MRI, CT scans, etc.), wearable health monitors, and point-of-care testing, have enabled faster and more accurate diagnoses. This translates into early detection of diseases, reduced error rates, and better treatment planning, ultimately improving patient outcomes and quality of life.
Telemedicine and Remote Healthcare Services:
Integrating health technology and telemedicine has brought healthcare services to remote areas, underserved populations, and patients with mobility challenges.
Telemedicine enables patients to consult with healthcare professionals virtually, offering real-time medical advice, remote monitoring of chronic conditions, and even performing minor procedures. This increased accessibility to healthcare services has significantly improved healthcare equity and reduced the burden on physical healthcare facilities.
Electronic Health Records (EHRs) and Health Information Exchange:
Healthcare technology has facilitated the transition from traditional paper-based records to electronic health records (EHRs). EHR systems store and manage patient information securely, ensuring easy access by authorized healthcare providers across different healthcare settings.
Health Information Exchange (HIE) allows seamless sharing of patient data among healthcare institutions, promoting continuity of care and reducing redundant tests and procedures, thereby lowering healthcare costs.
Personalized Medicine and Precision Treatments:
Health technology has enabled the advent of personalized medicine, tailoring treatments based on individual genetic makeup, lifestyle factors, and other patient-specific data.
Advances in genomics, data analytics, and artificial intelligence have significantly contributed to the development of precision medicine approaches, leading to more effective and targeted treatments. This approach improves treatment outcomes and reduces adverse reactions and unnecessary treatments.
Healthcare Analytics and Decision Support:
Integrating health technology with data analytics and artificial intelligence has empowered healthcare professionals with powerful decision-support tools.
These tools analyze patient data, identify patterns, predict potential health risks, and recommend appropriate treatment plans. Healthcare analytics helps providers make data-driven decisions, optimize resource allocation, and improve the overall efficiency of healthcare delivery.
Medical Robotics and Minimally Invasive Procedures:
Health technology has given rise to medical robotics, enhancing surgical precision and efficiency. Robots assist surgeons in performing procedures with greater accuracy, leading to reduced risks, shorter recovery times, and improved patient outcomes. Minimally invasive procedures, made possible by health technology advancements, also contribute to shorter hospital stays and lower healthcare costs.
Future Trends in Health Technology
Virtual and Augmented Reality (VR/AR) in Healthcare:
Virtual and Augmented Reality has emerged as transformative technologies in the healthcare industry, revolutionizing how healthcare professionals deliver services and patients experience care. These immersive technologies are optimized for the healthcare industry, fostering advancements in health technology and patient outcomes.
Virtual Reality has found applications in pain management and therapeutic interventions. Patients undergoing painful procedures or chronic pain can benefit from VR distraction therapy, where immersive experiences divert their attention from discomfort, reducing the need for conventional pain medication.
Nanotechnology and its Medical Applications:
Nanotechnology is a cutting-edge field that involves manipulating and controlling matter at the nanoscale level, roughly between 1 and 100 nanometers. This technology holds immense promise in various industries, with the healthcare industry being one of the primary beneficiaries. Nanotechnology’s application in health technology has opened up revolutionary avenues in medical diagnostics, drug delivery, imaging, and disease treatment.
5G and the Transformation of Healthcare Connectivity:
The healthcare industry is known for its reliance on cutting-edge technology to provide efficient and quality patient care. With 5G, healthcare facilities can optimize their operations, from patient monitoring and diagnostics to telemedicine and remote consultations.
The lightning-fast data transfer speeds of 5G facilitate real-time transmission of medical data and high-definition imaging, enabling healthcare professionals to make timely, accurate decisions, even in the most critical situations.
Bioprinting and Organ Transplantation:
Bioprinting is an innovative and revolutionary technique in the healthcare industry that combines advanced 3D printing technology with biology to create living tissues and even whole organs.
The process involves layer-by-layer deposition of biocompatible materials, known as bio-inks, containing live cells, growth factors, and other biological components. The integration of these elements allows the bio-inks to self-organize and mature into functional tissue structures.
Data-driven Health Interventions:
Data-driven health interventions are innovative approaches within the healthcare industry that leverage health technology and data analytics to improve patient outcomes and enhance healthcare services.
These interventions rely on systematically collecting, analyzing, and interpreting large-scale health data from diverse sources, such as electronic health records, wearables, mobile apps, and medical devices.
Case Studies: Successful Implementation of Healthcare Technology
Case Study 1: Pfizer’s Remote Monitoring Program for COPD Patients
Problem: COPD is a chronic respiratory disease affecting millions worldwide. It can be challenging to manage COPD, and patients visit the doctor frequently.
Solution: Pfizer developed a remote monitoring program for COPD patients. The program uses a mobile app and spirometer to track patients’ lung function at home. The data is transmitted to a central database, where healthcare professionals monitor it. If a patient’s lung function declines, the healthcare professional can intervene.
Results: The remote monitoring program has been shown to improve patient outcomes. Patients who participated in the program had fewer hospitalizations and emergency room visits. They also had better lung function and quality of life.
Key Lessons Learned:
The remote monitoring program was successful because it was easy to use, and patients were motivated to participate.
The program also required close collaboration between healthcare professionals and patients.
The program reduced costs by reducing the number of hospital visits.
Case Study 2: Mayo Clinic’s Telemedicine Program
Problem: The Mayo Clinic is a large healthcare organization with multiple hospitals and clinics. This can make it difficult for patients to get the care they need, especially if they live in rural areas.
Solution: Mayo Clinic developed a telemedicine program that allows patients to see a doctor remotely. Patients can use a videoconferencing system to connect with a doctor at Mayo Clinic. The doctor can then assess the patient’s condition and provide treatment.
Results: The telemedicine program is effective in providing care to patients in rural areas. Patients who participated in the program were more likely to get the care they needed and were more satisfied with their care.
Key Lessons Learned:
The telemedicine program was successful because it was convenient for patients and allowed them to see a doctor quickly.
The program also required close collaboration between doctors and patients.
The program was able to reduce costs by reducing the number of travel expenses for patients.
Conclusion:
In conclusion, healthcare technology plays a pivotal role in revolutionizing the healthcare industry, as it encompasses a wide array of innovative tools, medical devices, and applications to improve patient care, medical research, and operational efficiency.
Emphasizing the synergy between the healthcare industry and health technology is crucial for driving progress and ensuring optimal outcomes for patients and healthcare providers.
By optimizing health technology integration within the healthcare industry, we can unlock the potential to enhance diagnostic accuracy, streamline treatment processes, and facilitate remote monitoring, ultimately leading to better patient outcomes and increased accessibility to quality healthcare services.
Additionally, harnessing the power of data analytics and artificial intelligence in healthcare technology can empower medical professionals to make informed decisions, discover novel treatments, and manage patient populations more effectively.
The ever-evolving landscape of health technology offers opportunities for continuous improvement and cost-effectiveness within the healthcare industry, making it imperative for stakeholders to stay updated on the latest advancements and trends.
Collaboration and knowledge-sharing between healthcare professionals, technology experts, and industry leaders are paramount to creating a seamless synergy between the two domains.
As we move forward, prioritizing investment in research and development, user-friendly health technology interfaces, and cybersecurity measures will be critical to ensure that healthcare technology continues to pave the way for transformative changes in the healthcare industry. By embracing the potential of health technology, we can foster a healthier, more connected world with improved access to cutting-edge medical solutions and a higher standard of patient care.
In recent years, the healthcare industry has witnessed a significant shift towards virtual healthcare, driven by technological advancements and the ongoing COVID-19 pandemic. Virtual healthcare, also known as telehealth or telemedicine, offers many benefits for patients and health systems. This article explores the concept of virtual healthcare, its benefits, and its implementation challenges. We will also delve into the future of healthcare, and the role virtual healthcare is set to play in transforming the delivery of medical services.
Understanding Virtual Healthcare
Virtual healthcare is a broad term that encompasses various healthcare strategies, including telehealth, telemedicine, and digital healthcare. It leverages digital infrastructure and technologies to deliver affordable medical care, knowledge, education, and training to remote locations, bridging the gap between patients and healthcare providers. The concept of virtual healthcare has been around for decades, but recent advancements in digital technologies have propelled its adoption globally.
The Benefits of Virtual Healthcare
Virtual healthcare offers a multitude of benefits for both patients and health systems. One of the most significant advantages is improved access to care, particularly for individuals living in remote or underserved areas. Virtual healthcare eliminates the barriers of distance and shortage of qualified providers, ensuring patients can receive the care they need, regardless of location.
In addition to better access, virtual healthcare also enhances the quality of patient care. Healthcare providers can make accurate clinical assessments and deliver personalized treatment plans by exchanging electronic health records and diagnostic reports. This improves patient outcomes and strengthens the patient-physician relationship as access expands and more services become available remotely.
Another key benefit of virtual healthcare is convenience. Patients no longer have to endure extended travel times or wait in crowded waiting rooms. Virtual appointments save time for both patients and doctors, allowing for more efficient resource use. Additionally, virtual healthcare facilitates the management of chronic conditions by enabling remote monitoring and timely intervention.
Moreover, virtual healthcare expands the reach of healthcare services beyond geographical boundaries. Patients can access care anywhere, whether in another city or country. This is particularly valuable for individuals who travel frequently, such as retirees, as it ensures continuity of care and coordination among healthcare providers.
From a cost perspective, virtual healthcare has the potential to significantly reduce healthcare expenses. Studies suggest it could result in billions of dollars in yearly savings. By effectively managing chronic diseases, reducing travel times, and minimizing hospital stays, virtual healthcare offers cost-effective solutions for both patients and health systems.
Furthermore, virtual healthcare empowers individuals to take charge of their health through better self-care. With the help of mobile technology and point-of-care devices, patients can monitor their health parameters and make informed decisions about their well-being. This promotes a proactive approach to healthcare and reduces the need for frequent in-person encounters.
Virtual Healthcare vs. Telehealth vs. Telemedicine
While virtual healthcare, telehealth, and telemedicine are often used interchangeably, these terms have subtle differences. Telemedicine is a subset of telehealth, which, in turn, is a subset of virtual healthcare. Telemedicine provides clinical services through two-way live audio-visual communication between healthcare providers and patients in remote locations.
Telehealth, on the other hand, encompasses a broader range of services, including telemedicine, health education, and public health administration. It aims to deliver holistic healthcare solutions beyond clinical consultations, empowering patients, and promoting public awareness.
Virtual healthcare encompasses telehealth, telemedicine, and various other health strategies. These strategies include remote patient monitoring, e-triage, guided or self-directed patient care, and replacement therapies. By embracing virtual healthcare, healthcare providers can unlock the full potential of digital technologies to revolutionize care delivery.
Challenges of Implementing Virtual Healthcare
While virtual healthcare presents numerous opportunities, it also comes with its own set of challenges. One significant challenge is the low digital literacy among specific populations, particularly in underserved areas. Many individuals struggle to understand and utilize new-age technologies, hindering their ability to benefit from virtual healthcare services. Addressing this issue requires targeted efforts to improve digital literacy and enhance tech-savviness among these populations.
Another challenge is the need for robust data connectivity and digital technologies. While India is rapidly digitalizing, areas still have limited access to reliable internet connectivity. An effective virtual healthcare system relies heavily on a solid data infrastructure, and efforts should be made to ensure that even the country’s remotest corners have access to affordable digital health technologies.
Integrating various stakeholders in the virtual healthcare ecosystem is also a significant challenge. Seamless coordination between central healthcare providers, remote healthcare facilities, labs, pharmacies, and supporting staff is essential for quality healthcare. Healthcare organizations need effective organizational strategies to implement virtual healthcare models and overcome integration challenges.
Clinics, hospitals, and healthcare providers must develop robust organizational strategies to deliver virtual healthcare effectively. Providing quality healthcare through virtual means can be challenging without proper planning and implementation. It is crucial to establish virtual solid healthcare models that align with the unique needs of each healthcare provider and ensure a seamless experience for patients and healthcare professionals.
The Future of Healthcare: Embracing Virtual Healthcare
The COVID-19 pandemic has highlighted the importance of virtual healthcare in delivering medical services remotely, even in areas with adequate access to quality healthcare. Governments and healthcare organizations worldwide have recognized the potential of virtual healthcare and have taken steps to promote its adoption. For example, India has launched the National Digital Health Mission to connect healthcare services and make them digitally accessible.
As we look toward the future, virtual healthcare is set to play a pivotal role in transforming the delivery of medical care. The global market size of virtual healthcare is projected to reach a staggering $95 billion by 2026, reflecting the increasing acceptance and adoption of virtual healthcare solutions. Healthcare providers must embrace these technologies swiftly and adapt to the changing healthcare landscape.
In conclusion, virtual healthcare offers many benefits and opportunities for patients and health systems. It improves access to care, enhances the quality of patient care, and reduces healthcare costs. However, implementing virtual healthcare comes with challenges, including low digital literacy, connectivity issues, integration challenges, and organizational strategies. Nevertheless, the future of healthcare lies in embracing virtual healthcare and leveraging digital technologies to make healthcare accessible to all. By embracing virtual healthcare, we can revolutionize healthcare delivery and ensure a healthier future for all.
The healthcare industry is constantly evolving, with new technologies and innovations driving significant advancements in patient care. One such technology that has gained considerable attention is blockchain. Blockchain can revolutionize healthcare by improving security, privacy, and accessibility while placing patients at the center of all operations. In this article, we will explore the concept of blockchain, its application in the medical industry, and the companies leading the way in this transformative field.
Understanding Blockchain: A Game-Changing Technology
Blockchain is a distributed system that generates and stores data records in a digital ledger. It consists of interconnected “blocks” of information shared, changed, or accessed on a peer-to-peer network. Each device on the blockchain system generates identical blocks, ensuring data parity and easy identification of changes. This decentralized approach, coupled with hashing, creates an immutable and secure chain of blocks.
Hashing assigns a unique identifier to each block based on its contents. Any alterations to the data within a block would result in a change in its hash. As blocks are stored in chronological order and reference the preceding block’s hash, attempting to manipulate the data of one block would be immediately detected by subsequent blocks. This ensures the integrity and reliability of the information stored in the blockchain.
Blockchain’s Impact on the Medical Industry
The healthcare industry faces numerous challenges, including the secure sharing and access of sensitive patient data. Blockchain technology provides a solution by enabling finely customizable openness while maintaining the highest security standards. Let’s explore how blockchain is transforming the medical industry through the innovations of pioneering companies.
Chronicled: Facilitating Interoperability and Collaboration
Chronicled, a company utilizing blockchain technology through its MediLedger Network, aims to bring trading partners and medical institutions closer together. By ensuring secure and seamless communication, blockchain allows for more significant innovation, accountability, and industry development. Automation of processes and improved trust among all parties involved are just a few benefits that Chronicled’s blockchain solution provides.
Curisium: Streamlining Contract Management
Curisium, acquired by HealthVerity in 2020, employs blockchain to streamline rebate negotiation and contract management. The complexity and time-consuming nature of contract negotiations in healthcare can be alleviated through Curisium’s platform. This innovative solution enables providers and payers to engage in efficient and secure contracting arrangements, paving the way for collaboration and cost savings.
Ever: Transforming Thailand’s Medical Landscape
Ever, a revolutionary company founded in 2017, has modernized Thailand’s medical landscape through its blockchain-based EHR solution. With over 170 hospitals and 5 million patients connected, Ever’s network ensures secured and trustless data exchanges, extensive data collection and analysis, and machine learning and artificial intelligence utilization. By placing a strong emphasis on security and communication, Ever has created a flexible and scalable blockchain foundation for the future of healthcare.
Patientory: Empowering Patients with Data Control
Patientory leverages blockchain’s transparency and privacy features to develop patient-centric applications and services. By securely storing and sharing up-to-date patient histories and data, Patientory gives individuals more control over their well-being. The company’s innovative solutions include pandemic tracking, secure communication with healthcare professionals, and real-time access to verified healthcare information.
The Promising Future of Blockchain in Healthcare
Blockchain technology’s potential to revolutionize healthcare is immense. According to BIS Research, Its implementation can save the industry over $100 billion annually by 2025. As the healthcare sector embraces blockchain, the possibilities for growth and innovation are endless.
Companies like Chronicled, Curisium, Ever, and Patientory are just the beginning of a blockchain revolution in healthcare. By adopting this technology, the industry can enhance security, streamline processes, and improve patient outcomes.
The Growing Blockchain in Healthcare Market
The blockchain in the healthcare market is poised for significant growth, with a forecasted market size of USD 19.52 billion by 2028, representing a CAGR of 52.48% from 2023 to 2028. North America stands as the fastest-growing and most significant market in this sector, driven by regulatory requirements, the need for enhanced security, and rising healthcare costs.
Major Players Driving the Market
Several major players are leading the blockchain revolution in the healthcare market, including IBM Corporation, Microsoft Corporation, Patientory Inc., Guardtime Federal, and Hashed Health. These companies leverage blockchain technology to develop cutting-edge solutions that address the industry’s challenges and drive innovation.
Segmentation and Application of Blockchain in Healthcare
Blockchain technology can transform healthcare aspects, including clinical data exchange, billing management, claims adjudication, and supply chain management. By bringing transparency and efficiency to these complex transactions, blockchain enhances collaboration between stakeholders and ensures the integrity of health-related data.
Market Trends and Opportunities
Counterfeit proofing and data protection are key market trends in the blockchain in the healthcare industry. Blockchain’s ability to secure and share health data effectively addresses the increasing problem of counterfeit medicines. By sharing information across the blockchain network, stakeholders can mitigate the risk of counterfeit or substandard drugs, ensuring patient safety.
North America is expected to witness the highest growth in the blockchain in the healthcare market. The implementation of regulations, the need to safeguard patient data, and rising healthcare costs are driving the adoption of blockchain technology in the region. The United States, in particular, is investing in blockchain solutions to improve drug supply chain security and enhance patient care coordination.
The healthcare industry faces the challenge of building a trustworthy system to protect patient data effectively. Blockchain technology offers a solution by providing transparency, security, and immutability to healthcare transactions. However, there is a need for increased awareness and understanding of blockchain’s functionality to facilitate its adoption in the healthcare sector.
The COVID-19 pandemic has further accelerated the adoption of blockchain technology in healthcare. The fast-paced nature of the crisis has highlighted the importance of secure and efficient data management, leading to increased investment in blockchain-based solutions.
Conclusion
Blockchain technology is poised to revolutionize the healthcare industry, offering improved security, privacy, and accessibility. Companies like Chronicled, Curisium, Ever, and Patientory are leading the way in harnessing blockchain’s potential to transform healthcare processes and enhance patient outcomes.
As the blockchain in the healthcare market continues to grow, the industry must embrace this transformative technology to drive innovation and improve patient care. By adopting blockchain solutions, healthcare organizations can enhance data security, streamline processes, and unlock new possibilities for collaboration. The future of healthcare is data-driven, and blockchain is at the forefront of this revolution.
Note: This article is for informational purposes only and does not constitute medical or financial advice. The mentioned companies are for illustrative purposes and are not affiliated with the author or this article.
The healthcare industry continues to experience remarkable advancements driven by the rapid evolution of technology. As we move into 2024 and beyond, the future of health tech holds even more significant potential for transforming patient care, enhancing accessibility, and reshaping the healthcare landscape. According to a recent report by Frost & Sullivan, the global healthcare IT market is expected to reach $552.8 billion by 2026, growing at a compound annual growth rate (CAGR) of 7.6% during the forecast period.
This article will explore the top trends and innovations in health tech poised to revolutionize healthcare in the coming years, bringing hope and optimism to healthcare professionals.
1. Big Data: Transforming Healthcare Delivery
Big data continues revolutionizing healthcare in 2024, providing unprecedented capabilities for storing, processing, and analyzing vast amounts of patient data. This wealth of information holds immense potential to enhance healthcare outcomes through personalized treatment plans, real-time health monitoring, epidemic prediction, and cost reduction. According to the International Data Corporation (IDC), the Big Data analytics segment in healthcare is now valued at approximately $68.03 billion.
Healthcare providers increasingly utilize big data to leverage remote monitoring devices and applications, allowing continuous patient observation without frequent hospital visits. This approach improves patient convenience and enables early intervention and more proactive healthcare management. Moreover, advanced data analytics offer deeper insights, helping healthcare organizations make data-driven decisions, streamline operations, and optimize resource allocation to meet patient needs better.
2. Virtual Reality: Revolutionizing Medical Training and Treatment
In 2024, virtual reality (VR) technology continues to make significant strides in the healthcare industry, providing innovative medical training and treatment solutions. Medical professionals, from students to specialists, use VR more extensively to enhance their practical experience. With VR, they can simulate complex surgical procedures, reducing the risk of errors and improving preparedness for high-stakes operations. This immersive training allows healthcare workers to practice in safe, controlled environments before applying their skills in real-life scenarios.
Beyond training, VR has proven valuable in helping individuals with developmental disorders adapt to real-life situations and manage phobias. VR therapy programs, such as Psious, have been widely adopted by prestigious institutions across over 90 countries, offering effective adjuncts to traditional therapy. These programs assist individuals in overcoming fears, reducing anxiety, and practicing mindfulness techniques, all within immersive environments that enhance engagement and therapeutic outcomes.
Looking ahead, VR is playing an even more significant role in mental health treatment, offering more personalized and immersive therapeutic experiences. With the growing focus on mental health and the World Health Organization (WHO) highlighting the continued effects of misinformation on public health, VR is being leveraged to combat the “infodemic” by promoting accurate health education and debunking myths. As VR technology evolves, its potential in medical education and treatment continues to expand, transforming how healthcare is delivered globally.
In 2024, financial technology (FinTech) integration into healthcare systems is accelerating, providing powerful tools to streamline financial processes and reduce costs. As healthcare teams adopt FinTech solutions, they improve service delivery, gain real-time access to economic data, and boost operational efficiency. These innovations reshape how healthcare organizations manage financial workflows and interact with patients and insurers.
FinTech in healthcare now encompasses various services, including insurance management, digital payments, billing automation, capital-raising, and credit services. By leveraging these technologies, healthcare organizations can optimize payment plans, enhance financial management, and facilitate seamless data sharing with external stakeholders like insurance companies, improving overall transparency and coordination.
The healthcare industry’s adoption of peer-to-peer lending, mobile payments, and blockchain technology continues to gain traction. Blockchain, in particular, helps secure transactions and ensure data integrity, reduces the risk of fraud, and enables secure, efficient patient records and payment exchanges. These technologies improve transparency and security and speed up the payment process, benefitting healthcare providers and patients by making financial transactions smoother and more reliable.
FinTech integration in healthcare is poised to play a pivotal role in the industry’s future, offering new opportunities to enhance cost management, improve patient satisfaction, and foster innovation across financial processes.
4. Remote Patient Monitoring: Transforming Healthcare at Home
In 2024, Remote Patient Monitoring (RPM) will continue to expand rapidly, becoming a core component of modern healthcare delivery. The pandemic has accelerated its growth and shows no signs of slowing. RPM systems enable healthcare providers to collect, analyze, and act on patient data without requiring in-person visits. This approach reduces the burden on hospitals and clinics while supporting more proactive and continuous healthcare management.
