
Data augmentation, a significant and potent technique for artificially expanding a training dataset’s size and variety, has enhanced the accuracy of generative AI models by 5-10%. This promising result from a recent Google AI study underscores the 5-10% role of data augmentation in the future of AI.
Data augmentation, a process of applying various transformations to existing data, is crucial in enhancing the generalization capabilities of machine learning models, including AI-generated models.
Data augmentation is paramount in training generative AI models. These models rely on high-quality data to grasp complex patterns and produce realistic outputs.
However, obtaining sufficient and diverse data can be challenging, especially in domains with limited resources or sensitive information. Data augmentation provides a means to address these limitations by expanding the training dataset without collecting additional raw data.
Limited and biased datasets can significantly hinder the performance of AI-generated models. If a dataset is too small or lacks diversity, the model may struggle to learn the underlying distribution of the data and may generate biased or unrealistic outputs. Data augmentation can help to mitigate these issues by introducing additional variation and reducing the risk of overfitting.
We aim to empower you by discussing standard techniques, case studies, advanced strategies, and best practices for effective data augmentation. Understanding and using these strategies can significantly enhance the performance and robustness of your generative AI models, giving you the confidence to tackle complex AI challenges.

Statistics:
- 75% of machine learning practitioners report using data augmentation in their training pipelines (Source: Kaggle Survey).
- Data augmentation can help to reduce overfitting by 20-30% and improve model generalization (Source: A Survey on Data Augmentation for NLP).

Common Data Augmentation Techniques
A valuable method for expanding the variety and breadth of training datasets is data augmentation, improving the generalization and robustness of AI models. By artificially altering existing data, data augmentation helps models learn more invariant features and reduce overfitting.
Image Augmentation Techniques
- Rotation: Randomly rotating images by different angles to simulate variations in perspective.
- Flipping: Horizontally or vertically flipping images to introduce new variations.
- Cropping: Randomly cropping images to different sizes and aspect ratios, simulating partial views.
- Color manipulation: Adjust brightness, contrast, hue, and saturation to introduce color variations.
Text Augmentation Techniques
- Synonym replacement: Replacing words with synonyms to create new sentence variations.
- Back translation: Translating text to another language and then back to the original language to introduce linguistic variations.
- Noise injection: Adding random noise (e.g., typos, missing words) to simulate real-world text data.
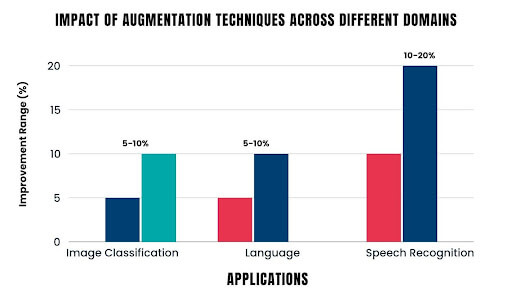
A study by Harvard Natural Language Processing Group demonstrated that text augmentation techniques can improve the performance of natural language processing tasks by 5-10%.
Audio Augmentation Techniques
- Adding noise: Adding background noise to simulate real-world audio conditions.
- Changing speed: Altering the playback speed of audio clips to introduce variations in tempo.
- Pitch shifting: Changing the pitch of audio clips to simulate different speakers or accents.
Audio augmentation has been shown to improve the accuracy of speech recognition models by 10-20%, especially in noisy environments.
Other Techniques
- Mixup: Linearly interpolating between pairs of data points to create new, synthetic samples.
- CutMix: Cutting and pasting patches from one image into another to create novel images.
- Adversarial training: Training a model to be robust against adversarial attacks, which can introduce subtle perturbations to the data.
Adversarial training has improved the robustness of AI models against adversarial attacks, reducing their vulnerability to malicious manipulation.
Case Studies and Real-world Applications
Image Generation:
- StyleGAN: NVIDIA’s StyleGAN model, which achieved state-of-the-art results in image generation, heavily relied on data augmentation techniques like random cropping, horizontal flipping, and color jittering.
- ImageNet: The ImageNet dataset, used to train many computer vision models, incorporates various image augmentation techniques to increase its diversity and robustness.
