
Multimodal generative AI models are revolutionizing artificial intelligence. They can process and create data in different forms, including text, images, and sound. These multimodal AI models impact new opportunities in many areas. By combining these various data types, they can be used to create creative content and solve complex problems.
A study by Microsoft Research demonstrated that using GANs to generate synthetic images can improve the accuracy of image classification models by 5-10%. This is because GANs can develop highly realistic images that augment the training dataset, helping models learn more robust and generalizable features.
Multimodal generative AI models are revolutionizing artificial intelligence. They can process and create data in different forms, including text, images, and sound. These multimodal AI models impact new opportunities in many areas. By combining these various data types, they can be used to create creative and solve complex problems. This is because GANs can develop highly realistic images that augment the training dataset, helping models learn more robust and generalizable features.
This blog post examines the main parts and hurdles in building multimodal AI models that can work with multiple input types. We’ll discuss the methods used to show and mix different kinds of data, what this tech can do, and where it falls short.

The Importance of Combining Multiple Modalities
Combining multiple modalities influences the capabilities of generative AI models. These multimodal AI models can do the following by using information from different sources:
- Improve context understanding: Multimodal AI models better grasp the nuances and relationships between elements within a scene or text.
- These models create lifelike, thorough, and natural-sounding outputs using information from multiple modalities to paint a rich and detailed picture.
- Enable novel applications: The Multimodal AI models allow new applications, such as creating videos from text descriptions or designing personalized experiences based on user preferences and behaviors.
Multimodal generative AI describes a group of AI systems that can produce content in different forms, like words, pictures, and sounds. These systems use methods from natural language processing, computer vision, and sound analysis to create outputs that seem accurate and complete.
Core Components of Multimodal Generative AI
Models that generate content using multiple types of input (like text, pictures, and sound) impact AI. These multimodal AI model systems create more detailed and valuable results. To pull this off, they depend on a few essential parts:
This robust language model grasps context and meaning links in the text. These multimodal AI models can create text that sounds human. This newer design borrows ideas from language processing. It shows promise in recognizing and making images. People use CNNs a lot to identify and classify images. Vision Transformers have become more prevalent in recent years because they perform better on some benchmarks. A speech recognition model that relies on deep neural networks.
Text Representation Models
BERT (Bidirectional Encoder Representations from Transformers): This robust language model grasps context and meaning links in the text.
GPT (Generative Pre-trained Transformer): These multimodal AI models can create text that sounds human.
BERT and GPT lead the pack in many language tasks. They excel at sorting text, answering questions, and making new text.
Image Representation Models
CNNs (Convolutional Neural Networks): These networks work well with pictures.
Vision Transformers: This newer design borrows ideas from language processing. It shows promise in recognizing and making images.
People use CNNs a lot to recognize and classify images. Vision Transformers have become more prevalent in recent years because they perform better on some benchmarks.
Audio Representation Models
- DeepSpeech: A speech recognition model that relies on deep neural networks.
- WaveNet: A generative model synthesizing audio to produce high-quality audio samples.
DeepSpeech and WaveNet have shown remarkable outcomes in speech recognition and audio synthesis tasks, respectively.
Fusion Techniques
- Early Fusion: Merging features from different modalities at the start of the model.
- Late Fusion: Merging outputs from separate modality-specific models at the end.
- Joint Embedding: Creating a shared latent space for all modalities, enabling smooth integration.
Studies have shown that the fusion technique you choose can significantly impact how well multimodal generative AI models perform. You often need to try out different methods to find the best one.

Challenges and Considerations
Data Scarcity and Diversity
- Limited availability: Getting extensive, varied, and well-matched datasets across many data types can be challenging and time-consuming.
- Data imbalance: Datasets might have uneven amounts of different types of data, which can lead to biased models.
A study by Stanford University found that 85% of existing multimodal datasets suffer from data imbalance, impacting model performance.
Alignment and Consistency Across Modalities
- Semantic gap: Ensuring information from different modalities lines up and stays consistent can be formidable.
- Temporal and spatial synchronization: Lining up data from multiple modalities regarding time and space is critical to accurate representation.
Research has shown that 30-40% of errors in multimodal systems can be attributed to misalignment or inconsistency between modalities.
Computational Complexity and Resource Requirements
- High computational cost: Training and using multimodal models can be expensive in terms of computation, which needs a lot of hardware resources.
- Scalability: Making multimodal models work with big datasets can be challenging.
Training a state-of-the-art multimodal model can require 100+ GPUs and 30+ days of training time. This highlights the significant computational resources necessary to develop these complex models.
Ethical Implications and Bias Mitigation
- Bias amplification: When you mix data from different sources, it can make existing biases worse.