RPM systems typically involve wearable devices that monitor vital signs, activity levels, and other critical health metrics. These devices play a crucial role in managing chronic conditions such as diabetes, hypertension, and heart disease, providing real-time data that can alert healthcare professionals to potential issues before they become serious. In addition, they assist in medication adherence by sending reminders and enabling seamless data transmission to healthcare providers. As of 2024, over 30 million patients are using remote monitoring systems, with the global RPM market expected to surpass $1.7 billion.
The widespread adoption of RPM enhances patient care and addresses broader challenges in the healthcare system, including the growing nursing shortage. By allowing patients to stay connected with healthcare professionals remotely, wearable health devices reduce the strain on frontline clinicians, enhance workflow efficiency, and enable healthcare teams to focus on the most urgent cases. This technology is precious for managing aging populations and chronic diseases, supporting independent living while ensuring continuous care.
As RPM technology advances, it is increasingly integrated with AI-driven analytics, enabling healthcare providers to make more informed, data-driven decisions that improve patient outcomes and overall system efficiency.
In 2024, artificial intelligence (AI) has solidified its role as a transformative force in healthcare, significantly enhancing decision-making processes. AI-powered systems enable machines to analyze vast amounts of medical data, predict outcomes, and provide real-time support to clinicians. This technology is revolutionizing healthcare by making it more efficient, personalized, and accurate.
The global AI in healthcare market has continued its rapid growth, reaching new heights since its 2020 valuation of $6.7 billion. With a projected compound annual growth rate (CAGR) of 41.8% from 2021 to 2028, AI’s influence is expanding across various aspects of healthcare. By 2024, AI applications will not only support clinical decision-making. Still, they will also be widely used to predict patient responses to treatments, detect early signs of medical deterioration, and flag potential infections by analyzing remotely monitored vital signs.
One notable example of AI in action is the Ochsner Health System, which employs an AI tool to predict the likelihood of a patient experiencing cardiac or respiratory arrest. This system has enabled clinicians to intervene earlier, significantly improving patient outcomes. Such predictive analytics tools are becoming increasingly common in hospitals and clinics, helping to reduce medical errors, enhance patient safety, and streamline care delivery.
6. Telemedicine: Redefining Access to Healthcare
Telemedicine continues to redefine healthcare access, following exponential growth during the pandemic. What began as a necessity for remote care has now transformed into a cornerstone of modern healthcare delivery. Telemedicine has revolutionized how patients receive care by minimizing the need for in-person visits and offering convenient virtual consultations. While initially focused on acute care, telemedicine has expanded into chronic disease management, mental health services, and specialized fields such as cardiology and dermatology.
Telemedicine offers significant benefits, particularly for individuals in remote or underserved areas with limited access to healthcare services. Patients with chronic conditions, such as diabetes and hypertension, can now receive continuous care through remote monitoring devices and regular virtual check-ins with their healthcare providers. This approach improves long-term patient outcomes, reduces hospital readmissions, and lowers healthcare costs by preventing unnecessary emergency room visits.
Major corporations have also recognized telemedicine’s potential. Best Buy and Amazon, for example, have made strategic acquisitions and investments in telehealth platforms to expand their healthcare offerings. Best Buy acquired Current Health, a company specializing in remote patient monitoring, while Amazon launched Amazon Clinic, which offers virtual consultations and prescription services. These developments indicate the growing importance of telemedicine in the broader healthcare ecosystem.
In 2024, telemedicine will also address critical mental health needs, providing patients with convenient access to therapy and counseling services. As mental health concerns rise globally, virtual platforms are ensuring that individuals receive timely and personalized care regardless of geographical barriers.
Telemedicine is poised to be more significant in delivering accessible, cost-effective, patient-centered care. With advancements in AI-powered diagnostics, wearable health tech, and improved broadband access in rural areas, telemedicine is expanding its reach and scope. The combination of AI and telemedicine enables healthcare providers to analyze patient data in real time, offering more accurate diagnoses and personalized treatment plans during virtual consultations.
Conclusion: Embracing the Future of Healthtech
In 2024, the future of health tech holds immense promise for revolutionizing healthcare delivery, improving patient outcomes, and expanding accessibility. The healthcare industry is on the cusp of significant advancements driven by big data analytics, virtual reality (VR), AI, FinTech solutions, and remote patient monitoring (RPM).
Technological innovations like artificial intelligence (AI) and telemedicine are at the forefront of this transformation. AI-powered predictive analytics is helping healthcare providers anticipate health trends, detect diseases early, and personalize treatments based on individual patient data. At the same time, telemedicine is redefining access to healthcare by enabling virtual consultations, particularly for underserved populations, and improving care continuity for patients with chronic conditions.
The opportunities in health tech are vast, and the future is now. According to a recent report by McKinsey & Company, the global healthcare market is expected to reach $10 trillion by 2025, driven by factors such as an aging population, rising healthcare costs, and increasing demand for personalized care.
Healthcare organizations that harness the power of technology today will be better equipped to create a future where equitable, high-quality healthcare is accessible to all, regardless of geographic or socioeconomic barriers. The healthcare industry is at the threshold of a tech-driven revolution, and 2024 marks a pivotal moment in shaping the future of global healthcare.
In today’s digital age, healthcare has become more accessible and convenient through telemedicine. Telemedicine, also known as telehealth, is a revolutionary approach allowing patients to receive healthcare services remotely without needing in-person office visits. This article aims to provide a comprehensive understanding of telemedicine and telehealth, their benefits, and the various types of care they offer.
What is Telemedicine?
Telemedicine refers to providing healthcare services through virtual means, such as video calls, phone consultations, secure messaging, and remote monitoring. It allows patients to consult with their healthcare providers from the comfort of their homes, using devices like computers, tablets, or smartphones with internet access.
The concept of telemedicine has been around for decades, but its popularity has skyrocketed recently, especially with the global COVID-19 pandemic. Telemedicine offers a wide range of healthcare services, from routine check-ups to specialized care, making it a convenient and efficient option for patients of all ages.
Types of Telemedicine Care
Telemedicine offers a variety of specialized care options, catering to different healthcare needs. Some of the common types of care that can be provided through telemedicine include:
Primary Care: Telemedicine allows patients to have virtual appointments with their primary care physicians. These appointments can involve discussions about general health concerns, medication management, and preventive care.
Specialty Care: Telemedicine enables patients to access specialized care from various medical specialists, such as dermatologists, psychiatrists, pediatricians, and more. This type of care is especially beneficial for individuals who live in remote areas with limited access to specialized healthcare services.
Mental Health Treatment: Telemedicine has revolutionized mental health care by providing online therapy, counseling sessions, and medication management. Patients can conveniently seek help for mental health conditions from the comfort of their own homes, reducing the stigma and barriers associated with traditional in-person visits.
Urgent Care: Telemedicine offers virtual critical care services for non-life-threatening conditions like colds, coughs, sinus infections, and minor injuries. Patients can receive prompt medical advice and prescriptions without the need to visit an emergency room or urgent care facility.
Chronic Disease Management: Telemedicine is crucial in managing chronic conditions like diabetes, hypertension, and asthma. Patients can track their vital signs through remote monitoring devices and share them with their healthcare providers to ensure adequate disease management.
Post-Surgical Follow-up: Telemedicine allows healthcare providers to monitor patients’ recovery progress after surgery remotely. This reduces the need for frequent in-person visits and enables healthcare professionals to promptly address any concerns or complications.
Health Education and Coaching: Telemedicine platforms often provide educational resources and coaching services to help patients manage their overall health and well-being. These resources can include personalized diet plans, exercise routines, stress management techniques, and more.
Benefits of Telemedicine
Telemedicine offers numerous benefits for both patients and healthcare providers. Let’s explore some of the critical advantages of utilizing telemedicine for healthcare services:
1. Convenience and Accessibility
One of the most significant benefits of telemedicine is the convenience it provides. Patients can schedule appointments at a time that works best for them, eliminating the need for lengthy commutes and waiting room delays. Telemedicine also ensures accessibility for individuals who live in remote areas, have limited mobility, or lack reliable transportation.
2. Improved Healthcare Access
Telemedicine breaks down barriers to healthcare access, particularly for underserved populations. Patients who previously faced challenges accessing healthcare services, such as those in rural areas or with disabilities, can now easily connect with healthcare professionals through telemedicine.
3. Time and Cost Savings
Telemedicine saves patients valuable time by eliminating the need for travel and reducing wait times. It also eliminates associated costs such as transportation expenses and childcare arrangements. Additionally, telemedicine eases the burden on healthcare facilities and potentially lowers healthcare costs for patients and providers.
4. Reduced Exposure to Illnesses
In the wake of the COVID-19 pandemic, telemedicine has gained immense popularity due to its ability to minimize exposure to contagious diseases. Patients can receive necessary healthcare services without the risk of coming into contact with other sick individuals in waiting rooms or healthcare facilities.
5. Continuity of Care
Telemedicine enables seamless continuity of care, especially for individuals with chronic conditions. Patients can regularly communicate with their healthcare providers, receive medication refills, and track their progress, ensuring their healthcare needs are consistently met.
6. Access to Specialists
Telemedicine bridges the gap between patients and specialists who may be far away. Patients can consult with renowned experts and receive specialized care without traveling long distances, saving time and money.
Choosing the Right Telemedicine Platform
Selecting the right telemedicine platform is crucial for healthcare providers to deliver effective and efficient virtual care. Here are some key factors to consider when choosing a telemedicine platform:
Reputation and Security: Ensure your chosen platform has a strong reputation and adheres to strict security measures to protect patient information and maintain privacy.
Ease of Use: Look for a user-friendly and intuitive platform for both healthcare providers and patients. The platform should have clear instructions and a simple interface to facilitate seamless communication.
Features and Functionality: Consider the specific parts and functionalities the platform offers. Depending on your practice’s requirements, it should provide the necessary tools for virtual consultations, secure messaging, file exchange, and remote monitoring.
Integration with Existing Systems: If you already have an electronic health record (EHR) system or other healthcare technology, ensure the telemedicine platform can seamlessly integrate with your existing systems to streamline workflows.
Patient Experience: The platform should prioritize a positive patient experience, with easy appointment scheduling, clear instructions for virtual visits, and user-friendly interfaces for patients of all technological abilities.
Payment Structure: Understand the payment structure of the telemedicine platform, including any fees or subscriptions for healthcare providers. Consider whether the platform aligns with your practice’s financial goals and reimbursement models.
Top Telemedicine Platforms
Now that we have explored the benefits and considerations of telemedicine, let’s take a closer look at some of the top telemedicine platforms available for healthcare providers:
Teladoc: Teladoc is one of the pioneers in the telehealth industry, offering on-demand virtual care services in various specialties. It provides flexible enrollment options for healthcare providers and offers a wide range of services, including primary care, mental health treatment, and specialty care.
Sesame Care: Sesame Care is a telemedicine platform that provides affordable and transparent healthcare services. It offers a user-friendly interface for healthcare providers and patients, flexible scheduling options, and various specialty areas.
PlushCare: PlushCare is a telemedicine platform that offers virtual appointments with trusted doctors and specialists. It provides comprehensive primary care services, mental health treatment, and urgent care options. PlushCare emphasizes a patient-centered approach and ensures quick access to care.
These platforms are just a few examples of the many telemedicine options available to healthcare providers. It’s essential to thoroughly research and compare different platforms to find the best fit for your practice’s needs and goals.
The Future of Telemedicine
Telemedicine has already transformed the healthcare landscape, and its potential for continued growth is immense. As technology advances and healthcare providers embrace virtual care, telemedicine is expected to become an integral part of the healthcare system.
The widespread adoption of telemedicine has the potential to improve healthcare outcomes, increase patient satisfaction, and reduce healthcare costs. It enables patients to access care more conveniently and healthcare providers to reach a larger patient population.
However, it’s important to note that telemedicine does not replace all in-person healthcare services. Certain medical conditions and procedures still require physical examinations and interventions. Telemedicine should be used with traditional in-person care to provide comprehensive healthcare services.
In conclusion, telemedicine offers many benefits and opportunities for patients and healthcare providers. It has revolutionized healthcare delivery by providing convenient access to care, reducing barriers, and improving overall patient experience. As telemedicine continues to advance, it will play an increasingly significant role in shaping the future of healthcare.
Always consult with your healthcare provider to determine if telemedicine suits your specific healthcare needs. Embrace the potential of telemedicine and experience the convenience and quality of virtual healthcare services.
Disclaimer: The information in this article is for informational purposes only and should not be considered medical advice. Please consult with a qualified healthcare professional for personalized medical advice and treatment.
Medical devices play a crucial role in patient care, encompassing a wide range of technologies that contribute to diagnosing, treating, and monitoring diseases and injuries. These devices, often powered by electricity, require adherence to strict safety standards and procedures to ensure patient and healthcare provider safety. This comprehensive guide will explore the various aspects of medical devices, including their definition, types, classifications, and safety regulations.
Table of Contents
What Are Medical Devices?
Types of Medical Devices
Classification of Medical Devices
Safety Standards and Regulations
Advancements in Medical Device Design
The Importance of Testing
Emerging Technologies in the Medical Device Industry
Examples of Medical Devices
Challenges and Future Trends
Conclusion
1. What Are Medical Devices?
Medical devices are appliances, instruments, materials, or articles used for medical purposes. They can diagnose, prevent, monitor, treat, or alleviate diseases or injuries. These devices may also investigate, replace, or modify physiological processes in the human body. Medical devices encompass various technologies, including software essential for their intended purpose.
Medical devices’ primary objective is to improve patient care and enhance healthcare outcomes. They can be standalone devices or used in combination with other equipment. While some medical devices achieve their intended action through pharmacological, immunological, or metabolic means, others may assist in their function. To ensure the safety and efficacy of medical devices, universal standards and norms have been established, and compliance with these standards is crucial.
2. Types of Medical Devices
Medical devices can be classified into several categories based on their intended use and mode of operation. Here are the main types of medical devices:
Active Medical Devices
Active medical devices rely on electrical energy or another power source, excluding the human body or gravity. These devices play an active role in diagnosing, treating, or monitoring diseases or injuries. Examples of active medical devices include pacemakers, infusion pumps, and defibrillators.
Active Implantable Medical Devices
Active implantable medical devices are intended to be entirely or partially inserted into the human body, either surgically or medically. After the procedure, these devices remain in the body and require a power source. Examples of active implantable medical devices include implantable defibrillators and neurostimulators.
In Vitro Diagnostic Medical Devices
In vitro diagnostic medical devices are used to examine specimens derived from the human body. These devices provide information about physiological or pathological states, congenital abnormalities, safety and compatibility with potential recipients, or the monitoring of therapeutic measures. Examples of in vitro diagnostic medical devices include pregnancy test kits and blood glucose meters.
3. Classification of Medical Devices
Medical devices are classified into different categories based on their risk level. The classification determines the regulatory requirements and scrutiny for their approval and marketing. Here are the four main classes of medical devices:
Class I: Low Risk
Class I medical devices pose the lowest risk to patients and healthcare providers. These devices are typically simple in design and do not require invasive procedures. Examples of Class I medical devices include tongue depressors and thermometers.
Class II: Low to Moderate Risk
Class II medical devices pose a slightly higher risk than Class I devices. They may require a more complex design and involve minimally invasive procedures. Examples of Class II medical devices include hypodermic needles and powered wheelchairs.
Class III: Moderate to High Risk
Class III medical devices pose a significant risk to patients and may require invasive procedures. These devices are often complex in design and are used in critical medical interventions. Examples of Class III medical devices include implantable defibrillators and heart valves.
Class IV: High Risk
Class IV medical devices are the highest-risk category, reserved for devices with potentially life-threatening consequences. These devices undergo rigorous scrutiny and must demonstrate exceptional safety and efficacy. Examples of Class IV medical devices include advanced surgical implants and artificial organs.
4. Safety Standards and Regulations
Safety is a paramount concern in the development and use of medical devices. Several international standards and regulations have been established to ensure these devices’ safety and efficacy. Compliance with these standards is essential for the approval and marketing of medical devices. Here are some of the critical safety standards and regulations:
ISO 13485: Quality Management Systems for Medical Devices
ISO 13485 is an internationally recognized standard that specifies the requirements for a quality management system for medical device manufacturers. Compliance with this standard ensures that manufacturers consistently meet customer and regulatory requirements, focusing on the safety and effectiveness of their medical devices.
IEC 60601: Medical Electrical Equipment Safety Standards
IEC 60601 is a series of technical standards that outline the safety and performance requirements for medical electrical equipment. These standards cover various aspects, including electrical safety, electromagnetic compatibility, and protecting patients and healthcare providers from potential hazards associated with medical devices.
FDA Regulations (United States)
The Food and Drug Administration (FDA) regulates medical devices in the United States. Depending on their risk classification, manufacturers must comply with the FDA’s premarket notification or approval process. The FDA ensures that medical devices meet safety and efficacy standards before being marketed and sold in the United States.
CE Marking (European Union)
In the European Union, medical devices must bear the CE marking, indicating compliance with the essential requirements of the European Medical Device Directives. The CE marking demonstrates that a medical device meets the necessary safety, health, and environmental protection standards for its intended use.
5. Advancements in Medical Device Design
The field of medical device design is constantly evolving, driven by advances in technology and the need for improved patient care. Here are some noteworthy advancements in medical device design:
Internet of Medical Things (IoMT)
The Internet of Medical Things (IoMT) refers to the network of medical devices and applications connected to healthcare information systems. IoMT enables remote monitoring, real-time data analysis, and enhanced communication between healthcare providers and patients. This technology has the potential to revolutionize healthcare delivery and improve patient outcomes.
Wearable Medical Devices
Wearable medical devices like smartwatches and fitness trackers have recently gained popularity. These devices can monitor vital signs and physical activity and provide real-time health data to users. Wearable medical devices offer new convenience and accessibility in healthcare monitoring.
Artificial Intelligence and Machine Learning
Artificial intelligence (AI) and machine learning (ML) technologies are being integrated into medical devices to enhance diagnostic accuracy, predict treatment outcomes, and improve patient care. AI-powered medical devices can analyze large amounts of data and provide valuable insights to healthcare professionals, leading to more personalized and effective treatments.
3D Printing
3D printing has revolutionized the manufacturing of medical devices, allowing for greater customization and faster prototyping. This technology enables the production of complex structures and patient-specific implants, enhancing the precision and efficacy of medical interventions.
6. The Importance of Testing
Testing is vital in ensuring medical device safety, efficacy, and compliance. Before a medical device can be approved, it must undergo rigorous testing to evaluate its performance, reliability, and security. Testing protocols may include mechanical, electrical, biocompatibility, and usability testing. These tests help identify potential risks, ensure proper functioning, and validate the device’s compliance with regulatory standards.
7. Emerging Technologies in the Medical Device Industry
The medical device industry is continually evolving, driven by emerging technologies that have the potential to revolutionize healthcare. Here are some of the emerging technologies in the medical device industry:
Nanotechnology
Nanotechnology involves manipulating materials at the nanoscale to create new functionalities and applications. In the medical device industry, nanotechnology offers possibilities for targeted drug delivery, improved imaging techniques, and advanced diagnostics.
Robotics and Minimally Invasive Surgery
Robotic-assisted surgery and minimally invasive techniques transform surgical procedures, enabling greater precision, reduced invasiveness, and faster recovery times. Robotic surgical systems provide surgeons with enhanced control and visualization, improving patient outcomes.
Telemedicine and Remote Monitoring
Telemedicine and remote monitoring technologies allow healthcare providers to deliver care remotely, improving access to healthcare services and reducing the need for in-person visits. These technologies enable real-time communication between patients and healthcare professionals, facilitating timely interventions and proactive management of health conditions.
Bioprinting and Organ Transplantation
Bioprinting involves fabricating three-dimensional structures using living cells and biomaterials. This technology holds immense potential for tissue engineering and organ transplantation. Bioprinted organs and tissues can address the shortage of donor organs and offer personalized solutions for needy patients.
8. Examples of Medical Devices
Medical devices encompass a vast array of technologies and products. Here are some examples of medical devices across different categories:
Diagnostic Devices
Blood glucose meters
ECG machines
Ultrasound scanners
MRI machines
X-ray machines
Therapeutic Devices
Insulin pumps
Pacemakers
Ventilators
Dialysis machines
Surgical lasers
Imaging Devices
CT scanners
PET scanners
Mammography machines
Endoscopy systems
Ophthalmoscopes
Assistive Devices
Hearing aids
Wheelchairs
Prosthetic limbs
Mobility scooters
Orthopedic braces
9. Challenges and Future Trends
The medical device industry faces several challenges, including regulatory complexities, cost pressures, and the need for continuous innovation. However, the future of medical devices holds great promise. Here are some key trends and challenges in the medical device industry:
Personalized Medicine
Advancements in genomics and molecular diagnostics are paving the way for personalized medicine. Medical devices will be crucial in delivering customized treatments and therapies tailored to individual patient’s genetic makeup and health profiles.
Cybersecurity and Data Privacy
Cybersecurity and data privacy are critical concerns as medical devices become increasingly connected and reliant on digital systems. Ensuring the security of patient data and protecting medical devices from cyber threats will be paramount in the future.
Regulatory Harmonization and Global Collaboration
Harmonizing regulatory frameworks and promoting global collaboration in evaluating and approving medical devices will streamline market access and facilitate innovation. International cooperation can help ensure the safety and effectiveness of medical devices while promoting access to new technologies.
Advanced Sensing and Monitoring Technologies
Advancements in sensing and monitoring technologies, such as biosensors and wearable devices, will enable real-time health monitoring and early detection of diseases. These technologies will empower individuals to take proactive steps toward managing their health.
10. Conclusion
Medical devices are vital in modern healthcare, enabling better diagnosis, treatment, and monitoring of diseases and injuries. From simple diagnostic tools to complex surgical systems, medical devices continue to evolve and improve patient care. Compliance with safety standards and regulations, along with advancements in design and technology, will shape the future of medical devices. As the medical device industry continues to innovate, it holds the potential to transform healthcare and improve the lives of millions worldwide.
Mechanized farming has revolutionized the agricultural industry, bringing numerous benefits and advancements to farmers worldwide. This article will explore the importance of mechanization in agriculture, its historical context, and its advantages. We will explore how improved techniques, commercialization, nullification of labor shortages, increased crop production, and higher farm income are all outcomes of mechanized farming. So, let’s dive in and discover everything you need about mechanized agriculture.
The Importance of Mechanization in Agriculture
Mechanization is crucial in agricultural crop production, especially in developing countries. It addresses the challenges posed by limited farm power availability, historically a source of poverty in regions like sub-Saharan Africa. By increasing the power supply to agriculture, mechanization allows for the timely completion of tasks, cultivation of larger areas, and higher crop yields, all while conserving natural resources. Moreover, using environmentally friendly technologies enables farmers to produce crops more efficiently with reduced power consumption.