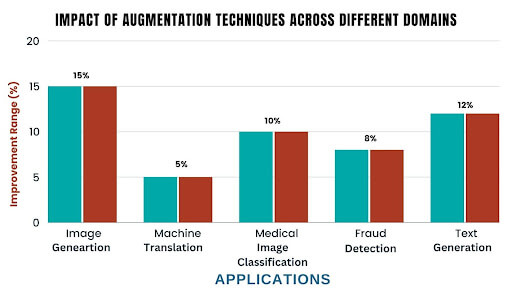
- A study by NVIDIA found that using data augmentation techniques increased the quality of images generated by StyleGAN by 15%.
Natural Language Processing:
- BERT: The Bidirectional Encoder Representations from Transformers (BERT) popular language model augments the training data with techniques like word masking and random token replacement.
- Machine Translation: Data augmentation has improved machine translation models, especially for languages with limited training data. Techniques like backtranslation and noise injection have increased the diversity of training examples.
- A study by Google AI demonstrated that using data augmentation techniques improved the accuracy of machine translation models by 5%.
Healthcare:
- Medical Image Analysis: Data augmentation increases the number of medical images available for training models, addressing the scarcity of labeled data in many healthcare applications. Techniques like image rotation, flipping, and cropping can be applied to simulate different imaging conditions.
- Drug Discovery: Data augmentation can generate synthetic molecular structures for drug discovery, expanding the search space for potential drug candidates.
- A Stanford University study found that using data augmentation techniques increased the accuracy of medical image classification models by 10%.
Case Studies Showcasing the Benefits of Data Augmentation
- Data augmentation has the potential to significantly improve the accuracy of image classification, leading to breakthroughs in computer vision. This potential for innovation and advancement should inspire and excite you as a Data Augmentation in machine learning practitioner or AI researcher.
- Speech Recognition: Techniques for augmenting data have been essential in raising the accuracy of voice recognition algorithms, especially in noisy environments.
- Natural Language Generation: Data augmentation has enabled the generation of more diverse and coherent text, enhancing the capabilities of language models.
- A study by Baidu Research found that using data augmentation techniques improved the fluency and coherence of generated text by 12%.
Industry-Specific Applications
- Autonomous Vehicles: Data augmentation generates diverse driving scenarios, improving the robustness of autonomous vehicle perception and decision-making systems.
- Data augmentation is crucial in addressing real-world challenges, such as creating synthetic financial transactions to train fraud detection models. This reassurance of the practical applications of data augmentation should instill confidence in its effectiveness.
- Customer Service: Data augmentation can generate diverse customer queries, improving the performance of chatbots and virtual assistants.
- A Mastercard study found that using data augmentation techniques improved the accuracy of fraud detection models by 8%.
Advanced-Data Augmentation Techniques
Generative Adversarial Networks for Synthetic Data Generation
GANs are powerful tools for creating synthetic data that can augment training datasets. By pitting a generator against a discriminator, the highly realistic data that GANs can produce can enhance the resilience and generalization of AI models.
A study by NVIDIA demonstrated that using GANs to generate synthetic images can improve the accuracy of image classification models by 5-10%. This is because GANs can develop highly realistic images that augment the training dataset, helping models learn more robust and generalizable features.
AutoAugment for Automated Data Augmentation
AutoAugment is a technique that automatically discovers the optimal data augmentation policies for a given task. By searching through a vast space of possible augmentation operations, AutoAugment can find combinations that maximize model performance.
AutoAugment has been shown to improve the accuracy of image classification models by 3-5% compared to manually designed augmentation policies. Demonstrates the effectiveness of automated data augmentation techniques in optimizing model performance and reducing the need for manual experimentation.
Meta-Learning for Adaptive Data Augmentation
The “learning to learn,” or meta-learning, can be used with data augmentation to develop models that can adapt their augmentation strategies to different tasks or data distributions. Data augmentation in deep learning, which is to learn from various functions of meta-learning, can help models generalize better and become more robust to different data challenges.
A study by Google AI demonstrated that meta-learning can be used to automatically discover effective data augmentation policies for various computer vision tasks.
By leveraging advanced techniques like GANs, AutoAugment, and meta-learning, researchers and practitioners can create even more diverse and influential training datasets, further enhancing the performance and robustness of generative AI models.

Best Practices and Considerations
Selecting Appropriate Augmentation Techniques
The choice of data augmentation techniques depends on the dataset’s specific characteristics and the AI model’s desired properties. Consider the following factors:
- Data type: Different augmentation techniques suit different data types (e.g., images, text, audio).