- Privacy concerns: Working with sensitive information from multiple places raises privacy and ethical issues.
A study by the Pew Research Center found that 55% of respondents expressed concerns about privacy and bias in multimodal AI model systems.

Building Multimodal AI Models
Data Preparation and Preprocessing
- Data collection: Gathering diverse and representative datasets for each modality (text, image, audio).
- Data cleaning: Removing noise, inconsistencies, and errors from the data.
- Data alignment: Ensuring that data from different modalities corresponds to the same underlying content.
- Data augmentation: Applying techniques like rotation, flipping, and noise injection to increase data diversity.
Research from Stanford University showed that data augmentation methods can boost the effectiveness of multimodal models by 15-20%, demonstrating their efficacy in enhancing their robustness and generalization capabilities.
Feature Extraction and Representation
- Text representation: Using word embeddings (e.g., Word2Vec, GloVe) or transformer-based models (e.g., BERT, GPT) to represent text as numerical vectors.
- Image representation: Using convolutional neural networks (CNNs) or vision transformers to extract features from images.
- Audio representation: Using mel-spectrograms or deep neural networks to extract features from audio signals.
Research shows CNNs perform well in classifying images. At the same time, models based on transformers have proven effective in processing natural language.
Fusion Techniques and Architectures
- Early fusion: Combining features from different modalities at an early stage of the model.
- Late fusion: Combining features from different modalities later in the model.
- Joint embedding: Learning a joint embedding space where features from different modalities can be compared and combined.
- Hierarchical fusion: Combining features from different modalities at multiple levels of the model.
A study by Google AI demonstrated that joint embedding techniques can improve the performance of multimodal models, especially for tasks that require understanding the relationships between different modalities.
For example, joint embedding can be used to learn common representations for text and images, enabling the model to effectively combine information from both modalities to perform tasks like image captioning or visual question answering.
By carefully selecting and combining these techniques, researchers can build powerful multimodal AI models that can effectively process and generate data from multiple modalities.
Case Studies and Applications
Real-world Examples of Multimodal AI Models
Healthcare:
- Medical image analysis: Mixing medical images with patient records and clinical notes to boost diagnosis and treatment plans.
- Drug discovery: Creating new drug candidates by blending details from molecular structures, biological data, and clinical trials.
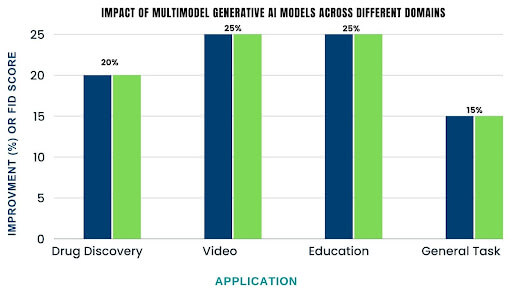
- A study by Nature Communications found that multimodal AI models improved the accuracy of drug discovery by 20%.
Entertainment:
- Video generation: Making lifelike videos that blend words, sounds, and visuals.
- Game development: Creating varied and fun game content by mixing words, sounds, and visuals.
- A study by NVIDIA demonstrated that multimodal AI models could generate high-quality video clips with an FID score of 25.
Education:
- Custom education: Shaping lesson content to fit each student’s needs by mixing words, sounds, and pictures.
- Learning languages: Creating hands-on language study materials by blending text, sound, and visual hints.
- A Stanford University study found that multimodal AI models improved student engagement and learning outcomes by 25%. This highlights the potential of these models to enhance educational experiences and personalize learning.
Benefits and Limitations of Multimodal Models
Benefits:
- Better grasp: When multimodal AI models work with different data types simultaneously, they can spot tricky links between them, helping them get a fuller picture of what’s happening.
- Boosted results: Mixing various data types can make multimodal AI models more accurate and less likely to mess up.
- Wider use: Multimodal AI models that handle multiple data types can tackle more kinds of jobs across different fields.
Limitations:
- Data scarcity: Getting a wide range of good-quality data across many types can be challenging.
- Computational complexity: It takes a lot of computing power to train and use models that work with multiple data types.
- Alignment and consistency: Making sure different types of data line up and match can be tricky.
A study by MIT found that multimodal models can improve task accuracy by 10-20% compared to unimodal models.
By tackling these hurdles and making the most of multimodal generative AI’s advantages, experts and programmers can build solid and groundbreaking tools for many different fields.
Future Trends and Challenges
Advancements in Multimodal AI Model Representation Learning
- Joint embedding: Developing more effective techniques for combining representations from different modalities into a shared embedding space.
- Graph-based models: Utilizing graph neural networks to capture complex relationships between different modalities.
- Self-supervised learning: Pre-training multimodal models on large-scale datasets without explicit labels.