Sustainable agricultural mechanization also contributes significantly to developing value chains and food systems. It enhances post-harvest, processing, and marketing activities, making them more efficient, effective, and environmentally friendly. By adopting mechanization practices that align with the needs of farmers, including women who contribute significantly to farming communities, the labor burden can be reduced, thereby improving their livelihoods.
ABrief History of Agricultural Mechanization
Throughout the 20th century, mechanization has transformed the agricultural industry globally. In India, for instance, the Innovations in Technology Dissemination (ITD) component of the World Bank-funded National Agricultural Technology Project (NATP) was introduced in the late 1990s as a pilot initiative. This project aimed at testing new institutional arrangements and bottom-up planning procedures to enhance technology dissemination and make it more farmer-driven and accountable. The pilot program’s success led to the introduction of the Agricultural Technology Management Agency (ATMA) scheme in 2005-06, which provided greater autonomy at the district level to coordinate extension activities and promote integrated extension service delivery.
Over time, the ATMA scheme has undergone revisions to further its objectives. These include providing innovative and autonomous institutions, encouraging multi-agency extension strategies, ensuring an integrated extension delivery mechanism, adopting a group approach to agricultural extension, facilitating program convergence, addressing gender concerns, and promoting sustainability through beneficiary contribution.
Advantages of Mechanized Farming
1. Improved Techniques
Mechanization has brought about significant improvements in agricultural techniques. Land reclamation has become more efficient, reduced soil erosion, and optimized irrigation systems. Cultivators attached to tractors help smooth out the soil, fill in ditches, and remove weeds, thereby increasing the amount of usable land and preventing soil erosion. Additionally, mechanized irrigation systems enable targeted watering of plant roots, reducing water wastage and improving overall efficiency.
2. Commercialization
The advent of mechanization has shifted from subsistence farming to commercial agriculture. The increased productivity and crop yields offered by mechanization have made it possible to produce more food on a larger scale, allowing domestic consumption and export. Commercial agriculture brings economic benefits to farmers and contributes to overall food security.
3. Nullifies Effects of Labor Shortages
Labor shortages in rural areas, caused by migration to urban centers, have become less problematic due to agricultural mechanization. Machines can now perform various tasks that previously required manual labor. This not only addresses the labor shortage but also reduces the amount of time and effort needed to make farms operational.
4. Increased Crop Production and Land Utilization
Mechanization has paved the way for increased crop production by making challenging land arable and improving land utilization. Rugged terrains that were once considered unusable can now be cultivated with the help of machines. This expansion of usable land, combined with the efficiency of mechanized farming practices, allows for growing a wider variety of crops and significantly higher yields.
5. Higher Farm Income
One of the most significant advantages of mechanized farming is the potential to increase farm income. Mechanization saves time and reduces the need for extended periods of paid labor. Additionally, the higher crop yields achieved through mechanized practices increase income. This, in turn, allows farms to operate on a larger scale, reaching global markets and expanding their profitability.
Conclusion
Mechanized farming has revolutionized the agricultural industry, bringing numerous advantages and advancements. Improved techniques, commercialization, nullification of labor shortages, increased crop production, and higher farm income are just a few of the benefits that mechanization offers. As we move forward into the 21st century, the role of mechanized farming will continue to evolve, driving further innovations and improvements in the agriculture sector. Embracing sustainable mechanization practices will be crucial for achieving food security, reducing poverty, and improving farmers’ livelihoods worldwide.
In recent years, as our world faces increasing challenges related to food security, environmental sustainability, and rapid urbanization, a transformative trend has emerged that holds the promise of addressing these pressing issues: Urban Farming.
From rooftops adorned with lush greenery to abandoned warehouses transformed into thriving agricultural hubs, urban farming has become a beacon of hope for sustainable food production in cities across the globe.
This innovative practice reconnects urban dwellers with nature and presents many benefits, from reduced carbon footprints to improved community health and empowerment.
In this comprehensive article, we will delve into all you need to know about urban farming – its principles, methods, benefits, and the exciting potential it holds for shaping the future of agriculture and urban living.
Definition of Urban Farming: Urban farming refers to cultivating, producing, and harvesting food and other agricultural products within a city’s or urban environment’s confines. It uses various spaces such as rooftops, balconies, vacant lots, community gardens, and indoor settings to grow crops and raise animals.
The primary objectives of urban farming include increasing local food production, promoting sustainability, reducing the carbon footprint of food distribution, and fostering community engagement with agriculture. Urban farming plays a crucial role in enhancing food security, improving access to fresh produce, and connecting urban dwellers with the process of food production.
Definition of Urban Agriculture: Urban agriculture encompasses a broader spectrum of agricultural activities within urban settings beyond just food production. It includes urban farming and practices such as horticulture, beekeeping, aquaculture, composting, and agroforestry within the urban landscape. Urban agriculture involves the integration of agriculture into the fabric of the city, incorporating green spaces, parks, public areas, and private properties for agricultural purposes. Besides its significance in enhancing food security and local food production, urban agriculture contributes to environmental sustainability, biodiversity conservation, waste recycling, and promoting ecological balance in urban areas. This multifaceted approach to agriculture in cities fosters a more resilient and self-reliant urban community, creating opportunities for social interaction, education, and a deeper connection with nature.
Importance of Urban Farming in Modern Society
Enhancing Food Security
Utilization of Underutilized Spaces
Community Engagement and Empowerment
Supporting Subsistence Farming
The Connection between Urban Farming and Subsistence Farming
Urban and subsistence farming are two distinct forms of agricultural practices, yet they share some connections and can benefit from each other.
Resource Utilization: Urban and subsistence farming focus on optimizing resource utilization. In urban farming, space is limited, so efficient use of available land is crucial. Techniques like vertical, container, and hydroponics maximize crop yields in small areas.
Similarly, subsistence farming relies on making the most of available resources, often practiced on small plots of land and using traditional methods passed down through generations.
Food Security: Urban and subsistence farming contribute to food security in their respective contexts. Urban farming addresses food security in densely populated areas by bringing fresh produce closer to the urban population, reducing the reliance on long-distance transportation of food. Subsistence farming, on the other hand, provides food directly to farming families, helping them meet their basic nutritional needs.
Environmental Benefits: Both types of farming can offer environmental benefits. Urban agriculture can reduce carbon footprint by lowering transportation distances, decreasing the need for refrigeration, and promoting green spaces within cities.
Subsistence farming, when practiced sustainably, often involves traditional methods that prioritize environmental stewardship, such as crop rotation, natural pest control, and minimal use of chemical inputs.
Community Engagement: Urban farming and subsistence farming can foster community engagement. Community gardens and rooftop farms can unite people, create social connections, and educate urban dwellers about agriculture and food production in urban areas. Similarly, subsistence farming is often a communal activity in rural areas, where community members help each other during planting and harvesting seasons.
Adaptability and Resilience: Both types of farming require adaptability and resilience. Urban farmers must be innovative in using limited space and dealing with urban challenges like pollution and limited access to water.
Subsistence farmers often face unpredictable weather patterns and market fluctuations, which require them to be resourceful and resilient in their agricultural practices.
Knowledge Sharing: While urban farming and subsistence farming may operate in different settings, there is potential for knowledge sharing between the two.
Urban farming practices, such as vertical farming and aquaponics, can be adopted or adapted in small-scale subsistence farming to enhance efficiency. Conversely, traditional farming techniques and the knowledge of subsistence farmers can inspire sustainable urban agriculture practices.
Understanding Urban Farming
Urban farming and urban agriculture represent innovative and sustainable approaches to food production within urban environments. With the increasing global population and rapid urbanization, these practices have gained significant attention as viable solutions to address food security and environmental challenges and promote self-sufficiency.
The scope of urban farming is multifaceted and encompasses various aspects:
Sustainable Food Production: Urban farming aims to produce fresh, nutritious, locally grown food within city limits. By utilizing vertical farming, hydroponics, aquaponics, rooftops, and community gardens, urban farmers maximize available space to develop diverse crops and raise livestock.
Community Engagement: Urban farming fosters community involvement, bringing together residents, schools, local organizations, and businesses. These initiatives create a sense of community ownership and encourage knowledge exchange, skill-building, and social cohesion.
Food Security: Urban farming enhances food security by reducing dependency on external food sources, especially in areas with limited access to fresh produce. It mitigates the risk of food shortages and price fluctuations caused by transportation and distribution challenges.
Environmental Benefits: Urban agriculture promotes sustainability by reducing the carbon footprint associated with long-distance food transportation. Converting underutilized urban spaces into green areas improves air quality, enhances biodiversity, and reduces the urban heat island effect.
Economic Opportunities: Urban farming can offer financial benefits by generating income by selling surplus produce and creating job opportunities within the local community, including agriculture, distribution, and marketing.
Resource Efficiency: Employing advanced technologies, urban farmers optimize resource use, including water, energy, and land, leading to reduced waste and increased productivity.
Education and Research: Urban farming acts as a living laboratory for exploring innovative agricultural techniques, contributing to ongoing research on sustainable practices, crop varieties suitable for urban environments, and the potential for controlled environment agriculture.
Subsistence Farming in Urban Contexts: For low-income communities, urban farming is a form of subsistence agriculture, providing direct access to affordable, fresh produce and empowering individuals and families to meet their basic nutritional needs.
Historical Background and Evolution of Urban Agriculture
Urban agriculture, also known as urban farming, is cultivating, processing, and distributing food within urban areas. It has a long and diverse history, with roots dating back to ancient civilizations. The evolution of urban agriculture can be understood through the lens of subsistence farming, which has played a significant role in sustaining urban populations throughout history.
Ancient and Medieval Times: Urban agriculture traces its origins to ancient civilizations such as Mesopotamia, Egypt, and the Indus Valley, where city-dwellers practiced subsistence farming to meet their food needs. These early urban centers developed innovative irrigation systems and employed rooftop gardens and small plots of land to grow crops. Agriculture was essential for city survival, providing a reliable food source close to the urban settlements.
During the Middle Ages, European cities also practiced urban farming. Monasteries and castle gardens were common, providing sustenance to their inhabitants. In Asian cities, rooftop gardens and small-scale agriculture in courtyards were prevalent.
Renaissance and Industrial Revolution: With the Renaissance, urban agriculture declined in Europe as large-scale agriculture in rural areas became more dominant. The Industrial Revolution further accelerated this shift, drawing people from rural areas to urban centers for industrial work. As a result, the focus on urban agriculture diminished as cities depended more on rural areas for food supplies.
20th Century and Rise of Urban Farming: The 20th century witnessed a resurgence of urban agriculture, particularly during times of crisis like World War I and II. In response to food shortages, urban residents in various countries established “Victory Gardens” to grow their fruits and vegetables. These initiatives helped alleviate food scarcity and promoted community engagement and patriotism.
The Green Revolution and Beyond: In the mid-20th century, the Green Revolution brought significant advancements in agricultural technology, increasing global food production. However, it also led to more substantial industrialization and a disconnect between food production and consumption. As concerns about environmental sustainability and food security grew, so did the interest in urban agriculture.
Contemporary Urban Agriculture: In recent decades, urban agriculture has been revitalized due to various factors, including increasing urbanization, concerns about food miles and carbon footprints, the desire for fresher and healthier produce, and a stronger emphasis on community resilience. Urban farming takes various forms, including community gardens, rooftop gardens, vertical farming, hydroponics, and aquaponics.
Cities worldwide have recognized the potential of urban agriculture to enhance food security, promote social cohesion, and contribute to sustainable development. Governments, non-profit organizations, and individuals actively support and invest in urban farming initiatives, advocate for better land-use policies, and integrate agriculture into urban planning.
Fundamental Principles and Approaches of Urban Farming
Sustainable Land Use
Vertical Farming
Diversification of Crops
Conservation of Resources
Integration of Technology
Community Involvement
Education and Training
Waste Management
Biodiversity and Pollinator Support
Local Food Access and Food Security
Approaches:
Vertical Farming: A cutting-edge approach optimized for urban farming, utilizing vertical space efficiently.
Community-Based Urban Agriculture: A community-driven approach to urban farming that fosters social engagement and shared responsibilities.
Sustainable Subsistence Farming: Emphasizing sustainable practices in urban agriculture for subsistence purposes.
Technology-Enhanced Urban Farming: Integrating modern technologies to optimize urban farming productivity.
Biodiversity and Pollinator Support in Urban Agriculture: Promoting biodiversity and pollinator-friendly practices for urban farming systems.
Waste-to-Nutrient Urban Farming: Utilizing organic waste for nutrient-rich soil amendments in urban agriculture.
Food Security through Urban Farming: Addressing food security challenges through local food production in urban areas.
Diverse Crops in Urban Agriculture: Emphasizing the importance of growing various crops in urban farming systems.
Efficient Resource Use in Urban Farming: Optimizing resource utilization in urban agriculture, including water and energy.
Education and Training in Urban Farming: Providing educational opportunities to empower urban farmers with essential skills and knowledge.
Role of Technology in Advancing Urban Farming
How is technology advancing urban farming?
There are several ways that technology is being used to advance urban farming. Some of the most common technologies include:
Vertical farming: Vertical farming is urban farming that grows crops in vertically stacked layers. This allows farmers to produce more food in a smaller space, which is ideal for urban areas. Vertical farms can be located in various places, such as warehouses, office buildings, and parking garages.
Hydroponics and aquaponics: Hydroponics raises plants without soil using nutrient-rich water. Aquaponics is a type of hydroponics that combines fish farming with plant cultivation. Both hydroponics and aquaponics can be used in urban areas, as they require very little space and water.
Intelligent sensors: Smart sensors monitor and control various aspects of urban farming, such as temperature, humidity, and nutrient levels.
Automated irrigation systems:Automated irrigation systems deliver water to plants regularly, saving farmers time and labor and helping to conserve water.
Data analytics:Data analytics collects and analyzes data about urban farming operations to identify trends, make predictions, and improve decision-making.
Benefits of using technology in urban farming
There are many benefits to using technology in urban farming. Some of the most important benefits include:
Increased productivity: Technology can help farmers produce more food in a smaller space, essential in urban areas where land is scarce.
Improved efficiency: Technology can help farmers automate tasks, saving time and labor to lower costs and higher profits.
Increased sustainability: Technology can help farmers conserve water and other resources essential in an urban environment.
Improved food security: Urban farming can help to increase food security in cities by providing a source of fresh, local produce.
Advantages of Urban Farming
Promoting Food Security in Urban Areas
Mitigating Environmental Impact and Climate Change
Fostering Community Engagement and Social Cohesion
Enhancing the Health and Well-being of Urban Dwellers
Types of Urban Farming
Rooftop Farming: Rooftop farming involves cultivating plants and vegetables on the rooftops of buildings in urban areas. Urban farming utilizes available rooftop spaces to create green places, reduce urban heat islands, and produce fresh produce in cities.
Vertical Farming: Crops can be grown vertically by stacking them on one another or vertically inclined surfaces, like tall buildings or specialized constructions. This method makes the best available space and frequently uses hydroponic or aeroponic systems to feed and irrigate the plants.
Community Gardens: Community gardens are shared plots of land where individuals or groups of people cultivate crops collectively. These gardens promote community engagement, provide access to fresh produce, and encourage sustainable agricultural practices.
Aquaponics: Aquaponics is a symbiotic system that combines aquaculture (raising fish) and hydroponics (growing plants in water). A sustainable and effective farming technique in urban environments is created when the fish waste fertilizes the plants, and the plants help filter and clean the water for the fish.
Hydroponics: Hydroponics is a soilless farming technique where plants are grown in nutrient-rich water solutions. The absence of soil reduces the need for vast land areas, making it suitable for urban environments with limited space.
Aeroponics: Like hydroponics, aeroponics is a soilless method that involves growing plants in an air or mist environment with nutrient-rich solutions. This technology allows for higher crop yields and water efficiency, making it ideal for urban farming.
Indoor Farming: Indoor farming involves growing crops in controlled environments such as warehouses, shipping containers, or vertical farms with artificial lighting and climate control. This method allows year-round production and minimizes the impact of external weather conditions.
Edible Landscaping: Edible landscaping combines ornamental plants and edible crops in public spaces, residential areas, or parks. It enhances the aesthetics of urban areas while also providing a source of fresh, locally grown food.
Mobile Farms: Mobile farms are movable agricultural setups, often based on trailers or vehicles, that can be transported to various urban locations. These farms offer flexibility and accessibility to different communities needing fresh produce.
Permaculture Gardens: Permaculture focuses on creating sustainable ecosystems where plants, animals, and humans harmoniously coexist. In urban settings, permaculture gardens can be designed to maximize productivity while minimizing waste and environmental impact.
Integrating Urban Farming with Subsistence Agriculture
Urban farming and subsistence agriculture are two essential practices that play crucial roles in ensuring food security and sustainability. While urban farming focuses on cultivating crops and raising livestock in urban areas, subsistence agriculture aims to meet the basic food needs of rural communities.
The world has witnessed a rapid urbanization trend in recent years, leading to an increasing number of people residing in urban centers. This shift has put significant pressure on the urban food supply chain, making it vital to explore innovative ways to integrate urban farming with subsistence agriculture to address food security challenges.
The Need for Integrating Urban Farming with Subsistence Agriculture:
(a) Urban Food Security:
Food security has become a pressing concern with the increasing urban population. Integrating urban farming with subsistence agriculture can help bridge the gap between urban food demand and supply. It allows urban dwellers to access fresh, locally grown produce while reducing the burden on the transportation and distribution of food from distant rural areas.
(b) Sustainable Resource Management:
Integrating both practices promotes sustainable resource management. Urban farming often incorporates eco-friendly methods, such as composting, rainwater harvesting, and organic farming, which can also be applied to subsistence agriculture in rural settings. This convergence can lead to reduced waste generation, efficient water usage, and improved soil health.
(c) Rural-Urban Linkages:
Integrating urban farming with subsistence agriculture fosters stronger linkages between rural and urban communities. This synergy can lead to knowledge sharing, the exchange of agricultural practices, and the establishment of mutually beneficial economic relationships.
Case Studies of Successful Integration in Developing and Developed Nations
Developing Nations
Kampong Glam, Singapore: This historic neighborhood in Singapore has been transformed into a vibrant community with a thriving urban farming scene. Residents grow various crops on rooftops, balconies, and vacant lots. The community garden, called the “Green Oasis,” is a popular spot for people to meet and socialize.
Lambeth, London: This borough in London has a long history of urban farming. Today, Lambeth has over 100 community gardens and allotments, providing residents with fresh food and helping improve the environment. The Lambeth Food Partnership, a non-profit organization, works to support and promote urban farming in the borough.
Nairobi, Kenya: The Kibera slum in Nairobi is home to over 1 million people. Despite its poverty, Kibera is also home to a thriving urban farming community. Residents grow crops on rooftops, backyards, and vacant lots. Urban farming provides a source of food and income for residents, and it also helps to improve the environment by reducing pollution and providing a green space for people to relax and socialize.
Developed Nations
Detroit, Michigan: The city of Detroit has a long history of urban farming. In recent years, there has been a resurgence of urban agriculture in Detroit, as residents have turned to it to improve their food security and connect with their community. Detroit has over 1,000 community gardens and urban farms, providing residents with fresh food and helping revitalize the city.
New York City, New York: New York City has a thriving urban farming scene. There are over 500 community gardens and urban farms in the city, providing fresh food for residents and helping to improve the environment.
The New York City Department of Parks and Recreation supports urban farming through its GreenThumb program, which provides technical assistance and resources to community gardens and urban farms.
Portland, Oregon: Portland is known for its commitment to sustainability and environmental protection. The city has a robust urban farming community, with over 100 community gardens and urban farms. Urban farming provides a source of fresh food for residents and helps reduce pollution and improve air quality.
As the world’s population grows, urban farming is becoming increasingly important. It is a sustainable way to produce food and provide for the needs of a growing population.
Here are some additional data points about the benefits of urban farming:
A study by the University of British Columbia found that urban agriculture can provide up to 15% of a city’s food needs.
Research by the UN Food and Agriculture Organization found that urban agriculture can create up to 10 million jobs in developing countries by 2030.
A study by the University of California, Berkeley found that urban farming can reduce air pollution by up to 20%.
A study by the University of Arizona found that urban farming can improve water quality by up to 30%.
Challenges and Solutions in Urban Farming
Challenges
Land scarcity: Urban areas are typically densely populated, with limited agricultural space, making finding land suitable for farming difficult and increasing land costs.
Proximity to pollution: Urban areas are often polluted, which can challenge urban farmers. Pollutants in the air, water, and soil can make it challenging to grow healthy crops.
Water scarcity: Urban areas are also often water-scarce, making it difficult to irrigate crops and challenging urban farmers to grow crops in containers or raised beds.
Skills and knowledge: Urban farmers may need to gain the skills and knowledge necessary to farm successfully. This can be a challenge for both individual farmers and community-based urban agriculture projects.
Regulations: Urban farmers may need to comply with various laws, which can be time-consuming and expensive.
Solutions
Vertical farming is a type of urban agriculture that uses stacked layers of plants to grow food in a vertical space. This can solve the land scarcity challenge, allowing farmers to grow crops with a small footprint.
Hydroponics and aquaponics: These are plant growth methods without soil. They grow crops in a controlled environment, which can help reduce pollution’s impact on yields.
Community-supported agriculture (CSAs): CSAs are subscription services that allow people to purchase shares of a farm’s produce. This can support urban farmers and provide fresh, local food to consumers.
Urban agriculture education: Offering education and training programs can help increase urban farmers’ skills and knowledge, leading to more successful urban agriculture projects.
Government support: Government support can reduce the regulatory burden on urban farmers and make it easier for them to succeed, including providing financial assistance, technical assistance, and land for urban agriculture projects.
Urban Farming Initiatives and Success Stories
Sky Greens, Singapore
Sky Greens is the world’s first low-carbon hydraulic water-driven urban vertical farm. It reduces the amount of energy and land needed for traditional farming techniques. The farm is in a greenhouse with three stories of vertical systems. Each system can produce five to ten times more per unit area than conventional farms.
Horta de Manguinhos, Brazil
The Horta de Manguinhos project is a community farm in Rio de Janeiro, Brazil. It is Latin America’s largest community farm and helps to provide food security for 800 families. The farm also employs more than 20 local workers.
The DUFi project transforms vacant lots in Bryan, Texas, into urban gardens. The project aims to educate and inspire residents about healthy eating, entrepreneurship, and tourism. The DUFi project has grown broccoli, cauliflower, cabbage, and lettuce in raised beds and pallet gardens.
Fresh & Local, Mumbai
A group called Fresh & Local uses urban agriculture to enhance the health and happiness of Mumbai people. The group turns vacant lands into farms where the local population can produce food. Thanks to Fresh & Local, more than 100 urban farms have been established in Mumbai.
Anjali Waman, India
Anjali Waman is a farmer from Kalwadi village in Pune, India. She has increased her income by 500% by using urban farming techniques. She grows papaya and bananas on her five-acre plot of land and vegetables in her backyard nutrition garden.
Tips for Starting an Urban Farm
Identifying Suitable Locations and Resources
Choosing the Right Crops and Livestock
Implementing Sustainable Farming Practices
Engaging the Community and Establishing Partnerships
Future Prospects and Innovations in Urban Farming
As urbanization continues to expand, urban farming and agriculture are set to play a pivotal role in addressing food security, sustainability, and resilience in our rapidly growing cities. Embracing the potential of urban farming offers exciting prospects and opportunities for a more interconnected and sustainable future.