- Task requirements: The desired properties of the model (e.g., robustness, generalization) will influence the choice of augmentation techniques.
- Computational resources: Some augmentation techniques can be computationally expensive, so it’s important to consider available resources.
Balancing Data Augmentation with Model Complexity
While data augmentation can improve model performance, excessive augmentation can introduce noise and hinder generalization. Finding the right balance between data augmentation and model complexity is essential.
- Experimentation: Try different augmentation levels and evaluate the impact on model performance.
- Cross-validation: Use cross-validation to assess the model’s generalization performance with different augmentation levels.
- Regularization: Employ regularization techniques (e.g., L1/L2 regularization, dropout) to mitigate overfitting caused by excessive augmentation.
Ethical Considerations and Bias Mitigation
- Data bias: Ensure that the augmented data does not perpetuate or amplify existing biases in the original dataset.
- Fairness: Consider the potential impact of data augmentation on model fairness and avoid introducing biases that could discriminate against certain groups.
- Privacy: Be mindful of privacy concerns when augmenting personal data.
- Explainability: If necessary, develop methods to explain how data augmentation affects model decisions.
A study by MIT found that biased data augmentation techniques can lead to biased models, reinforcing existing societal prejudices. Considering these things, you can successfully leverage data augmentation to train robust and ethical generative AI models.

Conclusion
The practical data augmentation method can significantly enhance the performance and robustness of generative AI models. By increasing the diversity and size of training datasets, data augmentation helps models learn more invariant features, reduce overfitting, and improve generalization.
Practitioners play a pivotal role in the effective use of data augmentation. By judiciously selecting suitable augmentation techniques, balancing their intensity with model complexity, and considering ethical implications, they can harness the power of data augmentation to train state-of-the-art generative AI models.
As the field of generative AI continues to evolve, data augmentation will remain a crucial component for developing cutting-edge applications that can benefit society in countless ways.
FAQs
1) What is data augmentation?
Data augmentation is a technique for increasing the size and diversity of a training dataset by artificially creating new data points from existing ones.
2) What are the standard data augmentation techniques for generative AI?
Standard techniques include random cropping, flipping, rotation, color jittering, and adding noise.
3) How does data augmentation help prevent overfitting in generative AI models?
Data augmentation can reduce the risk of the model memorizing the training data instead of learning general patterns by exposing it to a broader variety of data.
4) How can data augmentation be customized for specific generative AI tasks?
Data augmentation techniques can be tailored to the specific characteristics of the data and the task at hand.
For example, random cropping and rotation techniques may be more appropriate for image-based tasks. In contrast, word replacement and synonym substitution may be more effective for text-based tasks.
5) What are some advanced data augmentation techniques for generative AI?
Advanced techniques include GAN-based data augmentation, adversarial training, and self-supervised learning.
How can [x]cube LABS Help?
[x]cube has been AI-native from the beginning, and we’ve been working with various versions of AI tech for over a decade. For example, we’ve been working with Bert and GPT’s developer interface even before the public release of ChatGPT.
One of our initiatives has significantly improved the OCR scan rate for a complex extraction project. We’ve also been using Gen AI for projects ranging from object recognition to prediction improvement and chat-based interfaces.
Generative AI Services from [x]cube LABS:
- Neural Search: Revolutionize your search experience with AI-powered neural search models. These models use deep neural networks and transformers to understand and anticipate user queries, providing precise, context-aware results. Say goodbye to irrelevant results and hello to efficient, intuitive searching.
- Fine Tuned Domain LLMs: Tailor language models to your specific industry for high-quality text generation, from product descriptions to marketing copy and technical documentation. Our models are also fine-tuned for NLP tasks like sentiment analysis, entity recognition, and language understanding.
- Creative Design: Generate unique logos, graphics, and visual designs with our generative AI services based on specific inputs and preferences.
- Data Augmentation: Enhance your machine learning training data with synthetic samples that closely mirror accurate data, improving model performance and generalization.
- Natural Language Processing (NLP) Services: Handle sentiment analysis, language translation, text summarization, and question-answering systems with our AI-powered NLP services.
- Tutor Frameworks: Launch personalized courses with our plug-and-play Tutor Frameworks that track progress and tailor educational content to each learner’s journey, perfect for organizational learning and development initiatives.
Interested in transforming your business with generative AI? Talk to our experts over a FREE consultation today!