1-800-805-5783
1-800-805-5783  GET A QUOTE
GET A QUOTE
![Blog-[x]cube LABS](https://d6fiz9tmzg8gn.cloudfront.net/wp-content/uploads/2016/06/blog_banner.jpg)


By [x]cube LABS
Published: Jan 07 2021

Table of contents
It wasn’t long ago when Open AI achieved a breakthrough in AI by announcing the launch of GPT-3, a general-purpose language algorithm that uses machine learning to translate text, answer questions and predictively write text. It created quite a buzz for being the largest model trained so far and for reaching the highest stage of human-like intelligence through ML and NLP. Fasttrack six months and we learn that OpenAI extended GPT-3 with two new models that combine NLP with image recognition to give their AI a better understanding of everyday concepts.
We’ve already seen in the case of GPT-3 that a single deep-learning model could be trained to use language in a variety of ways simply by feeding it vast amounts of text, This was followed by swapping text for pixels, and using the same approach to train an AI to complete half-finished images. OpenAI has now put these ideas together to create two new models, called DALL·E and CLIP. These models combine language and images in a way that will make AIs better at understanding both words and what they refer to.
We’ve developed two neural networks which have learned by associating text and images. CLIP maps images into categories described in text, and DALL-E creates new images, like this, from text.
A step toward systems with deeper understanding of the world. https://t.co/rppy6u1zcn pic.twitter.com/MNVlo8LZbV
— OpenAI (@OpenAI) January 5, 2021
DALL.E is Open AI’s trained neural network that creates images from text captions for a wide range of concepts expressible in natural language. It is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions, using a dataset of text-image pairs. It has a diverse set of capabilities, including creating anthropomorphized versions of animals and objects, combining unrelated concepts in probable ways, rendering text, and applying transformations to existing images.
Simply put, it is a neural network that instead of recognizing images, draws them based on the text description. You can provide a short natural-language caption, such as “illustration of a baby daikon radish in a tutu walking a dog” or “ an armchair in the shape of an avocado,” and DALL·E generates lots of images that match it.
Text prompt: an illustration of a baby daikon radish in a tutu walking a dog
Output:

Source: Open AI
Text prompt: an armchair in the shape of an avocado
Output:

Source: Open AI
While the ability of DALL.E to generate synthetic images out of whimsical ideas seems promising for AI advancement, it comes with its own limitations. For example, Including too many objects in a text prompt puts its ability to keep track of what to draw, to test. Additionally, rephrasing a text prompt sometimes yields different results. There also have been signals that DALL·E is imitating images it has encountered online rather than generating original ones.
CLIP, or Contrastive Language–Image Pre-training, is a neural network that efficiently learns visual concepts from natural language supervision. It can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the “zero-shot” capabilities of GPT-2 and 3.
One may think that CLIP is just another image recognition system but there’s an exception to it. It recognizes images not from labeled examples in training data sets but from images and their captions taken from the internet. It learns about the image from a description instead of one-word labels.
CLIP’s performance was tested on ImageNet and it was found that CLIP’s performance is much more representative of how it will fare on datasets that measure accuracy in non-ImageNet settings.
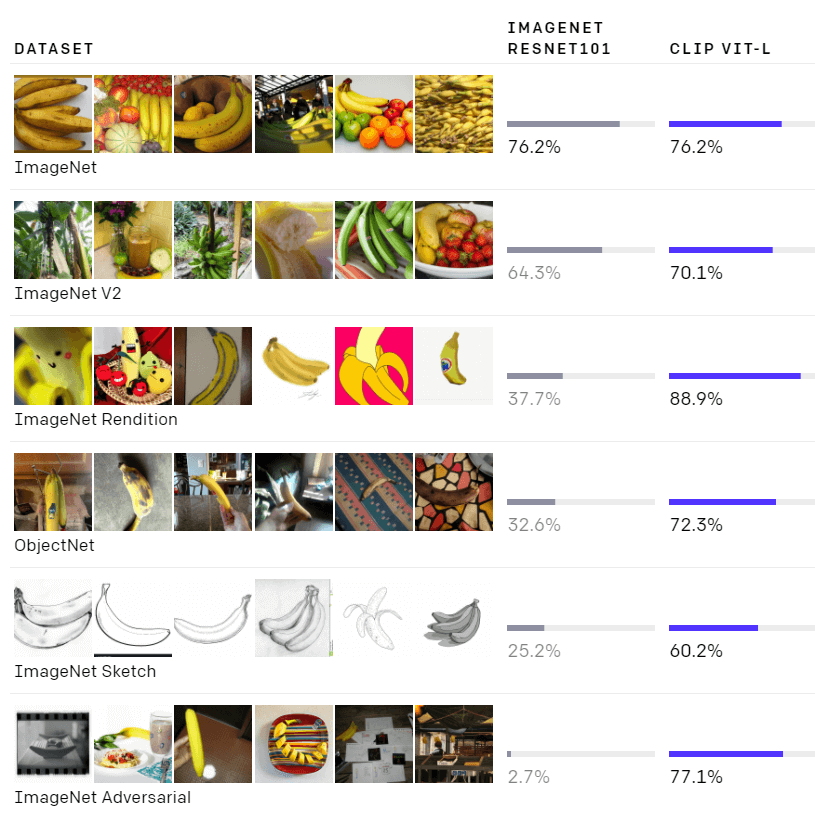
Source: Open AI
CLIP was found to struggle with more abstract or systematic tasks such as counting the number of objects in an image. It failed to complete complex tasks such as predicting how close the nearest car is in a photo as well. Quite naturally, CLIP also poorly generalizes images that were not covered in its pre-training dataset.
Despite the limitations, this is yet another groundbreaking innovation by Open AI. The OpenAI team plans to analyze how these models correlate issues like economic impact on certain professions, the potential of bias in the model outputs, as well as the long-term ethical challenges posed by this technology. With this, we have more insights into the kind of AI systems we’re likely to see in the future. At [x]cube LABS, we help our clients create breakthrough results, drive operational growth, and achieve efficiency with advanced artificial intelligence and machine learning services. If you’re looking to explore opportunities with AI for your business, feel free to get in touch with us.
Tags: AI, artificial Intelligence