One of the critical prospects of urban farming lies in its ability to bring fresh, locally grown produce closer to the urban population.
Urban farmers can optimize limited space and resources by utilizing innovative techniques such as vertical farming, hydroponics, and aquaponics, producing high yields in controlled environments. This not only reduces the dependence on distant agricultural sources but also minimizes transportation-related carbon emissions.
Moreover, advancements in innovative agriculture technologies and the integration of artificial intelligence are set to revolutionize urban farming. Automation and data-driven insights can streamline farming processes, optimizing resource usage and increasing productivity. These technologies can facilitate precise monitoring of crops, water, and nutrient levels, reducing waste and improving crop quality.
Innovations in sustainable energy solutions can also contribute significantly to the growth of urban farming.
Another critical aspect of the future of urban farming is the emphasis on circular economy practices. Integrating urban agriculture with other urban systems, such as waste management and renewable energy generation, can create a closed-loop system where waste becomes a resource for agricultural inputs.
Furthermore, the rise of community-supported agriculture (CSA) and farm-to-table initiatives empower local communities to participate actively in urban farming.
These initiatives foster a deeper connection between consumers and producers, promoting healthy eating habits, supporting local economies, and reducing the carbon footprint associated with food distribution.
Addressing the challenges and opportunities associated with subsistence farming is essential as urban farming gains momentum. Leveraging urban farming techniques for subsistence agriculture can offer vulnerable communities greater access to nutritious food and economic opportunities.
By providing training, resources, and support to subsistence farmers in urban areas, we can empower them to cultivate their land and enhance food security for their families and communities.
In conclusion, urban farming and agriculture are promising pathways toward a sustainable and resilient future. The convergence of innovative technologies, renewable energy solutions, circular economy practices, and community engagement holds the key to unlocking urban farming’s full potential.
By prioritizing these developments, we can establish a more food-secure and environmentally conscious urban landscape, transform cities into thriving hubs of sustainable agriculture, and ensure a healthier future for future generations.
Industrial agriculture, or industrial farming, is a modern farming system characterized by large-scale, intensive production methods using advanced technology and chemical inputs. It aims to maximize efficiency and yield by utilizing mechanization, genetic engineering, synthetic fertilizers, and pesticides.
Industrial agriculture is prevalent worldwide and has significantly transformed food production, making it a dominant force in the global food supply chain.
Overview of Industrial Agriculture:
In industrial agriculture, large monoculture fields and factory farms dominate the landscape. These vast expanses are dedicated to growing a single crop or raising a specific type of livestock. This approach prioritizes mass production and cost-effectiveness, but it often comes at the expense of environmental and ethical considerations.
Mechanization and Technology: Industrial farming heavily relies on machinery and technology to streamline production processes. Tractors, harvesters, and other advanced equipment enable farmers to manage vast areas with minimal labor requirements.
Chemical Inputs: Synthetic fertilizers and pesticides play a central role in boosting crop yields and protecting them from pests and diseases. However, the excessive use of these chemicals can lead to soil degradation, water pollution, and harm to non-target organisms.
Genetic Engineering: Industrial agriculture often employs genetically modified organisms (GMOs) to enhance crop traits such as resistance to pests, diseases, and herbicides. While this can increase productivity, it raises concerns about the long-term impact on biodiversity and human health.
Economies of Scale: Industrial farming capitalizes on economies of scale to reduce production costs. This allows for cheaper food prices but can lead to a concentration of power in the hands of large agribusiness corporations, disadvantaging smaller farmers.
Environmental Concerns: The extensive use of chemical inputs and monoculture practices can contribute to soil erosion, loss of biodiversity, and water pollution. Additionally, the high demand for water in industrial farming can exacerbate water scarcity in certain regions.
Animal Welfare Issues: Factory farming, a subset of industrial agriculture, involves raising animals in confined and intensive conditions. This practice has raised ethical concerns about the treatment and welfare of livestock.
While industrial agriculture has significantly increased food production, it faces mounting criticism for its environmental impact, potential health risks, and disregard for sustainable farming practices. As the world grapples with the challenges of feeding a growing population while preserving the planet’s resources, alternative and more sustainable agricultural approaches gain traction as potential solutions.
The Importance of Industrial Farming in Modern Food Production
Industrial farming, also known as industrial agriculture, plays a pivotal role in meeting the growing demands of the modern world’s population. This method of food production utilizes advanced technologies, large-scale operations, and efficient processes to produce a significant portion of the global food supply.
High Productivity and Efficiency:
Industrial farming techniques are designed to maximize productivity and efficiency. Large quantities of crops and livestock can be produced relatively quickly through mechanization, automated processes, and modern agricultural machinery. This ensures a steady and abundant food supply to meet the increasing global population’s needs.
Cost-Effectiveness:
With its focus on mass production, industrial agriculture optimizes economies of scale. Producing food in large quantities decreases the cost per unit, making food more affordable for consumers. This cost-effectiveness benefits individuals and contributes to stable food prices in the market.
Enhanced Crop Yields:
Industrial farming has significantly improved crop yields through the application of scientific advancements. Genetically modified organisms (GMOs), precision agriculture, and crop rotation methods are some of the innovations that have boosted agricultural productivity. Increasing crop yields can preserve more land, reducing the pressure to convert natural habitats into farmland.
Sustainable Resource Management:
Contrary to conventional belief, modern industrial farming practices are committed to sustainable resource management. These practices minimize environmental impact while maximizing crop output by adopting precision irrigation systems, efficient fertilizer usage, and integrated pest management.
Reliable Food Supply:
A consistent and reliable food supply is vital to avoid food shortages and hunger crises. Industrial farming’s large-scale production helps stabilize food availability, reducing the risk of food scarcity during adverse weather conditions or economic challenges.
Support for the Livestock Industry:
The livestock industry heavily relies on industrial farming to produce meat, dairy, and other animal-derived products sustainably. By employing advanced breeding techniques and proper animal welfare practices, industrial agriculture ensures a continuous and humane supply of livestock products.
Technological Innovation: Industrial farming thrives on technological innovation. As a result, it drives research and development in the agricultural sector, leading to novel advancements in biotechnology, crop protection, and sustainable farming practices. This ongoing progress contributes to the overall improvement of global food production systems.
History and Evolution of Industrial Agriculture
1: The Origins of Industrial Agriculture
Industrial agriculture traces its origins to the 18th and 19th centuries during the Agricultural Revolution. The invention of agricultural machinery, such as the seed drill and plow, enabled farmers to mechanize their processes, significantly increasing productivity.
This marked the shift from subsistence farming to surplus production for trade and consumption, laying the groundwork for industrial agriculture.
2: Technological Advancements and Green Revolution
The 20th century witnessed substantial advancements in agricultural technology, known as the Green Revolution. Pioneered by Norman Borlaug and other scientists, this movement introduced high-yielding crop varieties, chemical fertilizers, and pesticides. Industrial agriculture embraced these innovations, dramatically increasing crop yields and food output.
3: Consolidation and Agribusiness Expansion
Post-World War II, the agricultural landscape saw a consolidation of farms into more giant agribusinesses. Industrial agriculture adopted a more standardized and specialized approach, focusing on monoculture and economies of scale. Large corporations and conglomerates began dominating the industry, streamlining production and distribution processes.
4: Intensive Livestock Production
Industrial agriculture also revolutionized livestock farming. Traditional pastoral practices evolved into concentrated animal feeding operations (CAFOs), where large animals are raised in confined spaces. This approach prioritized efficiency and cost-effectiveness, but concerns about animal welfare and environmental impacts soon emerged.
5: Environmental and Social Impacts
The widespread adoption of industrial agriculture brought significant environmental challenges. Excessive use of chemical fertilizers and pesticides led to soil degradation and deforestation. The shift from small-scale farming to industrialized operations profoundly affected rural communities.
6: Criticisms and Sustainable Alternatives
As concerns about the negative consequences of industrial agriculture grew, critics called for more sustainable practices. Organic farming, permaculture, and agroecology emerged as alternatives focusing on ecological balance, reduced chemical inputs, and regenerative practices.
These approaches aim to minimize the environmental impact while promoting social and economic resilience.
7: Future Prospects and Innovations
The future of industrial agriculture lies in striking a balance between meeting the world’s growing food demands and preserving the environment—advancements in precision agriculture, genetic engineering, and vertical farming promise to sustainably increase productivity.
Collaborative efforts between policymakers, farmers, and consumers are crucial to shaping a resilient and responsible agricultural future.
Key Characteristics of Industrial Agriculture
Large-scale production and standardized methods
In modern agriculture, industrial agriculture, also known as industrial farming, plays a crucial role in meeting the ever-increasing global demand for food. This method involves large-scale production and standardized processes to enhance efficiency and productivity.
Intensive Land Use
To optimize production, industrial farming practices concentrate on intensive land usage. Large monoculture fields and confined animal feeding operations are standard features of this system.
Dependence on Chemical Inputs
Industrial agriculture relies heavily on synthetic fertilizers, pesticides, and herbicides to control pests and boost crop growth. These chemical inputs maximize output but can harm the environment and human health.
Mechanization and Automation
Industrial farming heavily employs modern machinery, such as tractors, combines, and automated irrigation systems, to reduce labor costs and increase efficiency.
Genetic Modification
Genetically modified organisms (GMOs) are frequently used in industrial agriculture to create crops with enhanced traits, such as resistance to pests and diseases, further increasing productivity.
Standardization of Crops and Livestock
Uniformity is a hallmark of industrial agriculture. Farmers often grow genetically similar crops and raise uniform livestock breeds to facilitate consistent management and harvest.
Global Distribution and Supply Chains
Industrial agriculture fosters extensive global supply chains to transport produce and livestock to distant markets, ensuring a year-round food supply.
Environmental Impact
The intensive use of chemicals, deforestation for expansion, and greenhouse gas emissions contribute to environmental issues like soil degradation, water pollution, and climate change.
Reduced Biodiversity
The focus on monoculture and standardized livestock breeds diminishes biodiversity, making the agricultural system vulnerable to disease outbreaks and other threats.
Social and Economic Implications
While industrial agriculture can provide affordable food to a growing population, it has also raised concerns about income disparities, labor conditions, and the consolidation of power among a few large corporations.
Environmental Impact of Industrial Agriculture
Discover the true environmental impact of industrial agriculture and industrial farming practices. Learn about the significant consequences of these intensive farming methods on the planet and the ecosystem.
Soil Degradation
Industrial agriculture practices often involve extensive monocropping and heavy use of chemical fertilizers and pesticides, which can lead to soil degradation and loss of fertility.
Water Pollution
Explore how industrial farming contributes to water pollution through agrochemicals and animal waste runoff, posing severe threats to aquatic ecosystems and human health.
Biodiversity Loss
Uncover the alarming decline in biodiversity caused by industrial agriculture, which destroys natural habitats and disrupts ecosystems, jeopardizing the survival of various plant and animal species.
Greenhouse Gas Emissions
Learn about the significant role of industrial farming in contributing to greenhouse gas emissions, exacerbating climate change, and its adverse effects on global weather patterns.
Deforestation
Discover how industrial agriculture drives deforestation to create more agricultural land, leading to habitat destruction, loss of carbon sinks, and threats to indigenous communities.
Energy Consumption
Explore the high energy demands of industrial farming operations, from machinery usage to processing and transportation, and the resulting strain on finite energy resources.
Land Use Conversion
Understanding the impact of converting natural ecosystems into farmland disrupts ecological balances and poses challenges for sustainable land management.
Eutrophication
Learn about the consequences of excessive nutrient runoff from industrial farms, causing eutrophication in water bodies and creating dead zones devoid of aquatic life.
Agroecology offers a holistic approach to farming that emphasizes biodiversity, natural resource conservation, and ecological balance. By promoting crop rotations, intercropping, and the use of beneficial insects, agroecology can reduce the need for chemical pesticides and synthetic fertilizers, thereby minimizing environmental damage and increasing long-term productivity.
Organic Farming: Chemical-Free Nourishment
Organic farming eliminates synthetic chemicals, opting for natural alternatives to control pests and enhance soil fertility. By relying on composting, cover cropping, and crop rotation, organic practices contribute to soil health and biodiversity, resulting in healthier produce for consumers and a safer environment.
Precision Agriculture: Smart Farming for Optimal Yields
Precision agriculture leverages modern technology, including sensors, drones, and data analytics, to optimize resource use. By precisely managing irrigation, fertilization, and pest control, this method minimizes waste, conserves water, and reduces chemical application, making it an efficient and eco-friendly alternative to traditional farming practices.
Permaculture: Designing Harmony in Agriculture
Permaculture involves designing agricultural systems to mimic natural ecosystems, creating sustainable and self-sufficient landscapes. By integrating diverse plants and animals, permaculture maximizes resource utilization, conserves water, and builds resilient ecosystems that thrive without chemical inputs.
Aquaponics and Hydroponics: Resource-Efficient Cultivation
Aquaponics and hydroponics are innovative soilless farming methods that recycle water and nutrients, using fish waste to fertilize plants. These closed-loop systems save water, reduce pollution, and enable year-round crop production, making them suitable alternatives for sustainable urban agriculture.
Regenerative Agriculture: Healing the Land
Regenerative agriculture focuses on restoring and enhancing soil health, increasing carbon sequestration, and promoting biodiversity. By incorporating cover cropping, no-till farming, and rotational grazing, it mitigates climate change, improves water retention, and increases overall ecosystem health.
Community-Supported Agriculture (CSA): Building Local Food Networks
CSA fosters direct connections between consumers and local farmers, reducing food miles and promoting community involvement in agriculture. By supporting CSA initiatives, consumers can access fresh, seasonal produce while providing stable income to farmers, encouraging more sustainable farming practices.
Policy and Regulation
Price supports: The government provides financial support to farmers to ensure they receive a fair crop price. This can encourage farmers to produce more food, lowering consumer prices. However, it can also lead to overproduction and environmental problems.
Subsidies for inputs: The government provides financial support to farmers to purchase information such as seeds, fertilizer, and pesticides. This can reduce the production cost for farmers, making it more profitable for them to produce food. However, it can also lead to overuse of inputs, which can have negative environmental impacts.
Regulations on environmental protection: The government regulates the use of pesticides and fertilizers to protect the environment. This can help to reduce pollution and water contamination. However, it can also increase the cost of production for farmers.
Regulations on food safety: The government regulates the production and processing of food to ensure that it is safe for consumers. This can help to reduce the risk of foodborne illness. However, it can also increase the cost of production for farmers.
Regulations on animal welfare: The government regulates the treatment of animals in agriculture. This can help to ensure that animals are treated humanely. However, it can also increase the cost of production for farmers.
These are just some government regulations and subsidies that influence industrial agriculture. The specific rules and offerings vary from country to country.
Here is some data on the impact of government regulations and subsidies on industrial agriculture:
A study by the World Bank found that government subsidies for agricultural inputs can increase production by 10-20%.
A study by the Food and Agriculture Organization of the United Nations found that government regulations on environmental protection can reduce water pollution by up to 50%.
A study by the Centers for Disease Control and Prevention found that government regulations on food safety can reduce the risk of foodborne illness by 50-70%.
A study by the Humane Society of the United States found that government regulations on animal welfare can reduce the number of animals raised for food by 50-70%.
These studies suggest that government regulations and subsidies can significantly impact industrial agriculture. They can increase production, reduce pollution, improve food safety, and protect animal welfare. However, it is essential to note that these regulations and subsidies can also increase the cost of food for consumers.
Government regulations and subsidies influence industrial agriculture in various ways. These regulations and contributions can positively impact the environment and animal welfare, but they can also increase the cost of food for consumers.
Conclusion
In conclusion, Industrial agriculture, also known as industrial farming, has revolutionized the global food production system, leading to increased efficiency, higher yields, and lower costs.
This method for large-scale agriculture utilizes advanced technologies and practices to meet the ever-growing demand for food worldwide. However, it is essential to recognize that industrial agriculture raises concerns about environmental impact, sustainability, and ethical implications.
As we delve deeper into the complexities of industrial agriculture, it becomes evident that finding a balance between productivity and sustainability is crucial for our planet’s future and future generations’ well-being.
Optimizing our agricultural practices, embracing more sustainable methods, and supporting initiatives that promote environmental responsibility can help us work towards a more resilient and eco-friendly food production system.
Stay informed about the latest advancements in industrial agriculture, as well as the efforts being made to address its challenges. We can collectively contribute to a more sustainable and food-secure future by staying informed and supporting responsible farming practices.
Remember, industrial agriculture and farming play a significant role in our lives, impacting our food, environment, and global economy. Let us remain conscious of these impacts and strive towards a more sustainable and balanced approach to agriculture, ensuring a prosperous future for humanity and our planet.
The cutting-edge branch of biotechnology known as gene editing enables researchers to alter the DNA of all living things, including people, plants, and animals. It offers the chance to change particular genes, remove or add DNA sequences, and even fix genetic mutations linked to different diseases. CRISPR-Cas9 is one of the most powerful and popular gene-editing methods.
A naturally existing system in bacteria called CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) offers tolerance to viral infections. The CRISPR-Cas9 gene editing tool was made possible by harnessing this system and the Cas9 enzyme. It operates by precisely inserting modifications into targeted DNA sequences.
The guide RNA (gRNA) and the Cas9 enzyme are the two essential parts of the CRISPR-Cas9 system. The target DNA sequence is recognized and bound to by the gRNA, which directs the Cas9 enzyme to that position.
The Cas9 enzyme slices the DNA strands after binding to the target DNA, enabling the alteration of genes. The desired genetic alterations can be made, such as adding new genetic material or replacing an unhealthy gene.
The invention of CRISPR technology, which is straightforward, practical, and versatile, has revolutionized gene editing. It has advanced research across several disciplines, including biotechnology, medicine, and agriculture.
Researchers are investigating its potential for treating hereditary disorders like muscular dystrophy, sickle cell disease, and cystic fibrosis. In addition, CRISPR is being used to research gene function, create disease models, and genetically modify crops to increase productivity and tolerance to pests and other environmental factors.
Although CRISPR technology has much potential, safety, and ethical issues come with using it. The responsible use of gene editing in people is still being debated, along with issues like permission, unforeseen consequences, and the difference between therapy and augmentation. Rules and regulations are being created to guarantee that gene editing is utilized ethically and for the benefit of society.
Implementing gene editing in agriculture has the potential to offer numerous advantages, but it also presents some challenges. Here are some potential benefits and challenges associated with gene editing in agriculture:
Benefits:
The potential benefits of gene editing in agriculture are significant, but some concerns need to be addressed. One problem is that gene-edited crops could escape into the wild and cross-breed with wild relatives. This could introduce new genes into the wild population, which could have unintended consequences.
Another concern is that consumers may be reluctant to accept gene-edited foods. This is because there is still some uncertainty about the long-term safety of gene editing. However, these concerns will likely be addressed as more research is conducted.
Overall, the prospects for gene editing in agriculture are up-and-coming.
This technology has the potential to make a significant contribution to food security and sustainability. However, it is essential to proceed with caution and to address the concerns that have been raised.
Here are some examples of how gene editing could improve food security and sustainability:
Crops resistant to pests and diseases: Gene editing could introduce genes into crops that confer resistance to pests and diseases. This would reduce the need for pesticides and herbicides, which can harm the environment.
Crops with improved nutritional content: Gene editing could modify the nutritional content of crops. For example, it could increase the levels of vitamins and minerals in crops or make crops more resistant to spoilage.
Crops better suited to marginal or degraded soils: Gene editing modifies the genetics of crops to be better suited to growing in marginal or degraded soils. This would allow farmers to grow crops in areas currently unsuitable for agriculture.
Crops that are more efficient at using water: Gene editing could modify the genetics of crops to be more efficient at using water. This would help reduce the water needed to grow crops, which is especially important in areas facing water scarcity.
These are just a few examples of how gene editing could improve food security and sustainability. As the technology develops, even more applications will likely be discovered.
Increased crop yields: Crop qualities, including disease resistance, drought tolerance, and improved nutrient uptake, can all be enhanced by gene editing. Crop yields and food security can be increased by introducing advantageous genetic modifications.
Less need for pesticides: Crops naturally resistant to pests and illnesses can be developed with gene editing. This might reduce the need for chemical pesticides, making agriculture more environmentally responsible and sustainable.
Increased nutritional value: Crops can be enriched with vital nutrients through gene editing to improve their nutritional worth. This might aid in the fight against malnutrition and raise the standard of the food supply as a whole.
Gene editing techniques can improve crop qualities like flavor, look, texture, and shelf life. Additionally, the ability to target the genes that cause quick spoiling will increase food shelf life and decrease food waste.
Climate change adaptation: Gene editing can develop crops that are more resistant to the effects of climate change, such as rising temperatures, water scarcity, and extreme weather events. This might help ensure agricultural output in the face of shifting environmental conditions.
Importance:
Crop Improvement: The exact alteration of plant DNA is now possible because of gene editing tools like CRISPR-Cas9. With the aid of this technique, crops can be developed with enhanced features like disease resistance, drought tolerance, increased yield, and higher nutritional value.
Scientists can speed up the breeding process and produce plants with desirable features more quickly than conventional breeding techniques by altering genes.
Disease Resistance: Plant diseases seriously threaten the world’s food supply. Crops resistant to diseases, viruses, fungi, and other pests can be produced thanks to gene editing. Scientists can lessen crop losses and the requirement for chemical pesticides by introducing or increasing resistant genes.
This increases agricultural sustainability, reduces its adverse effects on the environment, and protects public health.
Improved Nutritional Content: Gene editing can improve the nutritional content of crops to combat malnutrition and nutrient shortages. For instance, researchers can alter crops to contain more vital vitamins, minerals, and micronutrients. This could prevent shortages in areas where specific nutrients are deficient, resulting in better public health.
Environmental Sustainability: Gene editing can support sustainable agriculture by lowering the need for inputs like water, fertilizer, and pesticides. Crops can flourish in harsh conditions by improving drought resistance and nutrient usage efficiency, reducing resource consumption and agriculture’s environmental impact.
Gene editing can also facilitate the production of crops with enhanced nitrogen fixation, lowering the need for synthetic fertilizers and minimizing their detrimental effects on the environment.
Climate Change Adaptation: Gene editing can be beneficial in creating crops resistant to climate change. With the emergence of new pests, rising temperatures, altered precipitation patterns, and other issues brought on by climate change, gene editing provides a mechanism to insert adaptive features into crops quickly.
Crops can better endure and adapt to climate change by altering genes linked to heat tolerance, water usage efficiency, and resistance to pests and diseases, assuring food security in the face of climatic uncertainty.
Gene Editing Techniques in Agriculture
CRISPR-Cas9 system and its working principle
The CRISPR-Cas9 system is a revolutionary gene-editing technology that allows scientists to make precise changes to an organism’s DNA. CRISPR-Cas9 stands for Clustered Regularly Interspaced Short Palindromic Repeats and CRISPR-associated protein 9.