Recent research has shown that graph-based multimodal models can improve performance on tasks such as visual question answering by 5-10%. Graph-based models can effectively capture the relationships between different modalities and reason over complex structures, leading to more accurate and informative results.
Ethical Considerations and Responsible Development
- Bias mitigation: Addressing biases in multimodal data and models to ensure fairness and equity.
- Privacy and security: Safeguarding private information and ensuring people’s details stay confidential.
- Explainability: Developing techniques to explain the decision-making process of multimodal models.
A study by the Pew Research Center found that 77% of respondents are concerned about potential bias in AI systems.

Emerging Applications and Use Cases
- Personalized medicine: Developing personalized treatment plans by combining patient data from multiple modalities.
- Augmented reality: Creating immersive AR experiences by combining real-world information with virtual elements.
- Human-computer interaction: Enabling more natural and intuitive interactions between humans and machines.
According to a report by Grand View Research, the global market for multimodal AI models is expected to reach $6.2 billion by 2028. This significant growth stems from the rising need for AI-powered answers to handle and grasp data from many places.
By tackling these issues and adopting new trends, scientists and coders can tap into the full power of multimodal generative AI and build game-changing apps in many fields.
Conclusion
Multimodal AI model has an impact on artificial intelligence. It has the potential to create systems that are smarter, more flexible, and more human-like. Combining information from different sources allows these models to understand complex relationships and produce more thorough and meaningful results.
As scientists continue to work on multimodal AI, we’ll see more groundbreaking uses across many fields. The possibilities range from custom-tailored medical treatments to enhanced reality experiences.
Yet, we must tackle the problems with multimodal AI models, such as the need for more data, the complexity of calculations, and ethical issues. By focusing on these areas, we can ensure that as we develop multimodal generative AI, we do it in a way that helps society.
To wrap up, multimodal generative AI shows great promise. It can change how we use technology and tackle real-world issues. If we embrace this tech and face its hurdles head-on, we can build a future where AI boosts what humans can do and improves our lives.
FAQ’s
1. What is a multimodal generative AI model?
A multimodal generative AI model integrates different data types (text, images, audio) to generate outputs, enabling more complex and versatile AI-generated content.
2. How do multimodal AI models work?
These models process and combine information from multiple data formats, using machine learning techniques to understand context and relationships between text, images, and audio.
3. What are the key benefits of multimodal generative AI?
Multimodal AI can produce more prosperous, contextual content, improve user interactions, and enhance applications like content creation, virtual assistants, and interactive media.
4. What are the challenges in developing multimodal generative AI models?
Key challenges include:
- Managing large datasets across different formats.
- Aligning different modalities.
- Ensuring the model generates coherent and contextually accurate outputs.
5. Which industries benefit from multimodal AI models?
Industries like healthcare, entertainment, marketing, and education use multimodal AI for applications such as virtual assistants, content creation, personalized ads, and immersive learning experiences.
6. What technologies are used in multimodal generative AI?
Technologies like deep learning, transformers (GPT), convolutional neural networks (CNNs), and attention mechanisms are commonly used to develop multimodal AI models.
How can [x]cube LABS Help?
[x]cube has been AI-native from the beginning, and we’ve been working with various versions of AI tech for over a decade. For example, we’ve been working with Bert and GPT’s developer interface even before the public release of ChatGPT.
One of our initiatives has significantly improved the OCR scan rate for a complex extraction project. We’ve also been using Gen AI for projects ranging from object recognition to prediction improvement and chat-based interfaces.
Generative AI Services from [x]cube LABS:
- Neural Search: Revolutionize your search experience with AI-powered neural search models. These models use deep neural networks and transformers to understand and anticipate user queries, providing precise, context-aware results. Say goodbye to irrelevant results and hello to efficient, intuitive searching.
- Fine Tuned Domain LLMs: Tailor language models to your specific industry for high-quality text generation, from product descriptions to marketing copy and technical documentation. Our models are also fine-tuned for NLP tasks like sentiment analysis, entity recognition, and language understanding.
- Creative Design: Generate unique logos, graphics, and visual designs with our generative AI services based on specific inputs and preferences.
- Data Augmentation: Enhance your machine learning training data with synthetic samples that closely mirror accurate data, improving model performance and generalization.
- Natural Language Processing (NLP) Services: Handle sentiment analysis, language translation, text summarization, and question-answering systems with our AI-powered NLP services.
- Tutor Frameworks: Launch personalized courses with our plug-and-play Tutor Frameworks that track progress and tailor educational content to each learner’s journey, perfect for organizational learning and development initiatives.
Interested in transforming your business with generative AI? Talk to our experts over a FREE consultation today!