The working principle of the CRISPR-Cas9 system involves two key components: the guide RNA (gRNA) and the Cas9 protein.
Guide RNA (gRNA): The gRNA is a synthetic RNA molecule consisting of targeting and scaffold sequences. The targeting sequence complements a specific DNA sequence that scientists want to modify. It guides the Cas9 protein to the desired location on the DNA.
Cas9 Protein: The Cas9 protein is an enzyme derived from bacteria, specifically from the CRISPR system bacteria use to defend against viral infections. Cas9 is a pair of molecular scissors that can cut DNA at a specific location.
Here’s a step-by-step explanation of how the CRISPR-Cas9 system works:
Designing the gRNA: Scientists create a gRNA complementary to the DNA sequence they want to modify. The gRNA consists of a series matching the target DNA and a scaffold sequence interacting with the Cas9 protein.
Delivery of CRISPR components: The gRNA and Cas9 protein are introduced into the target cells or organisms through various methods, such as direct injection or viral vectors.
Recognition and binding: The gRNA recognizes and binds to the complementary DNA sequence within the target genome. The gRNA’s targeting sequence ensures specific binding to the desired location.
Formation of Cas9-gRNA complex: The Cas9 protein binds to the gRNA, forming a complex. The gRNA guides this complex to the specific location on the DNA.
DNA cleavage: Once the Cas9-gRNA complex reaches the target DNA sequence, the Cas9 protein cuts both DNA strands at a precise location, creating a double-strand break (DSB) in the DNA molecule.
Resulting genetic changes: The repaired DNA may contain the desired genetic modification. The altered DNA sequence can result in changes to gene expression, protein function, or other biological characteristics of the organism.
DNA repair: After the DNA is cut, the cell’s natural DNA repair mechanisms come into play. Two main repair pathways exist: non-homologous end joining (NHEJ) and homology-directed repair (HDR).
NHEJ: Without a repair template, the DNA ends are rejoined by the NHEJ pathway. This repair process is prone to errors and can introduce insertions or deletions (indels) at the site of the cut, leading to gene disruption.
HDR: If a repair template is provided, such as a DNA molecule with the desired genetic alteration, the cell can use the HDR pathway to incorporate the template during the repair process. This enables precise insertion, deletion, or modification of the DNA sequence.
The CRISPR-Cas9 system’s simplicity and versatility have revolutionized the field of genetic engineering, allowing researchers to study gene function, develop disease models, and potentially treat genetic disorders in the future.
However, it is essential to note that the technology is still being researched and refined, and ethical considerations and regulatory frameworks need to be considered when applying CRISPR-Cas9 in various contexts.
Applications of Gene Editing in Agriculture
Gene editing, specifically using technologies like CRISPR-Cas9, has significant potential for various applications in agriculture. Here are some examples of how gene editing can be utilized in agricultural practices:
Crop improvement: Gene editing can enhance crop traits such as yield, nutritional content, disease resistance, and tolerance to environmental stresses. Scientists can develop crops with improved productivity, nutritional value, and Resilience to challenging growing conditions by editing specific genes responsible for these traits.
Disease resistance: Gene editing can help create crops resistant to pests, pathogens, and diseases. By modifying genes involved in plant defense mechanisms or susceptibility to specific conditions, scientists can develop crops that require fewer pesticides or fungicides, reducing the environmental impact and improving crop health.
Enhanced nutritional content: Gene editing can be employed to increase the nutritional value of crops. For instance, scientists can edit genes to enhance the levels of essential vitamins, minerals, or other beneficial compounds in crops, thereby addressing nutritional deficiencies and improving human health.
Extended shelf life: Gene editing techniques can modify genes involved in the ripening process of fruits and vegetables. By altering these genes, scientists can develop crops with extended shelf life, reducing post-harvest losses and improving the availability of fresh produce.
Weed control: Gene editing can contribute to weed management strategies by developing herbicide-resistant crops. By editing specific genes in crop plants, scientists can make them tolerant to herbicides, allowing farmers to control weeds more effectively while minimizing crop damage.
Environmental sustainability: Gene editing can help develop crops that require fewer inputs, such as water, fertilizers, and pesticides. Gene-edited crops can reduce the environmental impact of conventional agriculture practices by enhancing nutrient uptake efficiency, water usage, or natural defenses.
Climate adaptation: Gene editing techniques can help develop better crops adapted to changing climatic conditions. By modifying genes involved in stress responses, scientists can create crops more resilient to drought, heat, cold, or other climate-related challenges.
It is important to note that using gene editing in agriculture raises ethical and regulatory considerations. Ensuring the responsible and transparent deployment of gene-edited crops is crucial to addressing potential risks and maintaining public confidence in these technologies.
Regulatory and Ethical Considerations
Current regulations and policies surrounding gene editing in agriculture
United States: The United States has a patchwork of rules governing gene editing in agriculture. The USDA regulates genetically engineered (GE) crops, but genome-edited crops that do not contain foreign DNA are generally exempt from these regulations. The FDA regulates food products derived from GE crops but does not require pre-market approval for most GE foods.
European Union: The EU has a more restrictive regulatory framework for GE crops. GE crops are subject to a pre-market approval process by the European Commission and must be labeled as such. However, the EU still needs guidance on regulating genome-edited crops.
China: China has a relatively permissive regulatory framework for GE crops. GE crops are subject to a registration process by the Ministry of Agriculture but do not need to be labeled as such. China has also approved the commercialization of several genome-edited crops.
Japan: Japan has a regulatory framework for GE crops that is similar to the EU’s. GE crops are subject to a pre-market approval process by the Ministry of Agriculture, Forestry, and Fisheries and must be labeled as such. However, Japan has approved the commercialization of several genome-edited crops.
In addition to these national regulations, several international organizations are involved in regulating gene editing in agriculture. These organizations include the Codex Alimentarius Commission, the International Plant Protection Convention, and the Convention on Biological Diversity.
Case Studies and Success Stories
Golden Rice: Golden Rice is a genetically modified rice variety engineered to produce beta-carotene, a precursor to vitamin A. Vitamin A deficiency is a significant public health problem in developing countries. Golden Rice is a way to address this problem. In 2018, a study published in Nature Biotechnology found that Golden Rice could significantly reduce the risk of vitamin A deficiency in children.
Drought-tolerant corn: Drought-tolerant corn is another example of a gene-edited crop that can potentially improve food security. This type of corn has been engineered to be more resistant to drought, which could help farmers in areas with limited water resources to produce more food.
In 2017, a study published in Nature found that drought-tolerant corn could increase yields by up to 30% in drought-prone areas.
Pest-resistant potatoes:Pest-resistant potatoes are another example of how gene editing can improve crop yields. This type of potato has been engineered to resist the Colorado potato beetle, a major pest that can destroy potato crops.
In 2016, a study published in the journal Nature Biotechnology found that pest-resistant potatoes could reduce the use of pesticides by up to 90%.
A 2018 National Academies of Sciences, Engineering, and Medicine study found that gene editing could significantly impact agricultural productivity, food security, and environmental sustainability.
A 2019 study by the International Food Policy Research Institute found that gene editing could help reduce agriculture’s environmental impact by reducing the need for pesticides and herbicides.
A 2020 study by the Global Alliance for Genomics and Health found that gene editing can improve the nutritional quality of food crops.
Of course, some potential risks are also associated with gene editing in agriculture. These risks include the possibility of unintended consequences, the potential for gene-edited crops to escape into the environment, and the ethical concerns raised by some people about gene editing in food production.
It is essential to carefully consider these risks and ethical considerations as gene editing technology continues to develop. However, the potential benefits of gene editing in agriculture are significant, and the technology has the potential to make a real difference in the lives of people around the world.
Conclusion
Gene editing is a powerful new tool that has the potential to revolutionize agriculture. By allowing scientists to make precise changes to the genomes of plants and animals, gene editing can improve food security and sustainability.
One of the most promising applications of gene editing in agriculture is developing crops resistant to pests, diseases, and drought. This could reduce the use of pesticides and herbicides, which can harm the environment. Gene editing could also improve crops’ nutritional content, making them more nutritious and accessible to people worldwide.
Gene editing could improve the quality and yield of crops and make farming more sustainable. For example, it could develop crops better suited to growing in marginal or degraded soils, increasing food production in areas that are currently unsuitable for agriculture.
Agritech, commonly called agricultural technology, is an innovative strategy that uses cutting-edge technological advancements and digital solutions to transform farming processes.
Agritech seeks to increase agricultural output, optimize resource use, and advance sustainable farming practices using sensors, drones, and artificial intelligence. By emphasizing innovation and efficiency, Agritech is altering the farm industry. This will increase crop yields, profitability, and a more ecologically responsible farming method.
Water management is a crucial aspect of agriculture that strongly impacts crop yield and overall agricultural sustainability. Utilizing effective water management strategies improves crop yields, profitability, environmental responsibility, and conservation of this limited resource.
Using irrigation systems, soil moisture sensors, and precision agriculture, among other efficient water management techniques, farmers can supply crops with the proper amount of water at the appropriate time.
Farmers can increase agricultural production and reduce water waste by avoiding under- or over-irrigation.
Agriculture is one of the biggest consumers of freshwater, and water scarcity is a serious issue worldwide. Using effective water management techniques in agriculture contributes to preserving this priceless resource for future generations.
Implementing water-saving technologies, such as drip irrigation, micro-sprinklers, and precision application techniques, can help farmers use less water while maintaining crop health. Ethical water management techniques also help protect ecosystems, reduce soil erosion, and prevent water contamination.
Globally, agricultural systems face substantial problems due to climate change, including changing precipitation patterns and increased droughts and floods.
Effective water management protects against these dangers caused by the climate. Farmers may adapt to changing climate circumstances, assuring crop resilience and decreasing vulnerability, by implementing strategies like rainwater gathering, water storage, and good irrigation practices.
Water management in agriculture is strictly regulated in many areas to protect water resources and advance sustainable agricultural practices. Following these rules ensures legal compliance, helps avoid fines, and maintains a good agricultural sector reputation.
Farmers may demonstrate their commitment to responsible resource use by using effective water management practices to help the agricultural industry become more sustainable.
In this article, we’ll examine the significance of water management in agriculture and give farmers and other agribusiness owners practical advice on using water as efficiently as possible.
Technology is playing an increasingly important role in water management. By collecting and analyzing data, technology can help to improve efficiency, reduce waste, and ensure the sustainability of water resources.
Some of the key ways that technology is being used in water management include:
Real-time monitoring: Technology can monitor water levels, flow rates, and quality in real-time. This information can be used to identify leaks, optimize water distribution, and prevent water contamination.
Smart meters: Smart meters can track water usage in real time, providing valuable insights into how water is consumed. This information can be used to identify areas where conservation efforts could be targeted.
Predictive analytics: Technology can analyze historical data to predict future water demand. This information can be used to plan for droughts, floods, and other water-related events.
Water treatment: Technology is being used to develop new and more efficient water treatment methods. These include membrane filtration, UV disinfection, and other technologies to remove pollutants from water.
Water reuse: Technology is being used to develop new ways to reuse wastewater. This includes using membrane bioreactors, reverse osmosis, and other technologies to treat wastewater to a level that can be reused for irrigation, industrial processes, or drinking water.
Here are some specific examples of how technology is being used to improve water management:
In California, Los Angeles uses smart meters to track water usage in real-time. This information is used to identify areas where conservation efforts could be targeted. As a result, the city has reduced its water consumption by 10%.
Singapore’s national water agency, PUB, monitors its water resources using satellite imagery, sensors, and data analytics. This information optimizes water distribution, prevents leaks, and predicts future demand.
In India, the government uses technology to develop new ways to reuse wastewater. For example, the city of Pune uses membrane bioreactors to treat wastewater to a level that can be reused for irrigation.
Introduction to Water Management Software
Water management software is a type of software that helps organizations manage their water resources. It can track water usage, identify leaks, monitor water quality, and optimize water distribution. Various organizations, including water utilities, municipalities, businesses, and agricultural producers, can use water management software.
Many different water management software applications are available, each with strengths and weaknesses. Some of the most popular water management software applications include:
AquiferWIN: AquiferWIN is a software application that helps users manage groundwater resources. It can track water levels, monitor water quality, and optimize groundwater pumping.
WaterGEMS: WaterGEMS is a software application that helps users manage drinking water systems. It can track water usage, identify leaks, monitor water quality, and optimize water distribution.
WaterCAD: WaterCAD is a software application that helps users design and analyze water distribution systems. It can be used to model water flow, pressure, and water quality.
Sensus Aqua: Sensus Aqua is a software application that helps users manage water meters and usage. It can collect water usage data, track water usage trends, and identify leaks.
Here are some of the benefits of using water management software:
Improved water efficiency: Water management software can help organizations identify and fix leaks, leading to significant reductions in water usage.
Reduced water waste: Water management software can help organizations track water usage and identify areas where water is wasted. This can help organizations to reduce their water bills and conserve water resources.
Compliance with water regulations: Water management software can help organizations track compliance, avoiding fines and penalties.
Improved decision-making: Water management software can give organizations insights into their water resources, which can be used to make better decisions about water management.
Key Features of Water Management Software
Real-time monitoring and data collection: The process of continuously monitoring and gathering data from numerous sources is called real-time monitoring and data collection. Businesses and people can use this strategy to acquire the most recent information and base their judgments on accurate and up-to-date information.
Real-time monitoring involves continuous observation and tracking of particular metrics, events, or systems. This can be accomplished using sensors, instruments, or other continuous data stream-producing data collectors.
Weather forecasting and predictive analytics: Weather forecasting is the practice of predicting atmospheric conditions for a specific area and time in the future. It is a crucial example of predictive analytics, which entails examiningpast data and patterns to forecast the future.
Weather forecasting uses observable data, including temperature, humidity, wind speed, and atmospheric pressure, and computer simulations of the atmosphere’s behavior. Predictive analytics analyzes these data and models to provide forecasts.
Irrigation Scheduling and Optimization: Irrigation scheduling and optimization involve choosing the most effective and efficient irrigation procedures for a particular crop or landscape.
Water resources must be managed to reduce waste, conserve water, and increase crop output. Irrigation scheduling and optimization work to provide plants with the proper amount of water at the right time by utilizing various methods and technology.
Integration with IoT devices and sensors: Integration with IoT devices and sensors is the process of connecting sensors and objects with your applications and databases. Once connected, you can implement end-to-end automation that helps you fully use your equipment.
There are many different ways to achieve IoT integration. One common approach is using an IoT platform, a software solution that helps you connect, manage, and analyze IoT devices and data.
Another approach is to use a combination of open-source and commercial tools. This approach can be more flexible and cost-effective, but it can also be more complex to implement.
Water usage tracking and reporting: Monitoring, measuring, and recording the amount of water used within a particular context—such as a home, place of business, or community—is called “water usage tracking and reporting.” It entails tracking the quantity of water used over a specified period and creating reports to examine patterns, spot trends, and gauge water usage effectiveness.
Case Studies: Successful Implementation of Water Management Software
Here are some case studies of successful implementation of water management software with data:
Veolia Water in Tidworth, UK
Veolia Water is a water and wastewater services company in over 70 countries. In 2014, they implemented Aquamatix’s WaterWorX™ software in Tidworth, UK, to improve the efficiency and effectiveness of their water management operations.
The software helped Veolia to:
Reduce water losses by 10%
Improve customer service by 20%
Increase operational efficiency by 15%
Surat Municipal Corporation in India
The Surat Municipal Corporation (SMC) is responsible for water supply and sanitation in Surat, India. In 2012, they implemented a water management software called WaterMIS to improve the efficiency of their water distribution network.
The software helped SMC to:
Reduce non-revenue water (NRW) by 20%
Improve water pressure by 15%
Increase customer satisfaction by 10%
City of Phoenix, Arizona
The City of Phoenix, Arizona, is one of the largest water utilities in the United States. In 2010, it implemented WaterLogic, a water management software, to improve the efficiency of its water distribution network.
The software helped Phoenix to:
Reduce NRW by 15%
Improve water pressure by 10%
Increase customer satisfaction by 5%
These are just a few examples of the many successful implementations of water management software. These software solutions can help water utilities to improve efficiency, reduce costs, and improve customer service.
Here is some additional data on the benefits of water management software:
A study by the Water Environment Federation found that water utilities that use water management software can save an average of 10% on their water losses.
Another study by the American Water Works Association found that water utilities that use water management software can improve their customer satisfaction by an average of 15%.
A third study by the National Association of Water Companies found that water utilities that use water management software can reduce their operating costs by an average of 5%.
These studies demonstrate that water utilities can significantly benefit from water management software. They should consider deploying a solution to increase productivity, cut expenses, and enhance customer service.
Considerations for Choosing Water Management Software
A. Scalability and compatibility with existing systems: Scalability and compatibility are two essential factors to consider when designing and developing software systems. Scalability refers to a plan’s ability to handle increasing load without decreasing performance, while compatibility refers to a strategy’s ability to work with other systems.
There are several ways to ensure a system is scalable. One way is to design the system using a microservices architecture. This architecture breaks the system into small independent services that can be scaled independently. Another way is to use a cloud-based platform. Cloud platforms offer various scalability options, such as auto-scaling and load balancer.
B. User-friendly interface and ease of use: A user-friendly interface is easy to understand and navigate. The user knows where to find what is needed, and the controls are easy to use.
C. Cost and return on investment: Cost and return on investment (ROI) are essential when making financial decisions, especially in business and investment contexts. Cost refers to the money or resources required to acquire, produce, or maintain something. At the same time, ROI measures the profitability or financial gain generated from an investment relative to its cost.
Increased use of artificial intelligence (AI). AI is already used in water management software to improve efficiency and accuracy. For example, AI can detect leaks, predict water demand, and optimize water treatment processes.
As AI becomes more powerful and affordable, we can expect to see even more use of it in water management software.
Greater use of data analytics. Data analytics is another significant trend in water management software.
By analyzing data from sensors, meters, and other sources, water utilities can gain insights into their water systems that they would not otherwise be able to see. This data can then be used to improve efficiency, reduce costs, and protect water quality.
The rise of cloud-based water management software. Cloud-based water management software is becoming increasingly popular, offering several advantages over traditional on-premises software. For example, cloud-based software is more scalable, easier to update, and more secure. We expect to see even more water utilities adopt cloud-based water management software.
The development of innovative water grids. Intelligent water grids are a network of sensors, meters, and other devices that collect and transmit data about water usage.
This data can be used to improve efficiency, reduce leaks, and optimize water treatment processes. We can expect to see the development of even more sophisticated intelligent water grids.
A recent study by the World Economic Forum found that AI could save the global water industry up to $200 billion per year by 2030.
A study by the Water Research Foundation found that data analytics could help water utilities save an average of 10% on water and sewer costs.
The global cloud-based water management software market is expected to grow from $1.4 billion in 2020 to $2.8 billion by 2025.
The global market for smart water grids is expected to grow from $7.5 billion in 2020 to $15.5 billion by 2025.
These are just a few of the future trends in water management software. Water management software will become even more critical as the world’s population grows and water resources become increasingly scarce. These trends will help water utilities to become more efficient, reduce costs, and protect water quality.
As the world continues to grapple with the irreversible repercussions of COVID-19, a silver lining emerges in the form of global innovation, transforming various business sectors.
The sports industry stands at the forefront of these changes, ushering in a new era marked by smart stadiums and superior live-streaming platforms, all aimed at ensuring fan engagement transcends the boundaries of a single game. By 2027, the global sports technology market is set to burgeon to a staggering USD 36.66 billion, reflecting a robust compound annual growth rate (CAGR) of 17.8%.
In this blog, we are looking at how the connection between fans and their favorite sports games is changing and how technology is becoming a key part of this change, making the fan experience even better.
What do we mean by Fan Engagement?
Across the globe, various sports organizations are keenly exploring and fully cognizant of the invaluable advantages linked with robust fan engagement. This strategic focus results in cultivating a “loyal fan base,” effectively “attracting new fans,” and building an “enhanced sense of belongingness within the sports community.”
Understanding a Sports Fan
Type of Fans and their motivation to be associated with the sport:
Motivations of Different Fan Types Shape their Preferred Features:
Engaging the Sports Fans During and Beyond the Season
To keep the ball rolling…. !!! Exploring some compelling use cases where technology is truly revolutionizing fan engagement.
During the Season
Sports fans crave being close to the action. Being surrounded on all sides by fans is an experience everyone has to experience at least once.
A Ticket Tracking System
Various e-ticket analyzing vending machines have enhanced ticket holders’ experience by making it a “No contact stadium experience.” It’s an automatic platform that alerts sports clubs and the stadium management of attendance.
To name a few examples, like
Facial recognition software to verify the identity of customers in stadiums.
Barcode scanners installed at the entry point can allow you to enter with a simple wave of your smartphone.
Scanning a URL QR code to land on the official website and instantly access event details allows users to buy that event ticket and makes the entire stadium entrance process as seamless as possible.
Creating Digital and Commemorative Tickets
The necessity for physical tickets is fast becoming a thing of the past. A shining example of this technological shift in the sports industry is the emergence of commemorative tickets. These are exclusive tickets, produced in limited quantities and available only for a specified duration, celebrating unique events or anniversaries. These commemorative tokens are not just digital analogs to physical tickets; they are potential contenders for Non-Fungible Token (NFT) collectibles. Thus, they blend traditional keepsakes’ nostalgic charm with digital assets’ convenience and novelty.
Location-based Messaging
This innovative approach guides the attendees from stepping foot in the stadium to various designated areas throughout the event. For example, navigating an attendee from entry to their allotted seat or nearest pick-up point for pre-ordered food and beverages. Coupled with the application of beacon technology, it can pinpoint the attendees’ locations and deliver personalized messages loaded with key information. This method provides an added interaction layer, enhancing the overall event experience.
Elevating the Experience through Immersive Technologies
Immersive technologies are steadily revolutionizing how sports fans experience the captivating thrills, adrenaline surges, and crucial game analytics unique to every match. They bring to life every moment, from the player’s individual statistics to the critical final minutes of the game. Virtual Reality (VR) offers fans a groundbreaking, real-time experience, allowing them to view the game through the lens of a specific player. Meanwhile, Augmented Reality (AR) offers in-stadium attendees the ability to access the game stats of a player at their fingertips. These continuously evolving technologies promise an exciting, hyper-realistic future for sports fans worldwide.
The Revolutionary Impact of Drone Technology in the Sports World
Drones are forging fresh pathways in the evolving sports landscape, bringing to the table a blend of aerial surveillance, mobility, data gathering, artificial intelligence, lifting capabilities, and visual technologies. This multifaceted combination renders drones an ideal fit for a multitude of applications in sports, from conventional uses to disruptive innovations. A few examples could be security surveillance of stadium attendees, getting pre-ordered food and beverages delivered to seats and more.
Harnessing AI for a Data-driven Approach
AI is poised to significantly shape a fan’s journey within and beyond the stadium. Stadiums are evolving into significant content and data hubs, meticulously designed to optimize the customer journey and meet the dynamic needs of fans. Stadiums and fan platforms are transforming into ‘data sanctuaries.’ Armed with these data points, personalized marketing campaigns, interactive games, and sales recommendations can be devised. This strategy enhances the fan experience, making it more immersive and personalized.
A Unified Experience Through a Single App
One of the most transformative developments is the advent of a comprehensive app that serves as a one-stop hub for all fan interactions. This platform fosters a vibrant community, streamlining various fan activities such as booking tickets, staying abreast of the latest news and updates, and participating in voting polls. In addition, fans can engage in quizzes and trivia, stimulating friendly competition and adding an additional layer of interaction to their sports experience. This consolidated approach enhances fan engagement and simplifies their journey, creating a more seamless and enjoyable experience.
Beyond the Season
Fan engagement need not wane during the off-season. This period can be effectively utilized to keep fans connected and excited for the upcoming season. One way to achieve this is by rolling out innovative initiatives and platforms to continue the interaction and conversation.
E-Commerce: Merchandise Sales and Auctions
Capitalizing on e-commerce platforms to sell merchandise can significantly boost off-season engagement. Live auctions and reverse auctions present a unique opportunity for fans to own memorabilia of their favorite team or player. This maintains fan interest during the off-season and opens up new revenue streams for sports organizations.
Non-Fungible Tokens (NFTs) collectibles and Digital Assets
Leveraging NFTs to sell digital assets and collectibles has emerged as an innovative way to keep fans engaged. These unique digital assets can range from event custom postersand trophies to tickets, each being valuable to the sport’s legacy. By creating a buzz before the season starts, NFTs offer an exciting build-up to the main events and maintain fan engagement.
Engaging Fans through Fantasy Games
The format of fantasy games has revolutionized fan engagement during the off-season. By allowing fans to create their own teams and make strategic decisions, these games keep the spirit of competition alive even when there are no live games. This form of interactive engagement keeps fans involved and invested in the sport, effectively bridging the gap between seasons.
Conclusion
The sports industry has undergone a transformative shift driven by the strategic implementation of fan engagement strategies. These approaches have fueled exceptional growth, delivering substantial value to sponsors, stimulating positive conversations around sports, and creating unprecedented opportunities for revenue generation. Technology has been at the heart of this evolution, profoundly expanding and enhancing how fans interact with their favorite sports. As we reflect on the past, it becomes abundantly clear that this trend of technological influence is only set to escalate in the future, further revolutionizing fan engagement in the sports industry.
Aeroponics farming for sustainable agriculture is an innovative, soil-less cultivation method that is transforming traditional agricultural practices. As an essential component of modern horticulture, aeroponic agriculture is gaining popularity due to its numerous advantages, such as enhanced crop yield, space efficiency, and sustainability. This article explores the science behind aeroponics farming, its benefits, and its future potential in agricultural development.
What is Aeroponics Farming?
Aeroponics farming, the heart of advanced horticulture, is a process that grows plants in an air or mist environment without using soil or an aggregate medium. This high-tech cultivation method offers a controlled environment where plants can flourish, and nutrients can efficiently deliver directly to the roots. Aeroponic agriculture leverages technology to ensure optimal growth, providing plants with the perfect blend of water, nutrients, and oxygen.
The Benefits of Aeroponics Farming
Aeroponics farming is the epitome of sustainable agriculture for many reasons. Firstly, it utilizes less water compared to traditional farming methods. The system recycles water, significantly reducing waste and making aeroponic agriculture particularly valuable in areas where water is scarce.
Secondly, aeroponics farming has a higher yield potential thanks to improved nutrient delivery and growth conditions. The lack of soil eliminates many common gardening problems, such as pests, diseases, and weeds, making crop management more straightforward and efficient.
Lastly, aeroponic agriculture systems are scalable and versatile. They can be built vertically, making them ideal for urban farming where space is constrained. The system’s flexibility allows for year-round agriculture, independent of weather conditions, and can grow various crops, from leafy greens to root vegetables and herbs.
The Future of Aeroponic Agriculture
As the global population continues to increase, the demand for food is expected to rise. Aeroponics farming is one of the most promising solutions to this challenge, offering an environmentally friendly and sustainable way to maximize agricultural productivity.
Integrating technology such as artificial intelligence and IoT can further enhance the capabilities of aeroponic agriculture. Intelligent systems that monitor and adjust environmental conditions like humidity, temperature, and nutrient levels can automate farming and optimize growth conditions, paving the way for a new agricultural era.
Conclusion
The realm of aeroponics farming is much more than a contemporary trend; it’s a revolutionary approach that could shape the future of global food production. As more people realize aeroponic agriculture’s immense potential, it will likely become a standard in sustainable farming practices, ensuring food security while preserving our planet’s precious resources.
The world of agri-tech is rapidly advancing with the evolution of technology. Central to this transformation is farm management software, an innovative solution enabling farmers to streamline operations, increase productivity, and foster sustainability.
Farm management software offers a host of features that are invaluable to modern farming practices. In this article, we’ll delve into why these sophisticated digital tools are reshaping the agriculture landscape.
What is Farm Management Software?
Farm management software is an application or platform designed to help farmers and agricultural professionals efficiently manage every aspect of their farms. This high-tech solution handles many tasks, from tracking livestock, monitoring crops, and managing inventory to financial planning. The increasing reliance on this cutting-edge technology underscores the revolution technology has ignited in the farming industry.
Why Is Farm Management Software Important?
With pressure to increase yields, maintain sustainability, and meet the rising global food demand, farmers are turning more to technology to help them achieve these goals. Farm management software stands out in providing the necessary solutions to these challenges.
The farm management software simplifies complex tasks and improves operational efficiency. It allows farmers to monitor crop health, schedule tasks, manage labor, record harvest data, and track the weather—all on a single platform. This consolidation of tasks saves time and reduces the chances of errors from manual data management.
Benefits of Farm Management Software
Farm management software carries a wealth of benefits. Below are some key advantages that make it a worthy investment:
Efficiency: Farm management software increases efficiency and productivity on the farm by automating repetitive tasks and streamlining processes. It also assists in better decision-making with real-time data and insights.
Record Keeping: The software provides an excellent platform for record keeping. From inventory and planting to harvesting, all necessary data can be recorded and accessed easily.
Cost Management: Farm management software allows farmers to monitor and control their expenses. They can track their resources, predict harvest output, and thus make sound financial decisions.
Sustainability: By offering insights into crop health and soil conditions, the software can help farmers adopt sustainable farming practices. This, in turn, reduces their environmental footprint and promotes biodiversity.
Regulatory Compliance: The software can also assist farmers in adhering to industry regulations and standards. It provides necessary documentation and proof of compliance for audits and certifications.
Final Thoughts on Farm Management Software
Farm management software is an invaluable asset to the agricultural industry. By integrating modern technology with traditional farming practices, these innovative tools are making a huge difference in how farming is conducted.
In the era of agri-tech, farm management software is not just a luxury but a necessity for every modern farmer. It boosts productivity, promotes sustainability, and fosters a future where farming is smarter, more efficient, and more responsive to global needs.
Whether you’re a small-scale farmer looking to improve your operations or a larger agricultural entity seeking to streamline processes, farm management software is the way forward. It’s time to embrace this technology and journey towards more efficient and sustainable farming.
Remember, the future of farming is here, and it’s digital!
Agricultural technology, or agri-tech, is the term used to describe the use of science, technology, and innovation in agriculture. It includes the application of numerous technologies, including robotics, sensors, drones, artificial intelligence, machine learning, big data analytics, and biotechnology, to improve farming practices, increase productivity, efficiency, and sustainability, and address issues facing the global agriculture sector.
Here are some examples of agri-tech:
Drones can survey fields, monitor crops, and spray pesticides.
Robotics can plant seeds, harvest crops, and milk cows.
Big data can track crop yields, identify pests and diseases, and optimize irrigation.
Artificial intelligence develops new crop varieties, improves livestock breeding, and automates decision-making.
The role of agri-tech in world agriculture is quickly expanding. By 2025, it is anticipated that the worldwide agri-tech market will be worth $27.5 billion. The importance of agri-tech is rising for several reasons, including.
The world’s population is growing, and the demand for food is increasing. Agri-tech can help to increase food production to meet this demand.
Climate change is making it more challenging to grow crops. Agri-tech can help farmers to adapt to climate change and reduce their vulnerability to extreme weather events.
Consumers are demanding more sustainable food production. Agri-tech can help farmers to produce food more sustainably and reduce their environmental impact.
Here are some data that show the importance of agri-tech in global agriculture:
In 2019, the global agri-tech market was worth $13.3 billion.
The global agri-tech market is expected to rise at a compound repeal growth rate (CAGR) of 12.3% from 2020 to 2025.
The United States, China, and India are the leading markets for agri-tech.
The top agri-tech sectors are precision agriculture, water management, and crop protection.
Overview of the current state of global agriculture and its challenges:
Overall, agri-tech is expanding quickly and has the potential to revolutionize world agriculture. Increasing food production can aid in climate change adaptation, sustainable food production, and food production. Agri-tech is crucial because of the expanding global population and the rising difficulty posed by climate change.
There are both opportunities and challenges in the current status of global agriculture. While increasing food production has been made possible by technological developments, better farming methods, and higher agricultural productivity, the sustainability and future of agriculture are currently threatened by several urgent issues.
Here is a summary of the situation today and the main difficulties:
Population Growth: By 2050, there will be 9.7 billion people on the planet, putting tremendous pressure on agricultural systems to provide enough food to feed everyone. It is a big problem to feed a growing population while maintaining food security and nutrition for everyone.
Climate Change: Agriculture is highly vulnerable to climate change, which affects crop yields and livestock output through rising temperatures, unpredictable weather patterns, droughts, floods, and catastrophic events. Agriculture must be climate change-adaptive for long-term food security and reduce its effects.
Land Degradation: Arable land is degraded due to soil erosion, desertification, deforestation, and urbanization. Losing fertile land makes supplying food demand more difficult, hindering agricultural productivity.
Reforestation initiatives and sustainable land management techniques are crucial for maintaining soil fertility.
Water Scarcity: Water scarcity is a severe problem that impacts agricultural productivity in many places worldwide. The competition for water supplies between urban, industrial, and farming sectors presents a difficulty.
Increasing the effectiveness of water use in agriculture through precise irrigation, water conservation methods, and better water management procedures is essential.
Biodiversity Loss: Pollinator decline and habitat degradation are two factors in the loss of biodiversity brought on by agricultural expansion and intensification. Biodiversity must be preserved for the long-term viability of agriculture, pollination, and ecosystem resilience. It is crucial to encourage sustainable farming methods and safeguard natural areas.
Food Waste and Loss: The high rates of food waste and loss at various stages, from production to consumption, pose a severe problem to the global food system. Addressing post-harvest failures, enhancing storage and transportation capabilities, and decreasing food waste can increase food availability.
Technology and Knowledge Gap: Although technical breakthroughs can transform agriculture, more access to these technologies is needed, especially in underdeveloped countries.
For sustainable agricultural development, closing the knowledge and technology gap through funding research and development, fostering innovation, and granting access to information is essential.
Rural Poverty and Social Equity: Many smallholder farmers, especially in emerging nations, suffer difficulties due to poverty, restricted access to resources, and a lack of market prospects. Developing an inclusive and sustainable agricultural sector depends on addressing rural poverty, ensuring equitable access to resources and markets, and empowering small-scale farmers.
A comprehensive strategy that invests in research and development adopts climate-smart farming methods, increases market access and infrastructure, champions inclusive policies, and collaborates internationally to address global food security. Agricultural challenges are needed to overcome these obstacles and ensure the sustainability of global agriculture.
Thesis Statement: Agri-tech is revolutionizing the agricultural industry, addressing key challenges, and driving sustainable and efficient food production.
Explanation:
Agricultural technology, commonly known as agri-tech, is a fast-developing discipline that includes different technical discoveries and developments in the farming industry. This thesis claims that by successfully addressing important issues and encouraging sustainable and effective food production, agri-tech is revolutionizing the agricultural sector.
Agri-tech has changed conventional farming methods by incorporating cutting-edge technologies like robotics, artificial intelligence, intelligent sensors, and precision farming. With the aid of these modern instruments, farmers may enhance crop yields, streamline production processes, and reduce resource waste.
Agri-tech enables farmers to make informed decisions, resulting in decreased environmental impact and higher output. It delivers real-time data on soil moisture, nutrient levels, and crop health.
Additionally, agri-tech is essential in tackling major issues that the agricultural sector faces. There is a pressing need to increase food production sustainably because it is predicted that by 2050, there will be 9 billion people on the planet.
Agri-tech answers problems, including scarce land supply, water scarcity, climate change, and pest control. For instance, vertical farming, hydroponics, and aeroponics, which also use less water, make regulated settings possible.
Farmers also use advanced sensors and data analytics to identify and prevent crop diseases and pests, improving crop quality and reducing the need for toxic pesticides.
Agri-tech supports environmental protection and global food security by promoting efficient and sustainable agricultural production. It encourages environmentally friendly agriculture methods that maximize resource usage and lessen their detrimental effects on ecosystems, such as precise irrigation and fertilizing.
Additionally, agri-tech enables the use of renewable energy sources and lowers greenhouse gas emissions caused by traditional farming practices. Agri-tech also improves transparency and traceability in the food supply chain with blockchain technology and food traceability systems, improving food safety and lowering food waste.
In conclusion, agri-tech is a force transforming the agricultural sector, bringing about essential improvements, and tackling pressing issues. By utilizing technology to maximize resource use, boost productivity, and lessen environmental impact, its application results in sustainable and effective food production.
The agriculture industry can meet global food demand while protecting the planet’s resources for future generations by embracing agri-tech.
Some data supports this claim:
The global agri-tech market is expected to reach $41 billion by 2027.
The US holds the record for securing the highest number of deals in the agri-tech space in 2019, and India is second.
In India, the agri-tech sector is valued at $204 million and comprises 1% of the entire agricultural industry. It is expected to reach $24.1 billion by 2025.
Precision farming, sometimes called site-specific agriculture or precision farming, is a farming technique that uses cutting-edge technology and data analytics to optimize agricultural practices on a site-specific basis.
By offering farmers comprehensive information about the diversity within their fields, it seeks to increase agricultural output, minimize resource inputs, and lessen environmental impacts.
Remote sensing, geographic information systems (GIS), GPS, and data analytics software are just a few examples of the many technologies that go into precision agriculture.
Precision agriculture principles can be summarized as follows:
Site-specific management: Precision agriculture knows that different field parts have varied needs and features. Understanding and managing the diversity in the area entails using spatial data, enabling farmers to adapt their methods to the unique requirements of various zones.
Data gathering and analysis: Accurate and timely data must be gathered from various sources, including satellite imaging, airborne drones, sensors, and on-the-ground measurements. Advanced algorithms and software are then used to evaluate and process this data to gain insightful knowledge and make wise judgments.
Variable rate technology: Technology that allows inconsistent rate input application. Precision agriculture enables farmers to apply inputs (such as water, fertilizer, and herbicides) at different rates across several fields.
Farmers may accurately deliver inputs following the unique demands of each zone by using prescription maps produced by data analysis, maximizing resource use, and decreasing waste.
Real-time monitoring: Real-time field conditions monitoring is critical to precision agriculture. Sensors and remote sensing technologies continuously monitor variables, including soil moisture, fertilizer levels, temperature, and crop growth.
Thanks to real-time data, farmers can identify problems and take quick action, improving crop management techniques.
Systems for making decisions: Precision agriculture uses sophisticated software tools and strategies that combine data from many sources.
These technologies offer them actionable insights, recommendations, and predictive models to help farmers make wise choices about planting, irrigation, fertilizer, pest management, and harvesting.
Sustainability and environmental stewardship: Precision agriculture seeks to reduce the adverse effects of agricultural activities on the environment. It encourages sustainable agriculture and aids in decreasing the negative consequences of excessive fertilizer use, water contamination, and soil erosion by maximizing resource use and eliminating input waste.
Application of GPS, drones, and remote sensing technologies in precision agriculture.
GPS, drones, and remote sensing are all technologies used in precision agriculture to collect data about crops, soil, and other agricultural factors. This data can then be used to make more informed decisions about crop management, such as:
Fertilizer application: By using GPS to map the nutrient content of the soil, farmers can apply fertilizer more precisely, avoiding over-fertilization in some areas and under-fertilization in others. This can save money and reduce environmental impact.
Irrigation: Drones can map the water content of the soil, helping farmers irrigate more efficiently. This can save water and improve crop yields.
Pest and disease management: Remote sensing can be used to identify areas of crops that are infested with pests or diseases. This information can then target treatment more precisely, reducing the number of pesticides used.
Yield prediction: Farmers can use remote sensing to predict crop yields by collecting data about crop growth over time. This information can improve planting, harvesting, and marketing decisions.
In addition to these specific applications, GPS, drones, and remote sensing can also collect general data about agricultural fields, such as:
Field boundaries: This information can be used to map areas, which can help plan and manage crop production.
Topography: This information can be used to assess the drainage of fields, which can help to prevent waterlogging and erosion.
Vegetation cover: This information can be used to assess the health of crops and identify areas of potential problems.
Although the application of these technologies in precision agriculture is still in its infancy, a growing body of research shows that they can be utilized to increase crop yields, lower input costs, and safeguard the environment. As these technologies advance, they will contribute more and more to agricultural production.
Here are some specific examples of how GPS, drones, and remote sensing are used in precision agriculture:
In California, drone-based remote sensing is used to map the water content of the soil in almond orchards. This information is to optimize irrigation schedules and reduce water use.
In Iowa, GPS is being used to map cornfield soil nutrient content. This information is used to apply fertilizer more precisely and reduce the risk of over-fertilization.
In Australia, remote sensing monitors the health of wheat crops. This information identifies potential problems and takes corrective action early.
These are only a few applications of remote sensing, GPS, and drones in precision agriculture. As these technologies advance, we anticipate seeing even more cutting-edge uses.
The benefits of precision agriculture are optimizing crop yield, reducing resource wastage, and minimizing environmental impact.
Enhanced crop management: Precision agriculture gives farmers a thorough understanding of their farms through data collection and analysis on soil quality, moisture content, temperature, and nutrient levels.
This knowledge makes precise and timely interventions possible, including targeted irrigation, improved fertilization, and timely pesticide application. Thus, crop health and productivity can be significantly enhanced.
Resource effectiveness: By employing precision agriculture techniques, farmers can make the most of resources like water, fertilizer, and pesticides.
Precision agriculture enables site-specific applications based on the actual demands of various locations instead of uniformly distributing these inputs throughout the field. This lessens resource waste and the damaging effects of excessive resource use on the environment.
Cost savings: Precision agriculture may result in cost savings for farmers. By applying inputs more precisely, farmers can use fewer resources, resulting in cheaper water, fertilizer, and pesticide costs.
Furthermore, with precision agricultural technologies, farmers can more efficiently direct their resources and labor toward the parts of the field that need special attention.
Environmental sustainability: Precision agriculture can have a significant positive impact on the environment. Effectively using water, fertilizers, and pesticides can decrease the chance of contaminating soil and water resources.
Precision agriculture also encourages IPM approaches, which stress the use of biological control measures and reduce dependency on chemical pesticides.
Increased yield and quality: Quality and production are improved because farmers may use precision agriculture techniques to monitor crop development and address problems closely.
Farmers can avoid output losses and maintain crop quality by spotting and correcting problems early on, such as nutrient deficits, pests, or illnesses. The most effective use of resources also enhances plant health, increasing yields and improving crop quality.
Data-driven decision-making: Precision agriculture relies on the gathering and processing a tremendous quantity of data, including sensor readings, soil samples, satellite imaging, and weather information.
By utilizing this data, farmers may choose crops, manage resources, and arrange planting schedules more intelligently. Data-driven insights aid in optimizing farming practices and increasing overall output.
Indoor and Vertical Farming:
Innovative agricultural techniques like indoor and vertical farming are meant to overcome conventional agriculture’s drawbacks, such as the scarcity of available land, climatic dependence, and resource inefficiency.
These farming techniques, which use technology and regulate surroundings, make cultivating crops in enclosed spaces such as buildings, warehouses, and even skyscrapers possible.
Indoor agriculture raises plants in enclosed spaces, such as greenhouses or specially constructed rooms, where environmental conditions, such as temperature, light, humidity, and nutrient levels, may be accurately managed.
Despite the weather or season outside, this enables farmers to provide the best crop growth conditions. Indoor farms frequently use modern monitoring and automation technologies, hydroponic or aeroponic systems, and artificial lighting systems to guarantee plant development.
The concept of indoor farming is elevated by vertical farming. Vertical farms make the most available areas using vertical stacks or levels rather than conventional horizontal farming sites.
These farms frequently include tall buildings with several levels or shelves where plants are produced. By stacking the growth zones, vertical farms can significantly enhance the production capacity per square foot of land compared to conventional agriculture.
Utilization of controlled environments, hydroponics, and aeroponics.
Data-driven plant growth techniques, including hydroponics, aeroponics, and controlled conditions, are all used to grow plants. Sensors are employed in controlled environments to keep track of environmental factors, including temperature, humidity, and light levels.
This data is then used to control the environment, for example, by modifying the heating, cooling, and lighting systems.
Sensors are employed in hydroponics and aeroponics to keep track of the pH and nutrient concentrations in the nutrient solution. The nutrient solution is then adjusted using this data by adding or eliminating nutrients.
Using data in controlled environments like hydroponics and aeroponics can lead to several benefits.
Increased crop yields,
Improved plant quality,
Reduced water usage,
Reduced pesticide use,
Increased energy efficiency
For instance, a University of Arizona research discovered that tomatoes grown in a controlled environment with data-driven irrigation produced 30% more fruit than those grown in a conventional field.
According to another study from the University of California, Davis, lettuce grown in an aeroponic system with data-driven fertilizer management produced 50% more than lettuce grown in a conventional soil-based system.
Although it is still in its infancy, using data in controlled conditions, hydroponics, and aeroponics has the potential to change agriculture. As technology advances, we might anticipate even more significant advantages from these plant-growing techniques.
Here are some specific examples of how data is in controlled environments, hydroponics, and aeroponics:
Monitoring plant growth: Sensors monitor plant growth, such as leaf size, stem length, and fruit development. This data can identify plants that are not growing as well as they should and take corrective action.
Optimizing nutrient levels: Sensors monitor nutrient levels in the water or solution. This data can be used to adjust the nutrient levels to ensure the plants get the nutrients they need.
Controlling the environment: Sensors monitor the climate, such as temperature, humidity, and light levels. Data can be used to manage the environment to create optimal conditions for plant growth.
Preventing pests and diseases: Sensors can monitor for pests and diseases. To take preventive action, such as spraying plants with pesticides or fungicides.
Data use in controlled conditions, hydroponics, and aeroponics are fast-expanding fields. As technology advances, we may anticipate that these plant-growing techniques will offer even more advantages.
Indoor and vertical farming has several advantages over traditional agriculture, including:
Year-round agricultural production is possible since indoor and vertical farms are not weather-dependent. This advantage is significant in areas with harsh temperatures or variable weather patterns.
Space effectiveness: Compared to conventional farms, indoor and vertical farms can produce more food per square foot of land. This is because they can stack plants vertically, better using available space.
Reduced water consumption: Indoor and vertical farms can use up to 90% less water than typical farms. This is because they employ a closed-loop irrigation system in which the water is recycled and used again.
Reduced pesticide use: Indoor and vertical farms can use fewer pesticides than conventional farms. This makes it more challenging for pests to get inside, as they are cultivated in a controlled atmosphere.
Higher crop quality: Compared to typical farms, indoor and vertical farms can yield crops of higher quality. This is so that variables like temperature, humidity, and light can be better managed because they can be grown in a more controlled environment.
A study by the University of Arizona found that vertical farms can produce up to 100 times more food per square foot than conventional farms.
A National Resources Defense Council study found that vertical farms can use up to 90% less water than traditional farms.
A study by the University of California, Davis found that vertical farms can use up to 90% fewer pesticides than traditional farms.
Overall, indoor and vertical farming has many benefits compared to traditional agriculture. They are more effective, utilize less water, and yield higher-quality crops. Indoor and vertical farming will become more crucial as the world’s population and food demand rise.
Reduced transportation costs: Indoor and vertical farms can be located closer to urban areas, which reduces the need to transport food long distances. This can save energy and reduce pollution.
Creates jobs: Indoor and vertical farming can create jobs in urban areas, which can help reduce poverty and improve life.
Sustainable: Indoor and vertical farming can be more sustainable than traditional agriculture, using less water and land.
Genetic Engineering and Biotechnology
Genetic engineering and biotechnology are rapidly emerging as powerful tools for crop improvement. These technologies offer the potential to develop crops with enhanced yields, nutritional quality, and resistance to pests, diseases, and environmental stresses.
Traditional plant breeding methods have been used for centuries to improve crop varieties. However, these methods can be slow and inefficient, often limited by the genetic diversity of the available germplasm.
Genetic engineering and biotechnology offer several advantages over traditional breeding methods.
Introducing genes from other organisms can broaden the genetic diversity of crop varieties.
The ability to precisely insert genes into the plant genome can increase the chances of successful gene expression.
The ability to develop crops with traits impossible to achieve through traditional breeding, such as resistance to new pests or diseases.
As a result of these advantages, genetic engineering and biotechnology have been used to develop some commercially successful GM crops, including
Bt corn, which is resistant to the European corn borer.
Roundup Ready soybeans are tolerant to the herbicide glyphosate.
Golden rice is enriched with beta-carotene, a precursor to vitamin A.
These GM crops have the potential to raise crop yields, decrease pesticide use, and enhance food security and nutrition. GM crops are controlled in many countries, yet public skepticism over their safety exists.
Biotechnology and genetic engineering have a bright future in agricultural enhancement. These innovations could transform agriculture and solve the problems caused by an increasing world population. However, before extensively using GM crops, more studies and assessing their safety are crucial.
Here are some specific examples of how genetic engineering and biotechnology are used in crop improvement:
Increasing crop yields: Genetically engineered crops can be developed with increased tolerance to drought, heat, and other abiotic stresses. This can help to improve crop yields in areas with challenging growing conditions.
Improving nutritional quality: Genetic engineering can enrich crops with fundamental nutrients, such as vitamins, minerals, and proteins. This can help to improve the nutritional status of people who rely on these crops for food.
Reducing the use of pesticides: Genetically engineered crops can be developed with resistance to pests and diseases. This can help reduce pesticide use, which can have harmful environmental and health effects.
Developing new crops: Genetic engineering can create new crops with desirable traits, such as improved taste, texture, or shelf life. This can help expand the range of available crops to consumers.
Biotechnology and genetic engineering are tremendous tools with the potential to transform agriculture. Proper use is crucial to guaranteeing that the advantages of new technologies outweigh the risks.
Controversies and ethical considerations surrounding genetic engineering.
Here are some of the most common ethical considerations surrounding genetic engineering:
The definition of “normality.” Who decides which traits are typical and which constitute a disability or disorder? This is a complex question with no easy answer, and it will likely differ for different cultures and societies.
The potential for discrimination. If genetic engineering is used to create “designer babies” with enhanced traits, it could lead to a society where people are discriminated against based on their genetic makeup. This could hurt social mobility and equality.
The safety of genetic engineering. We still need to learn a lot about the long-term effects of genetic engineering. It could lead to unintended consequences, such as developing new diseases or creating “superbugs” resistant to antibiotics.
The distribution of benefits. If genetic engineering is only available to the wealthy, it could widen the gap between the rich and the poor. This concern has been raised in the context of other new technologies, such as gene therapy.
In addition to the ethical considerations listed above, several other ethical issues have been raised in the context of genetic engineering. These include
The potential for misuse of genetic engineering. Genetic engineering could be used for malicious purposes, such as creating biological weapons or creating designer babies with desirable traits by some people but not others.
The impact of genetic engineering on the climate. Genetically engineered organisms could hurt the environment by disrupting ecosystems or creating new pests and diseases.
Genes are now considered to be intellectual property, and this raises ethical questions. For example, who should be able to patent genes? What are the implications of patenting genes for the availability of genetic testing and treatment?
These are just a few moral concerns that must be considered as genetic engineering advances. It is crucial to have a public conversation about these issues to decide how to utilize this technology responsibly.
Precise and effective monitoring and management of cattle are achieved through sensors, data analytics, and information technology (IT). It uses various technologies, such as:
Sensors: Sensors can collect data on various animal parameters, such as temperature, weight, activity, behavior, and health.
Data analytics: Data analytics can analyze the data collected by sensors to identify patterns and trends that can evolve animal management.
Information technology: Information technology can store, manage, and share data collected by sensors and data analytics.
The goal of PLF is to improve the productivity, health, and welfare of livestock while also reducing the environmental impact of livestock production. PLF can be used to:
Detect diseases early: PLF can be used to monitor animal health and detect diseases early, which helps to prevent the spread of illness and improve animal welfare.
Improve feed efficiency: PLF can monitor animal feed intake and identify animals not eating enough or too much. This information can be used to adjust feed rations and improve feed efficiency.
Optimize breeding: PLF can monitor animal reproduction and identify animals ready to breed. This information can be used to improve breeding efficiency and increase the productivity of livestock herds.
Reduce environmental impact: PLF can be used to monitor animal manure production and identify ways to reduce manure emissions, which can help reduce the environmental impact of livestock production.
The scope of PLF is constantly expanding as new technologies are developed. Some emerging areas of PLF include:
Artificial intelligence (AI) analyzes data and identifies patterns that would be challenging to detect in humans.
Wearable sensors are used to track animal movement and behavior.
The use of drones to collect data on livestock herds from the air.
PLF has the power to completely alter animal management. By giving farmers more precise and timely information, PLF can enhance livestock productivity, health, and welfare while lowering livestock production’s environmental impact.
Here are some of the benefits of precision livestock farming:
Improved animal health: PLF can help detect diseases early, which can help prevent the spread of disease and improve animal welfare.
Increased productivity: PLF can help optimize feed intake and breeding, increasing livestock herds’ productivity.
Reduced environmental impact: PLF can help to minimize manure emissions and improve water quality.
Improved decision-making: PLF can provide farmers with more accurate and timely information, which can help them make better animal management decisions.
Integration of sensors, data analytics, and automation in livestock management.
One area that is expanding quickly and potentially changing how we produce and care for animals completely is integrating sensors, data analytics, and automation in livestock management.
Farmers may better understand their livestock and make more educated management decisions by utilizing sensors to gather information on their animals’ health, behavior, and environmental circumstances. This may result in enhanced animal well-being, high output, and less environmental effect.
Some of the specific benefits of integrating sensors, data analytics, and automation in livestock management include the following:
Early detection of diseases: Sensors can monitor animal health indicators such as temperature, heart rate, and respiration. This data can be analyzed to identify animals at risk of developing diseases, allowing farmers to intervene early and prevent the spread of illness.
Improved feeding and breeding programs: Sensors can track animal feed intake and nutrient levels, optimizing feeding programs and ensuring animals get the nutrients they need to thrive.
Sensors can also be used to monitor animal breeding behavior, which can help farmers identify and select the best breeding stock.
Optimized environmental conditions: Sensors can monitor environmental conditions such as temperature, humidity, and air quality.
To optimize the environment for animal comfort and productivity. For example, farmers can use this data to adjust ventilation systems or provide supplemental heat during cold weather.
Reduced labor costs: Automation can help to reduce labor costs by automating tasks such as feeding, watering, and manure removal. This can free up farmers to focus on other tasks, such as animal health and welfare.
Integrating sensors, data analytics, and automation in livestock management is still early. Still, it could revolutionize how we raise and care for animals, as the tech. As we continue to develop, we can await to see even more benefits from this approach.
Smart collars: Smart collars are devices placed around animals’ necks. These collars contain sensors that monitor animal health indicators such as temperature, heart rate, and activity levels.
The data from these sensors can be transmitted to a cloud-based platform, which can be analyzed to identify animals at risk of developing diseases or other health problems.
Feeding systems: Several automated feeding systems are available for livestock farmers. These systems use sensors to monitor animal feed intake and nutrient levels.
The data from these sensors can optimize feeding programs and ensure that animals get the nutrients they need to thrive.
Environmental monitoring systems: Several ecological monitoring systems are available for livestock farmers.
These systems use sensors to monitor environmental conditions such as temperature, humidity, and air quality. The data from these sensors can be used to optimize the environment for animal comfort and productivity.
Innovative farming technologies for livestock
The Internet of Things (IoT) has completely transformed our lives and work. The animal care sector is also being significantly impacted. IoT and wearable technology are being utilized to track the whereabouts and health of animals, enhance their welfare, and boost productivity.
Animal wearables are often compact, lightweight, and simple to affix to an animal’s body. The animal’s location, movement, health, and behavior can all be monitored using several sensors. The data collected by these devices can be sent to a cloud-based platform for analysis.
There are many benefits to using wearable devices and IoT in animal tracking and health monitoring. These benefits include:
Improved animal welfare: Wearable devices can help monitor animals’ health and behavior, identifying problems early on and providing timely intervention. This can lead to improved animal well-being and productivity.
Increased productivity: Wearable devices can help track animals’ locations, improving herd management and reducing the risk of animals getting lost. This can lead to increased productivity and efficiency.
Reduced costs: Wearable devices can help to reduce the cost of animal care by providing early warning of problems and helping to prevent diseases. They can also help improve animal management efficiency, leading to cost savings.
Animal tracking and health monitoring can be done with wearable technology and IoT solutions. Among the most well-liked remedies are:
GPS trackers: These devices use GPS technology to track animals’ locations. They can be used to track the movement of animals within a herd or the exercise of individual animals.
Activity trackers: These devices track animals’ activity levels. They can monitor the amount of exercise animals get and identify animals at risk of developing health problems.
Health monitors: These devices track animals’ health. They can monitor heart rate, body temperature, and other vital signs.
Although it is still in its infancy, the use of wearable technology and the Internet of Things to track and monitor animal health has the potential to ultimately alter how we care for animals. These innovations can raise output, lower costs, and enhance animal welfare.
Here are some instances of how IoT and wearable technology are utilized to track and monitor the health of animals:
Farmers are using wearable devices to track the location of their livestock. This helps them to ensure that their animals are not getting lost and that they are getting enough exercise.
Veterinarians are using wearable devices to monitor their patients’ health. This helps them identify problems early on and provide timely treatment.
Zoologists are using wearable devices to track the movement of wild animals. This helps them understand these animals’ behavior and protects them from harm.
Wearable devices and IoT are rapidly becoming popular in animal tracking and health monitoring. As these technologies continue to evolve, we can expect to see even more innovative ways to use them to improve the lives of animals.
Artificial intelligence (AI) and machine learning (ML) are rapidly transforming the healthcare industry, with one of the most promising areas being early disease detection and Prevention.
AI-powered tools can analyze vast amounts of data, including medical records, genetic information, and lifestyle factors, to identify patterns and trends that may indicate disease onset and develop personalized prevention plans and interventions. These can help improve patient outcomes and reduce healthcare costs.
AI and ML use for early disease detection and Prevention:
Image recognition: AI-powered image recognition tools analyze medical images, such as X-rays, MRI scans, and pathology slides, to identify signs of disease. For example, AI-powered devices effectively detect diabetic retinopathy, skin cancer, and breast cancer.
Natural language processing: AI-powered natural language processing (NLP) tools can analyze medical records and other text-based data to identify potential health risks. For example, NLP tools identify patients at risk for heart disease, stroke, and Alzheimer’s.
Genetic analysis: AI-powered genetic analysis tools identify genetic markers associated with different diseases. This information develops personalized prevention plans for people at increased risk for certain conditions.
Risk prediction: AI-powered risk prediction tools estimate a person’s risk of developing a disease. This information can then be used to target preventive interventions for people who are most likely to benefit from them.
AI and ML are being used for early disease detection and Prevention today:
Google Health: Google Health uses AI to analyze a person’s medical records, lifestyle data, and genetic information to identify potential health risks. The app then provides personalized recommendations for Prevention and early detection.
IBM Watson Health: IBM Watson Health uses AI to analyze medical images and other data to identify signs of disease. Healthcare providers use the platform to make more informed diagnoses and treatment decisions.
Preventive: Preventive uses AI to analyze a person’s medical records, lifestyle data, and genetic information to develop personalized prevention plans. Healthcare providers use the company’s platform to help people reduce their risk of developing chronic diseases.
Agri-tech and Supply Chain Management
Farm Management Systems
Farm management software (FMS) and decision support systems (DSS) are essential tools to help farmers make better decisions about their operations. FMS can help farmers track and manage their finances, crops, livestock, and other assets.
DSS can help farmers analyze data and predict crop yields, weather patterns, and other factors affecting their bottom line.
FMS typically includes the following features:
Financial management: Track income and expenses, create budgets, and generate financial reports.
Crop management: Track crop planting, harvesting, and yields.
Livestock management: Track livestock inventory, feed consumption, and health records.
Asset management: Track equipment, machinery, and other assets.
Data analysis: Collect and analyze data from various sources, such as weather forecasts, soil maps, and crop yields.
Predictive modeling: Use data analysis to predict future crop yields, weather patterns, and other factors.
Decision optimization: Use predictive models to help farmers make better decisions about their operations.
Benefits of using FMS and DSS
Improved efficiency: FMS and DSS can help farmers automate tasks and streamline operations.
Increased profitability: FMS and DSS can help farmers make better decisions that increase profits.
Reduced risk: FMS and DSS can help farmers mitigate risk by providing better information about their operations.
Improved compliance: FMS and DSS can help farmers track regulatory compliance requirements.
Data analytics, IoT, and AI are optimized farms:
Precision irrigation: IoT sensors can measure soil moisture levels and send this data to a cloud-based analytics platform. The platform can then use this data to determine the optimal irrigation schedule for each field, which can help reduce water usage and improve crop yields.
Disease detection: Drones with cameras and sensors scan fields for signs of disease. AI algorithms can then analyze this data to identify and classify diseases early on. This allows farmers to take action to prevent the spread of disease and protect their crops.
Weed control: IoT sensors can monitor weed growth in fields, enabling the creation of a weed management plan that targets weeds early on and minimizes the use of herbicides.
Animal health monitoring: IoT sensors track livestock health, such as their temperature, weight, and activity levels. Identifying sick or at-risk animals allows farmers to intervene early and prevent the spread of disease.
Blockchain Technology in Agriculture
A distributed ledger blockchain technology can securely and openly record transactions. A computer network is used to maintain the shared database. The database is replicated across the network’s computers, and all transactions are captured in real-time. This makes it challenging to alter the data.
Blockchain has several potential applications in supply chain management:
Traceability: Blockchain can track the movement of goods throughout the supply chain. This can help to ensure that products are authentic and that they have been handled safely and ethically.
Transparency: Blockchain can provide clarity in the supply chain. This means that all stakeholders can see the same information, which can help to build trust and reduce fraud.
Efficiency: Blockchain can help improve the supply chain’s efficiency. For example, it can automate payments and track inventory levels.
Security: Blockchain is a very secure technology that can help to protect sensitive data.
Specific use cases of blockchain in supply chain management:
Food traceability: Blockchain can track the movement of food products from farm to fork. This can help to ensure that food is safe and that it has been produced sustainably.
Logistics: Blockchain can track the movement of goods in the logistics industry, helping to improve efficiency and reduce costs.
Intellectual property: Blockchain tracks intellectual property ownership and can help prevent counterfeiting and protect intellectual property rights.
Here are some case studies of successful blockchain implementations in the agriculture industry:
IBM Food Trust is a consortium of food companies, retailers, and suppliers that use blockchain technology to track the movement of food products through the supply chain. The Food Trust has been used to track outcomes such as leafy greens, beef, and pork.
In one case study, the Food Trust was used to track a shipment of leafy greens from farm to fork. The tracking data showed that the gardens were harvested on a specific date and time and kept at a safe temperature throughout the supply chain. This information helped to ensure that the greens were safe to eat.
Provenance is a blockchain-based platform that tracks the provenance of food products. Provenance uses blockchain technology and IoT sensors to collect data about food products from the farm to the fork.
This data includes information about the product’s ingredients, where it was grown, and how it was processed. The data is then stored on the blockchain, accessible to all stakeholders in the supply chain. This information helps to ensure that food products are safe and traceable.
AgriDigital is an Australian company that uses blockchain technology to track livestock movement. AgriDigital’s platform allows farmers, processors, and retailers to share information about livestock, such as their weight, health status, and location.
This information helps to ensure that livestock are treated humanely and that they are safe to eat.
AgriDigital is an Australian company that uses blockchain technology to track livestock movement. Its platform allows farmers, processors, and retailers to share information about livestock, such as their weight, health status, and location. This information helps ensure that livestock are treated humanely and eat safely.
Agri-tech and Sustainability
Sustainable farming practices
Sustainable agriculture is a holistic approach to farming that seeks to meet the needs of the present without compromising the ability of future generations to meet their own needs. It is based on environmental protection, economic viability, and social equity principles.
Although there are many different sustainable agriculture methods, some of the most popular ones are as follows:
Agroforestry is a farming system that integrates trees and crops. It can provide various benefits, including improved soil fertility, reduced erosion, and increased biodiversity.
Organic farming is a system of agriculture that prohibits the use of synthetic pesticides, herbicides, and fertilizers. It relies on natural processes to control pests and diseases and maintain soil fertility.
Permaculture is a system of designing agricultural systems based on ecology principles. These systems are designed to be self-sufficient and resilient and to provide for the needs of people and the environment.
Integrated pest management (IPM): This is a system of managing pests that uses various methods, including biological control, cultural practices, and chemical controls. IPM is designed to minimize the use of pesticides while still effectively controlling pests.
Sustainable agriculture has several benefits, including:
Improved environmental quality: Sustainable agriculture practices can help to reduce pollution, conserve water, and protect biodiversity.
Increased economic viability: Sustainable agriculture can be profitable for farmers without synthetic inputs.
Improved social equity: Sustainable agriculture can help to improve the lives of farmers and rural communities.
There is growing evidence that sustainable agriculture can effectively address the challenges of food production, environmental protection, and economic development.
For example, a study by the United Nations Environment Programme found that sustainable agriculture could help to reduce greenhouse gas emissions by up to 40%.
Some challenges to adopting sustainable agriculture include investment in research and development, access to markets for sustainable products, and changes in government policies. However, the potential benefits of sustainable agriculture are significant, and there is a growing movement to promote its adoption.
In the United States, the number of certified organic farms has increased from 10,000 in 1990 to over 20,000 in 2022.
The global market for organic food is expected to reach $270 billion by 2025.
A study by the World Resources Institute found that sustainable agriculture could help to reduce poverty by up to 20%.
Sustainable agriculture is crucial for the future of food production. Using sustainable methods, farmers may improve their economic well-being, contribute to environmental protection, and guarantee a steady food supply for future generations.
Climate-smart agriculture (CSA) is an integrated approach to managing agricultural systems to achieve three objectives:
Sustainably increasing agricultural productivity and incomes.
Adapting and building resilience to climate change
Reducing and removing greenhouse gas emissions
CSA is relevant in a changing climate because it helps to address the challenges that climate change poses to agriculture. These challenges include:
Increased variability in weather patterns
More extreme weather events
Changes in temperature and precipitation patterns
Increased pests and diseases
CSA can help to address these challenges by:
Using climate-resilient crops and varieties
Improving water management
Reducing soil erosion
Managing pests and diseases
Storing carbon in soils
There is growing evidence that CSA can effectively address climate change challenges.
For example, a study by the Food and Agriculture Organization of the United Nations (FAO) found that CSA practices can increase crop yields by up to 20%. Another study found that CSA can reduce greenhouse gas emissions by up to 40%.
Here are some examples of CSA practices being used worldwide:
Conservation agriculture is a set of rules that help protect the soil and conserve water. These practices include planting cover crops, using no-till or minimum-till methods, and rotating crops.
Integrated pest management is a control system that uses various methods to reduce pests without harming the environment. These methods include crop rotation, biological control, and the use of pesticides only as a last resort.
Water harvesting is a way to collect and store rainwater for later use. This can help to reduce water stress during dry periods.
Agroforestry is a system of agriculture that integrates trees with crops and livestock. This can help to improve soil fertility, reduce erosion, and provide shade for livestock.
CSA is an integral part of the global effort to address climate change. By helping to increase agricultural productivity, adapt to climate change, and reduce greenhouse gas emissions, CSA can help to ensure that food security is maintained in a changing climate.
Here are some data that support the relevance of CSA in a changing climate:
A study by the International Food Policy Research Institute found that CSA could help to reduce global hunger by up to 120 million people by 2050.
A study by the FAO found that CSA could reduce greenhouse gas emissions from agriculture by up to 40% by 2030.
A study by the World Bank found that CSA could generate an additional $1.5 trillion in economic benefits by 2050.
These data show that CSA has the potential to make a significant contribution to addressing the challenges of climate change and food security.
Conclusion
Key technologies driving global agriculture:
Precision farming uses sensors, drones, and other technologies to collect data about crops and soil, which can then be used to optimize inputs such as water, fertilizer, and pesticides.
Smart irrigation uses sensors to monitor soil moisture and weather conditions and automatically adjusts irrigation systems to ensure crops get the proper water.
Genetically modified crops have been changed to resist pests, diseases, or herbicides or have improved yields or nutritional content.
Automated livestock farming uses robots and other technologies to feed, water, and monitor livestock, which can reduce labor costs and improve animal welfare.
Blockchain technology can track food movement from farm to fork, which can help ensure food safety and traceability.
The adoption of these technologies is challenging, however. Some farmers may be reluctant to adopt new technologies, and there may be concerns about the safety and ethics of some technologies, such as genetically modified crops.
However, the potential benefits of these technologies are significant, and they are likely to play an increasingly important role in global agriculture in the coming years.
The future of agri-tech is bright, and data plays a significant role in driving innovation. Here are some potential advancements in agri-tech:
Agri-tech uses technology to improve agriculture’s efficiency, productivity, and sustainability. It can play a significant role in ensuring a sustainable, food-secure future.
Here are some ways in which agri-tech can help achieve these goals:
Increased crop yields: Agri-tech can help increase crop yields by using precision agriculture techniques, such as remote sensing and data analytics, to optimize crop production. For example, a study by the University of California, Davis, found that precision agriculture can increase crop yields by up to 20%.
Reduced water use: Agri-tech can help reduce water use by using water-efficient irrigation systems and developing drought-resistant crops. For example, a study by the World Economic Forum found that agri-tech will likely be 10% of global water use by 2030.
Lower greenhouse gas emissions: Agri-tech can help lower greenhouse gas emissions by reducing synthetic fertilizers and pesticides and developing carbon-neutral farming practices.
For example, a study by the International Food Policy Research Institute found that agri-tech could help to reduce global greenhouse gas emissions by up to 10% by 2050.
Improved food safety: Agri-tech can help improve food safety by using sensors and data analytics to track food movement through the supply chain. For example, a study by the Food and Agriculture Organization of the United Nations found that agri-tech could help to reduce foodborne illness by up to 50%.
Empowered farmers: Agri-tech can help empower farmers by providing access to information, markets, and financial services. For example, a study by the World Bank found that agri-tech could help to increase the incomes of small-scale farmers by up to 30%.
Here are some data to support the claims made above:
A study by the University of California, Davis found that precision agriculture can increase crop yields by up to 20%.
A study by the World Economic Forum found that agri-tech could help to save up to 10% of global water use by 2030.
A study by the International Food Policy Research Institute found that agri-tech could help to reduce global greenhouse gas emissions by up to 10% by 2050.
A study by the Food and Agriculture Organization of the United Nations found that agri-tech could help to reduce foodborne illness by up to 50%.
A study by the World Bank found that agri-tech could help to increase the incomes of small-scale farmers by up to 30%.
As technology continues to develop, we will see even more ways in which agri-tech can help to create a more sustainable and food-secure future.
Robotics has emerged as a transformative force in various industries, and agriculture is no exception. Farmers and agri-tech companies continuously leverage advanced robotics to solve various agricultural challenges. Among the many applications of robotics in farming, pest control is a promising field poised to revolutionize the agricultural sector. Let’s dive deep into how robotics pave the way for efficient and sustainable pest control in agriculture.
Understanding the Challenge
Pests significantly threaten agriculture, damaging crops and drastically reducing yield. Traditional pest control methods often involve chemical pesticides, which, while effective, have several drawbacks. They can harm the environment, contaminate water sources, and pose risks to the health of humans and non-target organisms. Moreover, repeated use of certain pesticides can lead to pest resistance, diminishing their effectiveness over time.
As such, the agricultural sector needs innovative pest control methods that are efficient, precise, and environmentally friendly. This is where robotics comes in.
Robotics in Pest Control
Robotics technology offers a novel approach to pest control. Robots can be designed and programmed to identify and eliminate pests in a highly targeted manner, reducing reliance on broad-spectrum pesticides. This makes pest control more efficient and significantly minimizes environmental and health risks.
Robotic pest control systems often employ advanced technologies like machine learning, artificial intelligence (AI), and computer vision to detect and identify pests. Equipped with high-resolution cameras and sensors, these robots can traverse agricultural fields, identify pests in real time, and take appropriate action.
For instance, some robots use mechanical means to eliminate pests, such as trapping or crushing. Others are equipped with precision spraying systems that only deliver targeted doses of pesticides to infected areas, reducing the overall volume of pesticides used.
The Potential of Robotic Pest Control
The potential benefits of employing robotics for pest control in agriculture are considerable:
Precision and Efficiency: Robots can accurately identify pests and deliver targeted treatments, reducing pesticide use and increasing efficiency.
Non-Stop Operation: Unlike humans, robots can work continuously, day and night, improving the timeliness and frequency of pest control.
Data Collection: Robotic systems can collect valuable data about pest populations and the effectiveness of control strategies, providing insights for future decision-making.
Reduced Environmental Impact: Robots can significantly lower the environmental impact of pest control practices by reducing reliance on chemical pesticides and delivering them in a targeted manner.
Safety: Using robots for pest control can reduce human exposure to harmful pesticides, promoting safety for farm workers.
Conclusion
Adopting robotics for pest control in agriculture is a significant step towards sustainable and precision farming. While challenges such as high initial costs, the need for technical skills, and regulatory issues remain, the potential benefits make it an exciting area for development and research. By merging the precision and efficiency of robotics with the growing need for sustainable farming practices, we can address the global challenge of pest control. This integration will safeguard our agricultural productivity and contribute to our environment’s health, creating a sustainable and prosperous future for all.
In the world of modern agriculture, the need for efficient water management is a pressing issue. Climate change and the rapid depletion of water resources necessitate a shift from traditional irrigation methods towards more innovative and sustainable techniques. Two notable approaches have risen to the forefront: automated and smart irrigation systems. Both embody the concept of precision irrigation, an advanced watering strategy geared towards conserving water and boosting productivity.
Understanding Precision Irrigation Systems:
Precision irrigation refers to the controlled, precise application of water to crops. The goal is to apply the right amount of water at the right time and place. By leveraging state-of-the-art technology, precision irrigation transforms the agricultural sector, enabling farmers to maximize yield, conserve water resources, and reduce operational costs.
Automated Irrigation Systems:
Automated irrigation systems are among the most advanced forms of precision irrigation. These systems take over the time-consuming task of manually watering fields, ensuring optimal water usage, and freeing farmers to focus on other important tasks.
An automated irrigation system uses a network of sensors and controllers programmed to monitor soil moisture levels, weather conditions, and crop water needs. When the sensors detect that crops require water, the system automatically initiates irrigation. This not only eliminates the guesswork of when to water crops, but it also promotes water conservation by preventing overwatering.
Automated irrigation systems offer many benefits. They can lead to substantial water and energy savings, improve crop yields, and minimize the labor required for irrigation. Additionally, they contribute to environmental sustainability by reducing water runoff, soil erosion, and the leaching of fertilizers and pesticides into groundwater.
Smart Irrigation Systems:
While automated systems manage irrigation tasks, smart irrigation systems take it a step further by utilizing advanced technologies such as Artificial Intelligence (AI), Machine Learning (ML), and the Internet of Things (IoT). A smart irrigation system is essentially an automated irrigation system with added layers of intelligence and interactivity.
Smart irrigation systems collect and analyze data from various sources, such as soil moisture sensors, weather forecasts, and crop evapotranspiration rates. This data is then processed using advanced algorithms to make real-time irrigation decisions, which optimize water usage and enhance crop productivity. The systems can adapt to changing conditions, adjusting the watering schedule and volume as necessary.
Smart irrigation systems often come with user-friendly interfaces, allowing farmers to monitor and control their irrigation from anywhere using a smartphone or a computer. This feature gives farmers greater control and flexibility over their irrigation practices, further enhancing efficiency and productivity.
Final Thoughts:
As our world grapples with the effects of climate change and diminishing water resources, the importance of efficient irrigation methods cannot be overstated. Automated and smart irrigation systems embody the potential of technology to usher in a more sustainable future for agriculture. Investing in these precision irrigation techniques can conserve our precious water resources, boost agricultural productivity, and foster a more sustainable planet. The agricultural industry must continue to adopt and refine these innovative systems, creating a smarter, more sustainable future for all. Precision irrigation offers a path toward this goal through automated and smart systems, revolutionizing the farming industry one drop at a time.
Variable-Rate Technology (VRT) and Variable Rate Application (VRA) are integral components of modern precision agriculture, a farming management concept that uses technology to optimize returns on inputs while preserving resources. Precision agriculture strives to define a decision-support system for the entire agricultural industry, and VRT and VRA are central to that objective. They offer a solution to the age-old agricultural problem of variability within fields, enabling farmers to maximize efficiency and improve yields.
Understanding VRT and VRA
Variable-Rate Technology (VRT) is a system that allows machinery and equipment used in farming to work at varying rates. That means the rate of application of an input (such as fertilizer, seed, or pesticides) changes across a field to match the requirement of the crop at that specific location. This contrasts with a traditional ‘blanket’ approach, where the same amount of inputs is applied across the entire field.
Complementing VRT is the Variable Rate Application (VRA) of inputs. VRA refers to the application of different types and quantities of agricultural inputs according to the specific needs of a given area. This is achieved using GPS and GIS technology to map the field, sensors to measure variation in the field, and equipment capable of changing the rate of application on the fly. Together, VRT and VRA allow farmers to accurately apply the right type and amount of inputs to the right place at the right time.
Benefits of VRT and VRA
Optimized Resource Usage: By tailoring the application of inputs to the needs of specific areas within a field, VRT and VRA can significantly reduce wastage. Farmers can save on inputs and reduce their environmental footprint.
Increased Yields: Since the precise amount of inputs is applied where needed, VRT and VRA can boost the efficiency of resource utilization, leading to increased crop yields and profitability.
Improved Sustainability: VRT and VRA contribute to sustainable farming practices. They reduce over-application of fertilizers and pesticides, reducing runoff and contamination of water bodies.
Data-Driven Decisions: VRT and VRA rely on data about soil conditions, crop health, weather patterns, and more. This data-driven approach supports more informed decision-making, leading to better management of resources and crop health.
Implementing VRT and VRA
Implementing VRT and VRA technologies requires investment in technology and training. Farmers need suitable equipment that can vary input rates as required, such as variable rate spreaders, sprayers, or planters. Additionally, they need GPS and GIS technology to map fields accurately, along with sensors to measure soil conditions and crop health.
They also need software that can interpret this data and make accurate recommendations for varying input application rates. Training is crucial for operators to understand and effectively utilize these technologies.
Challenges and the Future
While the benefits of VRT and VRA are substantial, implementing these technologies does come with challenges. The cost of equipment and technology can be high, and there can be a steep learning curve for farmers unfamiliar with the technology. Connectivity issues in rural areas can also pose problems.
Despite these challenges, the future of VRT and VRA looks bright. As technology advances and becomes more affordable, more farmers are likely to adopt VRT and VRA. Furthermore, growing awareness of the need for sustainable farming practices is likely to drive further adoption of these technologies. In conclusion, Variable-Rate Technology (VRT) and Variable Rate Application (VRA) represent a significant step forward in precision agriculture. These technologies allow farmers to optimize the use of resources, improve yields, and promote sustainability. With continued investment and development, they are set to transform the future of agriculture.
Harnessing Innovation and Sustainability for Successful Farming
As our world evolves, so do the techniques and technologies shaping successful farming. To remain competitive in this rapidly changing industry, it’s crucial to stay updated on the latest developments and incorporate them into your farming practices. In this article, we’ll explore the key strategies and innovations to enhance your farming success in 2024 and the years ahead, focusing on improvements that boost efficiency, sustainability, and overall productivity in modern agriculture.
Embrace Modern Technologies
Successful farming today demands more than just traditional knowledge and practices. Modern technologies are crucial in boosting productivity, efficiency, and profitability. Artificial Intelligence (AI) and machine learning are now widely used to analyze soil health, predict weather patterns more accurately, and optimize crop yields. Additionally, drones provide detailed aerial views of fields, enabling farmers to monitor crop health and detect potential issues early on. These innovations are helping farmers make more informed decisions, reduce waste, and improve overall farm management.
Prioritize Sustainable Practices
Sustainability will no longer be a trend—it will be a crucial component of successful farming. Implementing sustainable practices, such as organic farming or permaculture, can help minimize environmental impact while enhancing the quality and marketability of your produce.
For instance, regenerative agriculture continues to gain traction as it improves soil health, increases biodiversity, and promotes carbon sequestration, all while maintaining or even increasing crop yields. Additionally, consumers in 2024 are more conscious than ever about where their food comes from and how it’s produced, making your commitment to sustainability a significant advantage in attracting environmentally aware customers and standing out in the marketplace.
Focus on Soil Health
The health of your soil remains the foundation of successful farming. Regular soil testing is essential for understanding its composition, nutrient levels, and pH, allowing you to tailor your fertilization and soil management strategies effectively. Practices like covering crops, compost, and crop rotation can further enhance soil fertility and structure, promoting healthier plants and improved harvests. With modern techniques and sustainable practices, farmers can maintain robust soil health, ensuring long-term productivity and resilience.
Understand and Adapt to Market Trends
Understanding and adapting to market trends is essential for successful farming. Staying attuned to consumer demand and being flexible in crop selection can help you capitalize on changing preferences. Diversifying your crops, especially by focusing on high-demand, specialty crops, can offer lucrative opportunities to boost your farm’s profitability.
Additionally, exploring direct-to-consumer sales methods, such as community-supported agriculture (CSA) programs, online sales platforms, or farmers’ markets, can yield higher profits than traditional wholesale channels. These approaches also foster stronger relationships with consumers who value fresh, locally sourced produce.
Develop Strong Relationships Within Your Community
Staying ahead in farming requires a keen understanding of evolving market trends. Keeping up with consumer preferences, such as the increasing demand for organic, locally sourced, and sustainable products, is essential. Adapting your farming practices to meet these trends can help you stay competitive and attract a more extensive customer base.
Successful farming in 2024 is also about building and maintaining strong relationships within your local community. Partnering with local businesses, restaurants, and farmers’ markets or hosting events like farm tours, workshops, or community gatherings can increase your farm’s visibility and strengthen ties with local consumers. These efforts help generate additional revenue and create a loyal customer base, supporting long-term success through community engagement and trust-building.
Invest in Continuous Learning and Training
The farming landscape is rapidly evolving, and staying competitive requires a commitment to ongoing education. Engaging in continuous learning by attending industry conferences, participating in webinars, staying updated on the latest research, and joining farming networks or associations is essential. As technology and farming practices advance, staying informed enables you to make strategic, data-driven decisions that enhance productivity, efficiency, and sustainability in your farming operations. Embracing lifelong learning will keep you ahead of the curve and better prepared to tackle the challenges of modern agriculture.
Conclusion
Farming in 2024 and beyond will be defined by rapid technological advancements, a heightened focus on sustainability, and increasingly discerning consumers. By embracing these evolving trends and prioritizing core elements like soil health, market adaptability, community engagement, and continuous learning, you can ensure your farming operations’ long-term success and resilience.
Successful farming today is not just about working hard—it’s about working smart. By incorporating these strategies, staying flexible, and adapting to the latest innovations, your farm will thrive in the years ahead.
As the world continues to experience unprecedented technological advancements, one domain that has seen impressive strides is agriculture. More precisely, the integration of generative AI in agriculture has unlocked new avenues for growth in agri-tech, promising a future of smarter, more efficient farming. In this article, we will explore how generative AI drives growth in agri-tech and what it holds for the future of agriculture.
Generative AI in Agriculture: A Revolution in the Making
Generative AI, a branch of artificial intelligence, involves algorithms that use data to generate something new. This could mean creating models to predict crop yield, optimize irrigation, or determine the most suitable crop varieties for specific agricultural conditions. By leveraging generative AI in agriculture, we can make farming more efficient, productive, and sustainable.
Driving Agri-Tech Growth: The Role of Generative AI
The introduction of generative AI in agriculture has led to significant improvements and growth in the agri-tech sector. Let’s dive into how it does so.
Predictive Analytics: Generative AI models can learn from vast datasets, including weather patterns, soil conditions, and crop health data, to predict future outcomes accurately. These insights can help farmers make informed decisions, leading to increased crop yields and profitability.
Precision Agriculture: Precision farming, made possible through generative AI, allows farmers to manage their fields on a micro-scale, maximizing efficiency and reducing waste. This approach can lead to cost savings, improved yields, and minimal environmental impact.
Supply Chain Optimization: Generative AI in agriculture isn’t confined to the fields. It also optimizes supply chains, creating models that predict demand and supply, helping reduce wastage and improving market responsiveness.
Crop Breeding: One of the most exciting applications of generative AI in agriculture is crop breeding. AI algorithms can predict the genetic combinations that would result in desired crop traits, accelerating the breeding process and ultimately leading to more resilient, high-yielding crop varieties.
Generative AI: Shaping the Future of Agri-tech
Integrating generative AI in agriculture opens up possibilities for the agri-tech sector. By harnessing AI’s power, we can develop more effective strategies to tackle significant agricultural challenges like climate change, population growth, and food security.
Moreover, we can expect even more sophisticated solutions as AI technology evolves. We could see AI systems that autonomously manage entire farms, from sowing to harvesting, drastically reducing the need for manual labor and increasing efficiency.
To conclude, generative AI in agriculture has tremendous potential to drive growth in agri-tech, revolutionizing how we approach farming. By embracing this technology, we can work towards a more productive, sustainable, and resilient agricultural sector that can cater to our planet’s growing needs.
Key Takeaways:
Generative AI in agriculture is revolutionizing the agri-tech sector, enabling predictive analytics, precision farming, supply chain optimization, and advanced crop breeding.
The use of generative AI in agriculture has the potential to increase crop yields, profitability, and sustainability in the farming sector.
The future of agri-tech lies in the further integration of generative AI, with possibilities ranging from autonomous farm management to more advanced crop breeding.
In the face of the ongoing climate change crisis, the need to adopt sustainable practices has never been more critical. One such transformative approach is climate-smart agriculture (CSA). This piece provides a comprehensive overview of practicing climate-smart agriculture, its importance, benefits, and how we can adopt it to secure a sustainable future.
Climate-Smart Agriculture: An Essential Solution for a Sustainable Future
Climate-smart agriculture is a holistic approach to crop cultivation that offers a potent response to the global climate crisis. It focuses on developing and implementing agricultural techniques and practices that support farmers in enhancing agricultural productivity, boosting resilience to climate change, and reducing greenhouse gas emissions. With the growing awareness of environmental concerns, embracing climate-smart agriculture practices becomes imperative for a sustainable future.
Why Climate-Smart Agriculture?
Understanding the value and impact of climate-smart agriculture is essential in today’s agricultural context. Climate change poses significant challenges to agricultural productivity and food security worldwide. Droughts, floods, heatwaves, and changing rainfall patterns are all tangible effects of climate change that can adversely impact agriculture. Therefore, adopting climate-smart agriculture practices helps farmers better adapt to these changing conditions, improve farm yields, and ensure food security.
Practicing Climate-Smart Agriculture: The Benefits
Climate-smart agriculture offers numerous benefits, making it an indispensable tool in the battle against climate change. CSA can dramatically improve agricultural productivity and farmers’ livelihoods by integrating efficient water usage, crop rotation, agroforestry, and precision farming.
Moreover, climate-smart agriculture practices can mitigate climate change by reducing greenhouse gas emissions. Techniques like conservation agriculture and agroecology can enhance soil health and carbon sequestration, thus lowering the agricultural sector’s carbon footprint.
Adopting Climate-Smart Agriculture: A Step Towards a Greener Tomorrow
Practicing climate-smart agriculture requires a shift in conventional farming methods and an understanding of the local environmental context. Initiating the transition towards CSA involves assessing local climate risks, identifying suitable CSA practices, and providing farmers with the necessary training and resources.
Furthermore, incorporating technology in climate-smart agriculture can be a game-changer. From advanced weather forecasting to precision farming tools, technology can play a pivotal role in optimizing the implementation of CSA practices.
Climate-Smart Agriculture: A Way Forward
As we navigate through the 21st century, climate-smart agriculture must become more than a buzzword. It should evolve into a standard practice for farmers worldwide, ensuring both food security and environmental sustainability. By doing so, we can create a resilient agricultural sector capable of withstanding the threats posed by climate change while also securing a sustainable future for generations to come.
Adopting climate-smart agriculture is not just about survival; it’s about thriving in a changing world. Let’s embrace CSA as our way forward for the sake of our planet, our food, and our future.
Key Takeaways:
Climate-smart agriculture practices can help mitigate the effects of climate change by improving agricultural productivity, enhancing resilience, and reducing greenhouse gas emissions.
Adopting climate-smart agriculture can ensure food security and environmental sustainability, making it a necessary strategy for the future.
The successful implementation of climate-smart agriculture involves assessing local climate risks, educating farmers, and leveraging technological advancements.
The evolution of agriculture continues to break barriers with the incorporation of Geographical Information System (GIS) and Global Positioning System (GPS). These technologies are opening a new realm of possibilities, especially when it comes to enhancing efficiency, productivity, and sustainability in farming practices. It’s high time we took a closer look at “GIS for agriculture” and “GPS in agriculture”.
Unraveling the Power of GIS for Agriculture
In a nutshell, a Geographical Information System (GIS) is a powerful tool that allows users to visualize, analyze, and interpret data to understand relationships, patterns, and trends. In the context of agriculture, GIS provides significant benefits, and here’s how.
Precision Agriculture
One of the most compelling applications of GIS for agriculture is precision farming. GIS technology allows farmers to create detailed field maps, enabling them to understand the variability within their fields. They can analyze a wide range of data, such as soil composition, moisture levels, and crop yield, to make informed decisions about fertilizer application, irrigation, and planting strategies. This precision approach helps maximize yield while minimizing costs and environmental impact.
Crop Monitoring and Management
Another vital application of GIS in agriculture is crop monitoring and management. GIS tools can integrate data from various sources, including drones and satellites, to provide real-time monitoring of crop health and growth. Farmers can quickly identify issues like pest infestations, diseases, or water stress, enabling them to take timely action and minimize crop losses.
Harnessing GPS in Agriculture
GPS, or Global Positioning System, is a satellite-based system that provides location and time information in all weather conditions. When applied in agriculture, GPS can significantly enhance farming operations and offer numerous benefits.
Machine Guidance
GPS technology is a game-changer when it comes to improving the efficiency of farming machinery. GPS-guided tractors and equipment can work in all conditions, day or night, with precision accuracy. This capability reduces overlapping and missed areas, saving time, fuel, and inputs, while reducing soil compaction.
Yield Mapping
GPS in agriculture is instrumental in the creation of yield maps. These maps provide a visual representation of crop yield across different areas of a field. By analyzing this data, farmers can better understand the factors affecting yield, such as soil quality, moisture, and pest infestations, allowing them to develop more effective farming strategies.
In conclusion, the integration of GIS and GPS in agriculture marks a significant leap towards smarter, more sustainable farming. By enabling precise, data-driven decision-making, these technologies help farmers maximize yield, reduce costs, and minimize environmental impact. As we move forward, GIS for agriculture and GPS in agriculture will undoubtedly continue to play an integral role in shaping the future of farming.
Embrace the new age of precision farming with the power of GIS and GPS. Experience the future of agriculture today.
We use cookies to give you the best experience on our website. By continuing to use this site, or by clicking "Accept," you consent to the use of cookies. Privacy PolicyAccept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Error: Contact form not found.
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
Download the Case study
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
Webinar
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
Get your FREE Copy
We value your privacy. We don’t share your details with any third party
Get your FREE Copy
We value your privacy. We don’t share your details with any third party
Get your FREE Copy
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
Download our E-book
We value your privacy. We don’t share your details with any third party
HAPPY READING
We value your privacy. We don’t share your details with any third party
SEND A RFP
HAPPY READING
We value your privacy. We don’t share your details with any third party
 1-800-805-5783
1-800-805-5783 GET A QUOTE
GET A QUOTE